 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCountingDINO: A Training-free Pipeline for Class-Agnostic Counting using Unsupervised Backbones
Apr 23, 2025

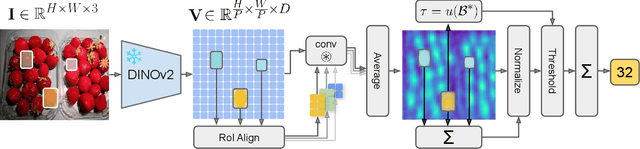

Class-agnostic counting (CAC) aims to estimate the number of objects in images without being restricted to predefined categories. However, while current exemplar-based CAC methods offer flexibility at inference time, they still rely heavily on labeled data for training, which limits scalability and generalization to many downstream use cases. In this paper, we introduce CountingDINO, the first training-free exemplar-based CAC framework that exploits a fully unsupervised feature extractor. Specifically, our approach employs self-supervised vision-only backbones to extract object-aware features, and it eliminates the need for annotated data throughout the entire proposed pipeline. At inference time, we extract latent object prototypes via ROI-Align from DINO features and use them as convolutional kernels to generate similarity maps. These are then transformed into density maps through a simple yet effective normalization scheme. We evaluate our approach on the FSC-147 benchmark, where we outperform a baseline under the same label-free setting. Our method also achieves competitive -- and in some cases superior -- results compared to training-free approaches relying on supervised backbones, as well as several fully supervised state-of-the-art methods. This demonstrates that training-free CAC can be both scalable and competitive. Website: https://lorebianchi98.github.io/CountingDINO/
Towards Identity-Aware Cross-Modal Retrieval: a Dataset and a Baseline
Dec 30, 2024



Recent advancements in deep learning have significantly enhanced content-based retrieval methods, notably through models like CLIP that map images and texts into a shared embedding space. However, these methods often struggle with domain-specific entities and long-tail concepts absent from their training data, particularly in identifying specific individuals. In this paper, we explore the task of identity-aware cross-modal retrieval, which aims to retrieve images of persons in specific contexts based on natural language queries. This task is critical in various scenarios, such as for searching and browsing personalized video collections or large audio-visual archives maintained by national broadcasters. We introduce a novel dataset, COCO Person FaceSwap (COCO-PFS), derived from the widely used COCO dataset and enriched with deepfake-generated faces from VGGFace2. This dataset addresses the lack of large-scale datasets needed for training and evaluating models for this task. Our experiments assess the performance of different CLIP variations repurposed for this task, including our architecture, Identity-aware CLIP (Id-CLIP), which achieves competitive retrieval performance through targeted fine-tuning. Our contributions lay the groundwork for more robust cross-modal retrieval systems capable of recognizing long-tail identities and contextual nuances. Data and code are available at https://github.com/mesnico/IdCLIP.
Maybe you are looking for CroQS: Cross-modal Query Suggestion for Text-to-Image Retrieval
Dec 18, 2024
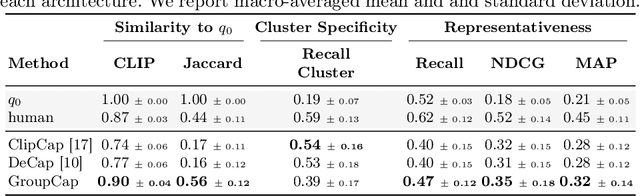

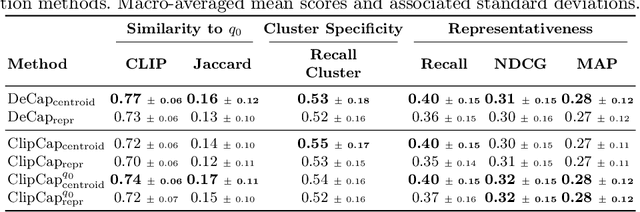
Query suggestion, a technique widely adopted in information retrieval, enhances system interactivity and the browsing experience of document collections. In cross-modal retrieval, many works have focused on retrieving relevant items from natural language queries, while few have explored query suggestion solutions. In this work, we address query suggestion in cross-modal retrieval, introducing a novel task that focuses on suggesting minimal textual modifications needed to explore visually consistent subsets of the collection, following the premise of ''Maybe you are looking for''. To facilitate the evaluation and development of methods, we present a tailored benchmark named CroQS. This dataset comprises initial queries, grouped result sets, and human-defined suggested queries for each group. We establish dedicated metrics to rigorously evaluate the performance of various methods on this task, measuring representativeness, cluster specificity, and similarity of the suggested queries to the original ones. Baseline methods from related fields, such as image captioning and content summarization, are adapted for this task to provide reference performance scores. Although relatively far from human performance, our experiments reveal that both LLM-based and captioning-based methods achieve competitive results on CroQS, improving the recall on cluster specificity by more than 115% and representativeness mAP by more than 52% with respect to the initial query. The dataset, the implementation of the baseline methods and the notebooks containing our experiments are available here: https://paciosoft.com/CroQS-benchmark/
Talking to DINO: Bridging Self-Supervised Vision Backbones with Language for Open-Vocabulary Segmentation
Nov 28, 2024



Open-Vocabulary Segmentation (OVS) aims at segmenting images from free-form textual concepts without predefined training classes. While existing vision-language models such as CLIP can generate segmentation masks by leveraging coarse spatial information from Vision Transformers, they face challenges in spatial localization due to their global alignment of image and text features. Conversely, self-supervised visual models like DINO excel in fine-grained visual encoding but lack integration with language. To bridge this gap, we present Talk2DINO, a novel hybrid approach that combines the spatial accuracy of DINOv2 with the language understanding of CLIP. Our approach aligns the textual embeddings of CLIP to the patch-level features of DINOv2 through a learned mapping function without the need to fine-tune the underlying backbones. At training time, we exploit the attention maps of DINOv2 to selectively align local visual patches with textual embeddings. We show that the powerful semantic and localization abilities of Talk2DINO can enhance the segmentation process, resulting in more natural and less noisy segmentations, and that our approach can also effectively distinguish foreground objects from the background. Experimental results demonstrate that Talk2DINO achieves state-of-the-art performance across several unsupervised OVS benchmarks. Source code and models are publicly available at: https://lorebianchi98.github.io/Talk2DINO/.
Mind the Prompt: A Novel Benchmark for Prompt-based Class-Agnostic Counting
Sep 24, 2024Class-agnostic counting (CAC) is a recent task in computer vision that aims to estimate the number of instances of arbitrary object classes never seen during model training. With the recent advancement of robust vision-and-language foundation models, there is a growing interest in prompt-based CAC, where object categories to be counted can be specified using natural language. However, we identify significant limitations in current benchmarks for evaluating this task, which hinder both accurate assessment and the development of more effective solutions. Specifically, we argue that the current evaluation protocols do not measure the ability of the model to understand which object has to be counted. This is due to two main factors: (i) the shortcomings of CAC datasets, which primarily consist of images containing objects from a single class, and (ii) the limitations of current counting performance evaluators, which are based on traditional class-specific counting and focus solely on counting errors. To fill this gap, we introduce the Prompt-Aware Counting (PrACo) benchmark, which comprises two targeted tests, each accompanied by appropriate evaluation metrics. We evaluate state-of-the-art methods and demonstrate that, although some achieve impressive results on standard class-specific counting metrics, they exhibit a significant deficiency in understanding the input prompt, indicating the need for more careful training procedures or revised designs. The code for reproducing our results is available at https://github.com/ciampluca/PrACo.
Joint-Dataset Learning and Cross-Consistent Regularization for Text-to-Motion Retrieval
Jul 02, 2024

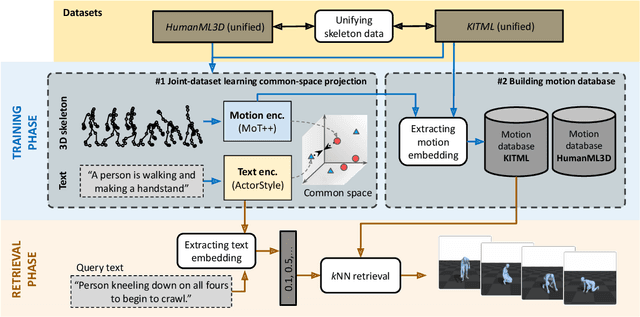

Pose-estimation methods enable extracting human motion from common videos in the structured form of 3D skeleton sequences. Despite great application opportunities, effective content-based access to such spatio-temporal motion data is a challenging problem. In this paper, we focus on the recently introduced text-motion retrieval tasks, which aim to search for database motions that are the most relevant to a specified natural-language textual description (text-to-motion) and vice-versa (motion-to-text). Despite recent efforts to explore these promising avenues, a primary challenge remains the insufficient data available to train robust text-motion models effectively. To address this issue, we propose to investigate joint-dataset learning - where we train on multiple text-motion datasets simultaneously - together with the introduction of a Cross-Consistent Contrastive Loss function (CCCL), which regularizes the learned text-motion common space by imposing uni-modal constraints that augment the representation ability of the trained network. To learn a proper motion representation, we also introduce a transformer-based motion encoder, called MoT++, which employs spatio-temporal attention to process sequences of skeleton data. We demonstrate the benefits of the proposed approaches on the widely-used KIT Motion-Language and HumanML3D datasets. We perform detailed experimentation on joint-dataset learning and cross-dataset scenarios, showing the effectiveness of each introduced module in a carefully conducted ablation study and, in turn, pointing out the limitations of state-of-the-art methods.
Is CLIP the main roadblock for fine-grained open-world perception?
Apr 04, 2024



Modern applications increasingly demand flexible computer vision models that adapt to novel concepts not encountered during training. This necessity is pivotal in emerging domains like extended reality, robotics, and autonomous driving, which require the ability to respond to open-world stimuli. A key ingredient is the ability to identify objects based on free-form textual queries defined at inference time - a task known as open-vocabulary object detection. Multimodal backbones like CLIP are the main enabling technology for current open-world perception solutions. Despite performing well on generic queries, recent studies highlighted limitations on the fine-grained recognition capabilities in open-vocabulary settings - i.e., for distinguishing subtle object features like color, shape, and material. In this paper, we perform a detailed examination of these open-vocabulary object recognition limitations to find the root cause. We evaluate the performance of CLIP, the most commonly used vision-language backbone, against a fine-grained object-matching benchmark, revealing interesting analogies between the limitations of open-vocabulary object detectors and their backbones. Experiments suggest that the lack of fine-grained understanding is caused by the poor separability of object characteristics in the CLIP latent space. Therefore, we try to understand whether fine-grained knowledge is present in CLIP embeddings but not exploited at inference time due, for example, to the unsuitability of the cosine similarity matching function, which may discard important object characteristics. Our preliminary experiments show that simple CLIP latent-space re-projections help separate fine-grained concepts, paving the way towards the development of backbones inherently able to process fine-grained details. The code for reproducing these experiments is available at https://github.com/lorebianchi98/FG-CLIP.
The devil is in the fine-grained details: Evaluating open-vocabulary object detectors for fine-grained understanding
Nov 29, 2023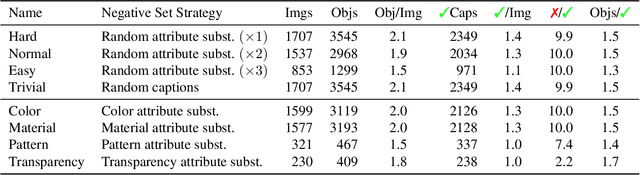


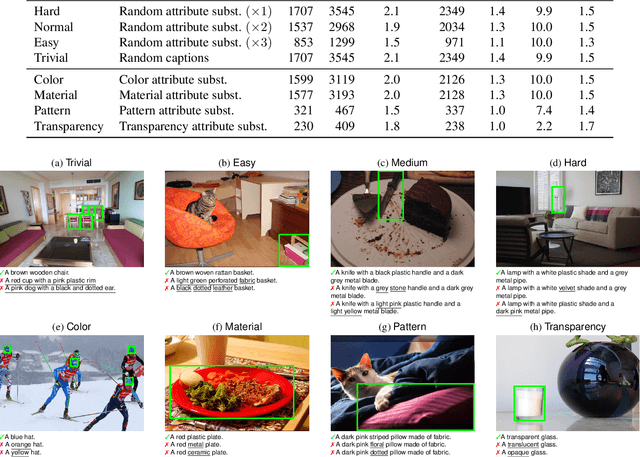
Recent advancements in large vision-language models enabled visual object detection in open-vocabulary scenarios, where object classes are defined in free-text formats during inference. In this paper, we aim to probe the state-of-the-art methods for open-vocabulary object detection to determine to what extent they understand fine-grained properties of objects and their parts. To this end, we introduce an evaluation protocol based on dynamic vocabulary generation to test whether models detect, discern, and assign the correct fine-grained description to objects in the presence of hard-negative classes. We contribute with a benchmark suite of increasing difficulty and probing different properties like color, pattern, and material. We further enhance our investigation by evaluating several state-of-the-art open-vocabulary object detectors using the proposed protocol and find that most existing solutions, which shine in standard open-vocabulary benchmarks, struggle to accurately capture and distinguish finer object details. We conclude the paper by highlighting the limitations of current methodologies and exploring promising research directions to overcome the discovered drawbacks. Data and code are available at https://github.com/lorebianchi98/FG-OVD.
Text-to-Motion Retrieval: Towards Joint Understanding of Human Motion Data and Natural Language
May 25, 2023



Due to recent advances in pose-estimation methods, human motion can be extracted from a common video in the form of 3D skeleton sequences. Despite wonderful application opportunities, effective and efficient content-based access to large volumes of such spatio-temporal skeleton data still remains a challenging problem. In this paper, we propose a novel content-based text-to-motion retrieval task, which aims at retrieving relevant motions based on a specified natural-language textual description. To define baselines for this uncharted task, we employ the BERT and CLIP language representations to encode the text modality and successful spatio-temporal models to encode the motion modality. We additionally introduce our transformer-based approach, called Motion Transformer (MoT), which employs divided space-time attention to effectively aggregate the different skeleton joints in space and time. Inspired by the recent progress in text-to-image/video matching, we experiment with two widely-adopted metric-learning loss functions. Finally, we set up a common evaluation protocol by defining qualitative metrics for assessing the quality of the retrieved motions, targeting the two recently-introduced KIT Motion-Language and HumanML3D datasets. The code for reproducing our results is available at https://github.com/mesnico/text-to-motion-retrieval.
Development of a Realistic Crowd Simulation Environment for Fine-grained Validation of People Tracking Methods
Apr 26, 2023



Generally, crowd datasets can be collected or generated from real or synthetic sources. Real data is generated by using infrastructure-based sensors (such as static cameras or other sensors). The use of simulation tools can significantly reduce the time required to generate scenario-specific crowd datasets, facilitate data-driven research, and next build functional machine learning models. The main goal of this work was to develop an extension of crowd simulation (named CrowdSim2) and prove its usability in the application of people-tracking algorithms. The simulator is developed using the very popular Unity 3D engine with particular emphasis on the aspects of realism in the environment, weather conditions, traffic, and the movement and models of individual agents. Finally, three methods of tracking were used to validate generated dataset: IOU-Tracker, Deep-Sort, and Deep-TAMA.