 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe State-of-the-Art in Lifelog Retrieval: A Review of Progress at the ACM Lifelog Search Challenge Workshop 2022-24
Jun 07, 2025The ACM Lifelog Search Challenge (LSC) is a venue that welcomes and compares systems that support the exploration of lifelog data, and in particular the retrieval of specific information, through an interactive competition format. This paper reviews the recent advances in interactive lifelog retrieval as demonstrated at the ACM LSC from 2022 to 2024. Through a detailed comparative analysis, we highlight key improvements across three main retrieval tasks: known-item search, question answering, and ad-hoc search. Our analysis identifies trends such as the widespread adoption of embedding-based retrieval methods (e.g., CLIP, BLIP), increased integration of large language models (LLMs) for conversational retrieval, and continued innovation in multimodal and collaborative search interfaces. We further discuss how specific retrieval techniques and user interface (UI) designs have impacted system performance, emphasizing the importance of balancing retrieval complexity with usability. Our findings indicate that embedding-driven approaches combined with LLMs show promise for lifelog retrieval systems. Likewise, improving UI design can enhance usability and efficiency. Additionally, we recommend reconsidering multi-instance system evaluations within the expert track to better manage variability in user familiarity and configuration effectiveness.
Towards Identity-Aware Cross-Modal Retrieval: a Dataset and a Baseline
Dec 30, 2024



Recent advancements in deep learning have significantly enhanced content-based retrieval methods, notably through models like CLIP that map images and texts into a shared embedding space. However, these methods often struggle with domain-specific entities and long-tail concepts absent from their training data, particularly in identifying specific individuals. In this paper, we explore the task of identity-aware cross-modal retrieval, which aims to retrieve images of persons in specific contexts based on natural language queries. This task is critical in various scenarios, such as for searching and browsing personalized video collections or large audio-visual archives maintained by national broadcasters. We introduce a novel dataset, COCO Person FaceSwap (COCO-PFS), derived from the widely used COCO dataset and enriched with deepfake-generated faces from VGGFace2. This dataset addresses the lack of large-scale datasets needed for training and evaluating models for this task. Our experiments assess the performance of different CLIP variations repurposed for this task, including our architecture, Identity-aware CLIP (Id-CLIP), which achieves competitive retrieval performance through targeted fine-tuning. Our contributions lay the groundwork for more robust cross-modal retrieval systems capable of recognizing long-tail identities and contextual nuances. Data and code are available at https://github.com/mesnico/IdCLIP.
nSimplex Zen: A Novel Dimensionality Reduction for Euclidean and Hilbert Spaces
Feb 22, 2023



Dimensionality reduction techniques map values from a high dimensional space to one with a lower dimension. The result is a space which requires less physical memory and has a faster distance calculation. These techniques are widely used where required properties of the reduced-dimension space give an acceptable accuracy with respect to the original space. Many such transforms have been described. They have been classified in two main groups: linear and topological. Linear methods such as Principal Component Analysis (PCA) and Random Projection (RP) define matrix-based transforms into a lower dimension of Euclidean space. Topological methods such as Multidimensional Scaling (MDS) attempt to preserve higher-level aspects such as the nearest-neighbour relation, and some may be applied to non-Euclidean spaces. Here, we introduce nSimplex Zen, a novel topological method of reducing dimensionality. Like MDS, it relies only upon pairwise distances measured in the original space. The use of distances, rather than coordinates, allows the technique to be applied to both Euclidean and other Hilbert spaces, including those governed by Cosine, Jensen-Shannon and Quadratic Form distances. We show that in almost all cases, due to geometric properties of high-dimensional spaces, our new technique gives better properties than others, especially with reduction to very low dimensions.
MOBDrone: a Drone Video Dataset for Man OverBoard Rescue
Mar 15, 2022



Modern Unmanned Aerial Vehicles (UAV) equipped with cameras can play an essential role in speeding up the identification and rescue of people who have fallen overboard, i.e., man overboard (MOB). To this end, Artificial Intelligence techniques can be leveraged for the automatic understanding of visual data acquired from drones. However, detecting people at sea in aerial imagery is challenging primarily due to the lack of specialized annotated datasets for training and testing detectors for this task. To fill this gap, we introduce and publicly release the MOBDrone benchmark, a collection of more than 125K drone-view images in a marine environment under several conditions, such as different altitudes, camera shooting angles, and illumination. We manually annotated more than 180K objects, of which about 113K man overboard, precisely localizing them with bounding boxes. Moreover, we conduct a thorough performance analysis of several state-of-the-art object detectors on the MOBDrone data, serving as baselines for further research.
A Leap among Entanglement and Neural Networks: A Quantum Survey
Jul 06, 2021
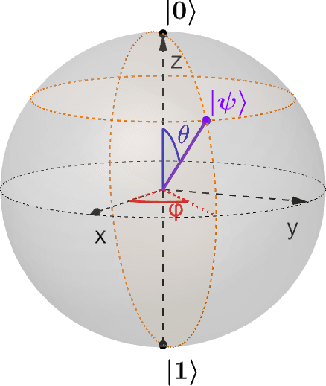


In recent years, Quantum Computing witnessed massive improvements both in terms of resources availability and algorithms development. The ability to harness quantum phenomena to solve computational problems is a long-standing dream that has drawn the scientific community's interest since the late '80s. In such a context, we pose our contribution. First, we introduce basic concepts related to quantum computations, and then we explain the core functionalities of technologies that implement the Gate Model and Adiabatic Quantum Computing paradigms. Finally, we gather, compare and analyze the current state-of-the-art concerning Quantum Perceptrons and Quantum Neural Networks implementations.
The VISIONE Video Search System: Exploiting Off-the-Shelf Text Search Engines for Large-Scale Video Retrieval
Aug 06, 2020
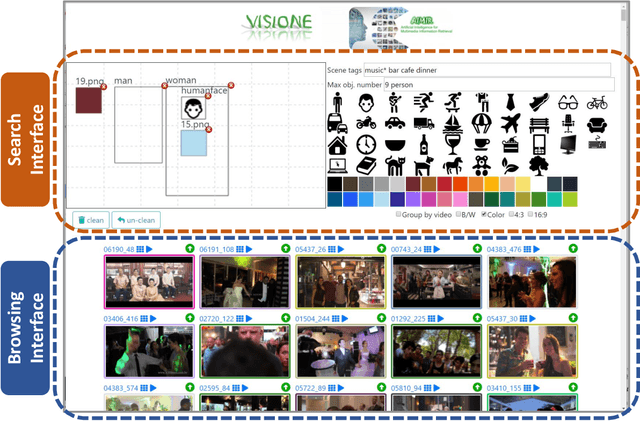
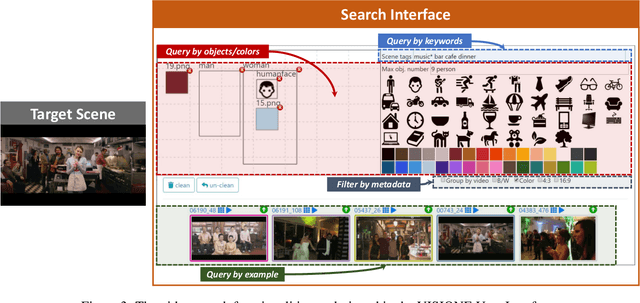

In this paper, we describe VISIONE, a video search system that allows users to search for videos using textual keywords, occurrence of objects and their spatial relationships, occurrence of colors and their spatial relationships, and image similarity. These modalities can be combined together to express complex queries and satisfy user needs. The peculiarity of our approach is that we encode all the information extracted from the keyframes, such as visual deep features, tags, color and object locations, using a convenient textual encoding indexed in a single text retrieval engine. This offers great flexibility when results corresponding to various parts of the query needs to be merged. We report an extensive analysis of the system retrieval performance, using the query logs generated during the Video Browser Showdown (VBS) 2019 competition. This allowed us to fine-tune the system by choosing the optimal parameters and strategies among the ones that we tested.
Aggregating Binary Local Descriptors for Image Retrieval
Feb 03, 2017



Content-Based Image Retrieval based on local features is computationally expensive because of the complexity of both extraction and matching of local feature. On one hand, the cost for extracting, representing, and comparing local visual descriptors has been dramatically reduced by recently proposed binary local features. On the other hand, aggregation techniques provide a meaningful summarization of all the extracted feature of an image into a single descriptor, allowing us to speed up and scale up the image search. Only a few works have recently mixed together these two research directions, defining aggregation methods for binary local features, in order to leverage on the advantage of both approaches. In this paper, we report an extensive comparison among state-of-the-art aggregation methods applied to binary features. Then, we mathematically formalize the application of Fisher Kernels to Bernoulli Mixture Models. Finally, we investigate the combination of the aggregated binary features with the emerging Convolutional Neural Network (CNN) features. Our results show that aggregation methods on binary features are effective and represent a worthwhile alternative to the direct matching. Moreover, the combination of the CNN with the Fisher Vector (FV) built upon binary features allowed us to obtain a relative improvement over the CNN results that is in line with that recently obtained using the combination of the CNN with the FV built upon SIFTs. The advantage of using the FV built upon binary features is that the extraction process of binary features is about two order of magnitude faster than SIFTs.
Using Apache Lucene to Search Vector of Locally Aggregated Descriptors
Apr 19, 2016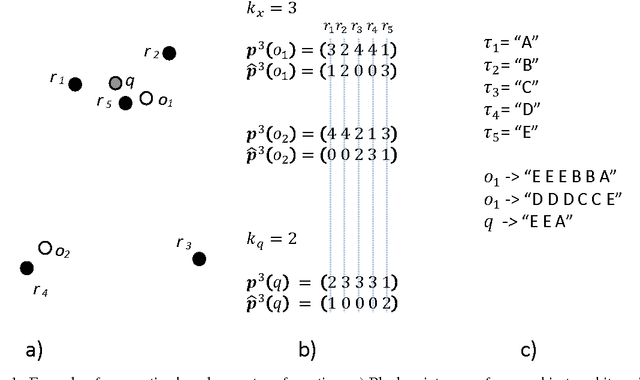



Surrogate Text Representation (STR) is a profitable solution to efficient similarity search on metric space using conventional text search engines, such as Apache Lucene. This technique is based on comparing the permutations of some reference objects in place of the original metric distance. However, the Achilles heel of STR approach is the need to reorder the result set of the search according to the metric distance. This forces to use a support database to store the original objects, which requires efficient random I/O on a fast secondary memory (such as flash-based storages). In this paper, we propose to extend the Surrogate Text Representation to specifically address a class of visual metric objects known as Vector of Locally Aggregated Descriptors (VLAD). This approach is based on representing the individual sub-vectors forming the VLAD vector with the STR, providing a finer representation of the vector and enabling us to get rid of the reordering phase. The experiments on a publicly available dataset show that the extended STR outperforms the baseline STR achieving satisfactory performance near to the one obtained with the original VLAD vectors.