 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical Foundations of DIME: Risk Estimation for Practical Index Selection
Jan 09, 2026High-dimensional dense embeddings have become central to modern Information Retrieval, but many dimensions are noisy or redundant. Recently proposed DIME (Dimension IMportance Estimation), provides query-dependent scores to identify informative components of embeddings. DIME relies on a costly grid search to select a priori a dimensionality for all the query corpus's embeddings. Our work provides a statistically grounded criterion that directly identifies the optimal set of dimensions for each query at inference time. Experiments confirm achieving parity of effectiveness and reduces embedding size by an average of $\sim50\%$ across different models and datasets at inference time.
Early-Exit Graph Neural Networks
May 23, 2025Early-exit mechanisms allow deep neural networks to halt inference as soon as classification confidence is high enough, adaptively trading depth for confidence, and thereby cutting latency and energy on easy inputs while retaining full-depth accuracy for harder ones. Similarly, adding early exit mechanisms to Graph Neural Networks (GNNs), the go-to models for graph-structured data, allows for dynamic trading depth for confidence on simple graphs while maintaining full-depth accuracy on harder and more complex graphs to capture intricate relationships. Although early exits have proven effective across various deep learning domains, their potential within GNNs in scenarios that require deep architectures while resisting over-smoothing and over-squashing remains largely unexplored. We unlock that potential by first introducing Symmetric-Anti-Symmetric Graph Neural Networks (SAS-GNN), whose symmetry-based inductive biases mitigate these issues and yield stable intermediate representations that can be useful to allow early exiting in GNNs. Building on this backbone, we present Early-Exit Graph Neural Networks (EEGNNs), which append confidence-aware exit heads that allow on-the-fly termination of propagation based on each node or the entire graph. Experiments show that EEGNNs preserve robust performance as depth grows and deliver competitive accuracy on heterophilic and long-range benchmarks, matching attention-based and asynchronous message-passing models while substantially reducing computation and latency. We plan to release the code to reproduce our experiments.
Efficient Recommendation with Millions of Items by Dynamic Pruning of Sub-Item Embeddings
May 01, 2025A large item catalogue is a major challenge for deploying modern sequential recommender models, since it makes the memory footprint of the model large and increases inference latency. One promising approach to address this is RecJPQ, which replaces item embeddings with sub-item embeddings. However, slow inference remains problematic because finding the top highest-scored items usually requires scoring all items in the catalogue, which may not be feasible for large catalogues. By adapting dynamic pruning concepts from document retrieval, we propose the RecJPQPrune dynamic pruning algorithm to efficiently find the top highest-scored items without computing the scores of all items in the catalogue. Our RecJPQPrune algorithm is safe-up-to-rank K since it theoretically guarantees that no potentially high-scored item is excluded from the final top K recommendation list, thereby ensuring no impact on effectiveness. Our experiments on two large datasets and three recommendation models demonstrate the efficiency achievable using RecJPQPrune: for instance, on the Tmall dataset with 2.2M items, we can reduce the median model scoring time by 64 times compared to the Transformer Default baseline, and 5.3 times compared to a recent scoring approach called PQTopK. Overall, this paper demonstrates the effective and efficient inference of Transformer-based recommendation models at catalogue scales not previously reported in the literature. Indeed, our RecJPQPrune algorithm can score 2 million items in under 10 milliseconds without GPUs, and without relying on Approximate Nearest Neighbour (ANN) techniques.
Document Quality Scoring for Web Crawling
Apr 15, 2025The internet contains large amounts of low-quality content, yet users expect web search engines to deliver high-quality, relevant results. The abundant presence of low-quality pages can negatively impact retrieval and crawling processes by wasting resources on these documents. Therefore, search engines can greatly benefit from techniques that leverage efficient quality estimation methods to mitigate these negative impacts. Quality scoring methods for web pages are useful for many processes typical for web search systems, including static index pruning, index tiering, and crawling. Building on work by Chang et al.~\cite{chang2024neural}, who proposed using neural estimators of semantic quality for static index pruning, we extend their approach and apply their neural quality scorers to assess the semantic quality of web pages in crawling prioritisation tasks. In our experimental analysis, we found that prioritising semantically high-quality pages over low-quality ones can improve downstream search effectiveness. Our software contribution consists of a Docker container that computes an effective quality score for a given web page, allowing the quality scorer to be easily included and used in other components of web search systems.
MURR: Model Updating with Regularized Replay for Searching a Document Stream
Apr 14, 2025The Internet produces a continuous stream of new documents and user-generated queries. These naturally change over time based on events in the world and the evolution of language. Neural retrieval models that were trained once on a fixed set of query-document pairs will quickly start misrepresenting newly-created content and queries, leading to less effective retrieval. Traditional statistical sparse retrieval can update collection statistics to reflect these changes in the use of language in documents and queries. In contrast, continued fine-tuning of the language model underlying neural retrieval approaches such as DPR and ColBERT creates incompatibility with previously-encoded documents. Re-encoding and re-indexing all previously-processed documents can be costly. In this work, we explore updating a neural dual encoder retrieval model without reprocessing past documents in the stream. We propose MURR, a model updating strategy with regularized replay, to ensure the model can still faithfully search existing documents without reprocessing, while continuing to update the model for the latest topics. In our simulated streaming environments, we show that fine-tuning models using MURR leads to more effective and more consistent retrieval results than other strategies as the stream of documents and queries progresses.
Efficient Constant-Space Multi-Vector Retrieval
Apr 02, 2025Multi-vector retrieval methods, exemplified by the ColBERT architecture, have shown substantial promise for retrieval by providing strong trade-offs in terms of retrieval latency and effectiveness. However, they come at a high cost in terms of storage since a (potentially compressed) vector needs to be stored for every token in the input collection. To overcome this issue, we propose encoding documents to a fixed number of vectors, which are no longer necessarily tied to the input tokens. Beyond reducing the storage costs, our approach has the advantage that document representations become of a fixed size on disk, allowing for better OS paging management. Through experiments using the MSMARCO passage corpus and BEIR with the ColBERT-v2 architecture, a representative multi-vector ranking model architecture, we find that passages can be effectively encoded into a fixed number of vectors while retaining most of the original effectiveness.
Exploring the Effectiveness of Multi-stage Fine-tuning for Cross-encoder Re-rankers
Mar 28, 2025State-of-the-art cross-encoders can be fine-tuned to be highly effective in passage re-ranking. The typical fine-tuning process of cross-encoders as re-rankers requires large amounts of manually labelled data, a contrastive learning objective, and a set of heuristically sampled negatives. An alternative recent approach for fine-tuning instead involves teaching the model to mimic the rankings of a highly effective large language model using a distillation objective. These fine-tuning strategies can be applied either individually, or in sequence. In this work, we systematically investigate the effectiveness of point-wise cross-encoders when fine-tuned independently in a single stage, or sequentially in two stages. Our experiments show that the effectiveness of point-wise cross-encoders fine-tuned using contrastive learning is indeed on par with that of models fine-tuned with multi-stage approaches. Code is available for reproduction at https://github.com/fpezzuti/multistage-finetuning.
ECLIPSE: Contrastive Dimension Importance Estimation with Pseudo-Irrelevance Feedback for Dense Retrieval
Dec 19, 2024



Recent advances in Information Retrieval have leveraged high-dimensional embedding spaces to improve the retrieval of relevant documents. Moreover, the Manifold Clustering Hypothesis suggests that despite these high-dimensional representations, documents relevant to a query reside on a lower-dimensional, query-dependent manifold. While this hypothesis has inspired new retrieval methods, existing approaches still face challenges in effectively separating non-relevant information from relevant signals. We propose a novel methodology that addresses these limitations by leveraging information from both relevant and non-relevant documents. Our method, ECLIPSE, computes a centroid based on irrelevant documents as a reference to estimate noisy dimensions present in relevant ones, enhancing retrieval performance. Extensive experiments on three in-domain and one out-of-domain benchmarks demonstrate an average improvement of up to 19.50% (resp. 22.35%) in mAP(AP) and 11.42% (resp. 13.10%) in nDCG@10 w.r.t. the DIME-based baseline (resp. the baseline using all dimensions). Our results pave the way for more robust, pseudo-irrelevance-based retrieval systems in future IR research.
Maybe you are looking for CroQS: Cross-modal Query Suggestion for Text-to-Image Retrieval
Dec 18, 2024
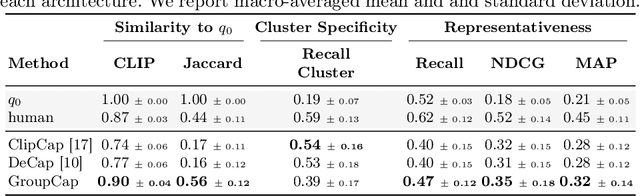

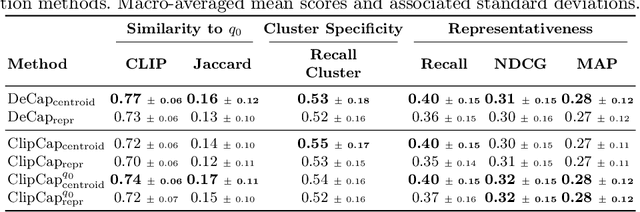
Query suggestion, a technique widely adopted in information retrieval, enhances system interactivity and the browsing experience of document collections. In cross-modal retrieval, many works have focused on retrieving relevant items from natural language queries, while few have explored query suggestion solutions. In this work, we address query suggestion in cross-modal retrieval, introducing a novel task that focuses on suggesting minimal textual modifications needed to explore visually consistent subsets of the collection, following the premise of ''Maybe you are looking for''. To facilitate the evaluation and development of methods, we present a tailored benchmark named CroQS. This dataset comprises initial queries, grouped result sets, and human-defined suggested queries for each group. We establish dedicated metrics to rigorously evaluate the performance of various methods on this task, measuring representativeness, cluster specificity, and similarity of the suggested queries to the original ones. Baseline methods from related fields, such as image captioning and content summarization, are adapted for this task to provide reference performance scores. Although relatively far from human performance, our experiments reveal that both LLM-based and captioning-based methods achieve competitive results on CroQS, improving the recall on cluster specificity by more than 115% and representativeness mAP by more than 52% with respect to the initial query. The dataset, the implementation of the baseline methods and the notebooks containing our experiments are available here: https://paciosoft.com/CroQS-benchmark/
Static Pruning in Dense Retrieval using Matrix Decomposition
Dec 13, 2024

In the era of dense retrieval, document indexing and retrieval is largely based on encoding models that transform text documents into embeddings. The efficiency of retrieval is directly proportional to the number of documents and the size of the embeddings. Recent studies have shown that it is possible to reduce embedding size without sacrificing - and in some cases improving - the retrieval effectiveness. However, the methods introduced by these studies are query-dependent, so they can't be applied offline and require additional computations during query processing, thus negatively impacting the retrieval efficiency. In this paper, we present a novel static pruning method for reducing the dimensionality of embeddings using Principal Components Analysis. This approach is query-independent and can be executed offline, leading to a significant boost in dense retrieval efficiency with a negligible impact on the system effectiveness. Our experiments show that our proposed method reduces the dimensionality of document representations by over 50% with up to a 5% reduction in NDCG@10, for different dense retrieval models.