 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint-Dataset Learning and Cross-Consistent Regularization for Text-to-Motion Retrieval
Jul 02, 2024

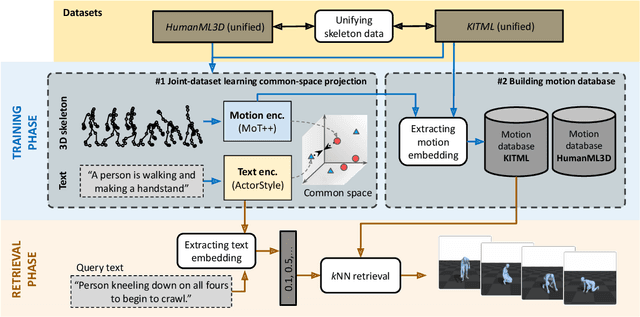

Pose-estimation methods enable extracting human motion from common videos in the structured form of 3D skeleton sequences. Despite great application opportunities, effective content-based access to such spatio-temporal motion data is a challenging problem. In this paper, we focus on the recently introduced text-motion retrieval tasks, which aim to search for database motions that are the most relevant to a specified natural-language textual description (text-to-motion) and vice-versa (motion-to-text). Despite recent efforts to explore these promising avenues, a primary challenge remains the insufficient data available to train robust text-motion models effectively. To address this issue, we propose to investigate joint-dataset learning - where we train on multiple text-motion datasets simultaneously - together with the introduction of a Cross-Consistent Contrastive Loss function (CCCL), which regularizes the learned text-motion common space by imposing uni-modal constraints that augment the representation ability of the trained network. To learn a proper motion representation, we also introduce a transformer-based motion encoder, called MoT++, which employs spatio-temporal attention to process sequences of skeleton data. We demonstrate the benefits of the proposed approaches on the widely-used KIT Motion-Language and HumanML3D datasets. We perform detailed experimentation on joint-dataset learning and cross-dataset scenarios, showing the effectiveness of each introduced module in a carefully conducted ablation study and, in turn, pointing out the limitations of state-of-the-art methods.
Text-to-Motion Retrieval: Towards Joint Understanding of Human Motion Data and Natural Language
May 25, 2023



Due to recent advances in pose-estimation methods, human motion can be extracted from a common video in the form of 3D skeleton sequences. Despite wonderful application opportunities, effective and efficient content-based access to large volumes of such spatio-temporal skeleton data still remains a challenging problem. In this paper, we propose a novel content-based text-to-motion retrieval task, which aims at retrieving relevant motions based on a specified natural-language textual description. To define baselines for this uncharted task, we employ the BERT and CLIP language representations to encode the text modality and successful spatio-temporal models to encode the motion modality. We additionally introduce our transformer-based approach, called Motion Transformer (MoT), which employs divided space-time attention to effectively aggregate the different skeleton joints in space and time. Inspired by the recent progress in text-to-image/video matching, we experiment with two widely-adopted metric-learning loss functions. Finally, we set up a common evaluation protocol by defining qualitative metrics for assessing the quality of the retrieved motions, targeting the two recently-introduced KIT Motion-Language and HumanML3D datasets. The code for reproducing our results is available at https://github.com/mesnico/text-to-motion-retrieval.