 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Conversational Search via Topical Locality in Dense Retrieval
Apr 30, 2025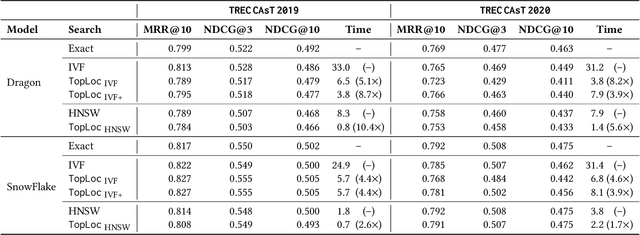
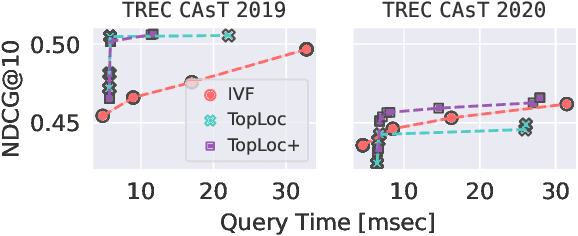
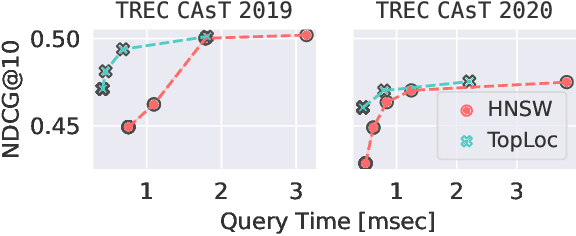
Pre-trained language models have been widely exploited to learn dense representations of documents and queries for information retrieval. While previous efforts have primarily focused on improving effectiveness and user satisfaction, response time remains a critical bottleneck of conversational search systems. To address this, we exploit the topical locality inherent in conversational queries, i.e., the tendency of queries within a conversation to focus on related topics. By leveraging query embedding similarities, we dynamically restrict the search space to semantically relevant document clusters, reducing computational complexity without compromising retrieval quality. We evaluate our approach on the TREC CAsT 2019 and 2020 datasets using multiple embedding models and vector indexes, achieving improvements in processing speed of up to 10.4X with little loss in performance (4.4X without any loss). Our results show that the proposed system effectively handles complex, multiturn queries with high precision and efficiency, offering a practical solution for real-time conversational search.
Rewriting Conversational Utterances with Instructed Large Language Models
Oct 10, 2024Many recent studies have shown the ability of large language models (LLMs) to achieve state-of-the-art performance on many NLP tasks, such as question answering, text summarization, coding, and translation. In some cases, the results provided by LLMs are on par with those of human experts. These models' most disruptive innovation is their ability to perform tasks via zero-shot or few-shot prompting. This capability has been successfully exploited to train instructed LLMs, where reinforcement learning with human feedback is used to guide the model to follow the user's requests directly. In this paper, we investigate the ability of instructed LLMs to improve conversational search effectiveness by rewriting user questions in a conversational setting. We study which prompts provide the most informative rewritten utterances that lead to the best retrieval performance. Reproducible experiments are conducted on publicly-available TREC CAST datasets. The results show that rewriting conversational utterances with instructed LLMs achieves significant improvements of up to 25.2% in MRR, 31.7% in Precision@1, 27% in NDCG@3, and 11.5% in Recall@500 over state-of-the-art techniques.
Caching Historical Embeddings in Conversational Search
Nov 25, 2022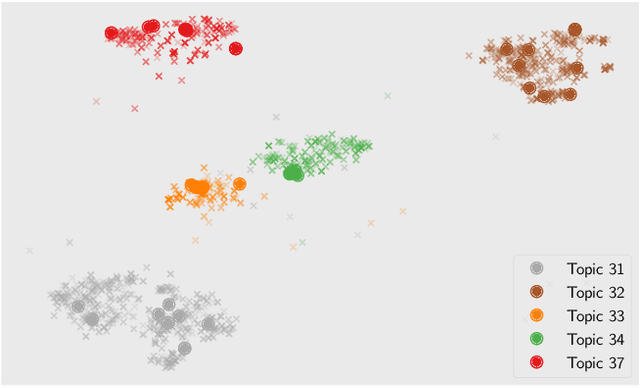
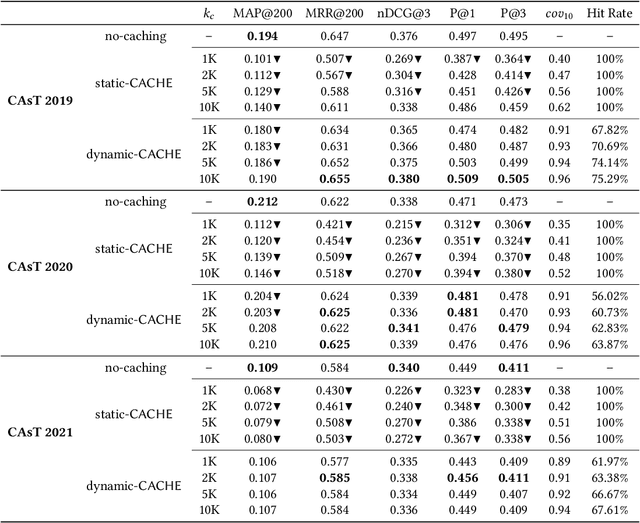
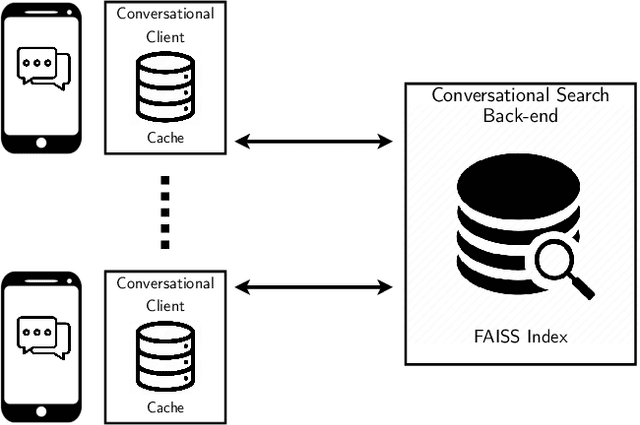
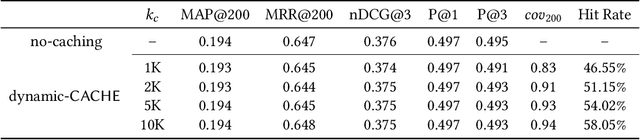
Rapid response, namely low latency, is fundamental in search applications; it is particularly so in interactive search sessions, such as those encountered in conversational settings. An observation with a potential to reduce latency asserts that conversational queries exhibit a temporal locality in the lists of documents retrieved. Motivated by this observation, we propose and evaluate a client-side document embedding cache, improving the responsiveness of conversational search systems. By leveraging state-of-the-art dense retrieval models to abstract document and query semantics, we cache the embeddings of documents retrieved for a topic introduced in the conversation, as they are likely relevant to successive queries. Our document embedding cache implements an efficient metric index, answering nearest-neighbor similarity queries by estimating the approximate result sets returned. We demonstrate the efficiency achieved using our cache via reproducible experiments based on TREC CAsT datasets, achieving a hit rate of up to 75% without degrading answer quality. Our achieved high cache hit rates significantly improve the responsiveness of conversational systems while likewise reducing the number of queries managed on the search back-end.
MICROS: Mixed-Initiative ConveRsatiOnal Systems Workshop
Jan 25, 2021The 1st edition of the workshop on Mixed-Initiative ConveRsatiOnal Systems (MICROS@ECIR2021) aims at investigating and collecting novel ideas and contributions in the field of conversational systems. Oftentimes, the users fulfill their information need using smartphones and home assistants. This has revolutionized the way users access online information, thus posing new challenges compared to traditional search and recommendation. The first edition of MICROS will have a particular focus on mixed-initiative conversational systems. Indeed, conversational systems need to be proactive, proposing not only answers but also possible interpretations for ambiguous or vague requests.