 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCA3D: Convolutional-Attentional 3D Nets for Efficient Video Activity Recognition on the Edge
May 26, 2025In this paper, we introduce a deep learning solution for video activity recognition that leverages an innovative combination of convolutional layers with a linear-complexity attention mechanism. Moreover, we introduce a novel quantization mechanism to further improve the efficiency of our model during both training and inference. Our model maintains a reduced computational cost, while preserving robust learning and generalization capabilities. Our approach addresses the issues related to the high computing requirements of current models, with the goal of achieving competitive accuracy on consumer and edge devices, enabling smart home and smart healthcare applications where efficiency and privacy issues are of concern. We experimentally validate our model on different established and publicly available video activity recognition benchmarks, improving accuracy over alternative models at a competitive computing cost.
ViSketch-GPT: Collaborative Multi-Scale Feature Extraction for Sketch Recognition and Generation
Mar 28, 2025Understanding the nature of human sketches is challenging because of the wide variation in how they are created. Recognizing complex structural patterns improves both the accuracy in recognizing sketches and the fidelity of the generated sketches. In this work, we introduce ViSketch-GPT, a novel algorithm designed to address these challenges through a multi-scale context extraction approach. The model captures intricate details at multiple scales and combines them using an ensemble-like mechanism, where the extracted features work collaboratively to enhance the recognition and generation of key details crucial for classification and generation tasks. The effectiveness of ViSketch-GPT is validated through extensive experiments on the QuickDraw dataset. Our model establishes a new benchmark, significantly outperforming existing methods in both classification and generation tasks, with substantial improvements in accuracy and the fidelity of generated sketches. The proposed algorithm offers a robust framework for understanding complex structures by extracting features that collaborate to recognize intricate details, enhancing the understanding of structures like sketches and making it a versatile tool for various applications in computer vision and machine learning.
Towards Identity-Aware Cross-Modal Retrieval: a Dataset and a Baseline
Dec 30, 2024



Recent advancements in deep learning have significantly enhanced content-based retrieval methods, notably through models like CLIP that map images and texts into a shared embedding space. However, these methods often struggle with domain-specific entities and long-tail concepts absent from their training data, particularly in identifying specific individuals. In this paper, we explore the task of identity-aware cross-modal retrieval, which aims to retrieve images of persons in specific contexts based on natural language queries. This task is critical in various scenarios, such as for searching and browsing personalized video collections or large audio-visual archives maintained by national broadcasters. We introduce a novel dataset, COCO Person FaceSwap (COCO-PFS), derived from the widely used COCO dataset and enriched with deepfake-generated faces from VGGFace2. This dataset addresses the lack of large-scale datasets needed for training and evaluating models for this task. Our experiments assess the performance of different CLIP variations repurposed for this task, including our architecture, Identity-aware CLIP (Id-CLIP), which achieves competitive retrieval performance through targeted fine-tuning. Our contributions lay the groundwork for more robust cross-modal retrieval systems capable of recognizing long-tail identities and contextual nuances. Data and code are available at https://github.com/mesnico/IdCLIP.
Exploring Strengths and Weaknesses of Super-Resolution Attack in Deepfake Detection
Oct 05, 2024
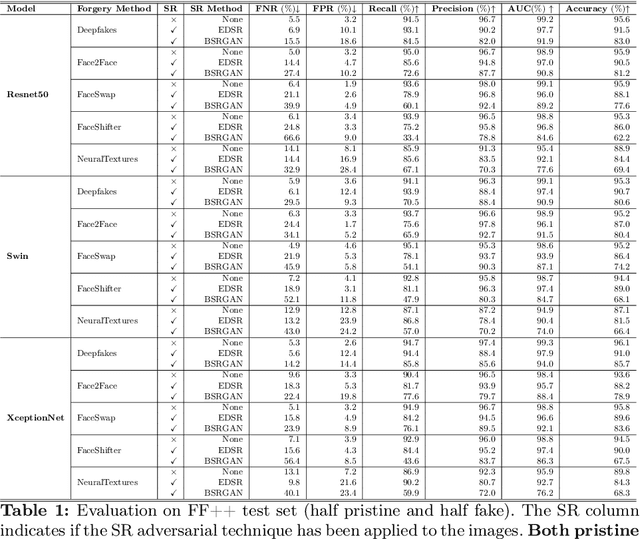
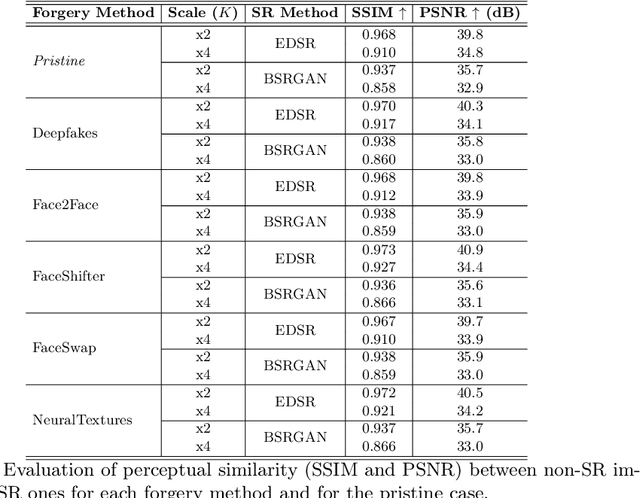

Image manipulation is rapidly evolving, allowing the creation of credible content that can be used to bend reality. Although the results of deepfake detectors are promising, deepfakes can be made even more complicated to detect through adversarial attacks. They aim to further manipulate the image to camouflage deepfakes' artifacts or to insert signals making the image appear pristine. In this paper, we further explore the potential of super-resolution attacks based on different super-resolution techniques and with different scales that can impact the performance of deepfake detectors with more or less intensity. We also evaluated the impact of the attack on more diverse datasets discovering that the super-resolution process is effective in hiding the artifacts introduced by deepfake generation models but fails in hiding the traces contained in fully synthetic images. Finally, we propose some changes to the detectors' training process to improve their robustness to this kind of attack.
Adversarial Magnification to Deceive Deepfake Detection through Super Resolution
Jul 02, 2024



Deepfake technology is rapidly advancing, posing significant challenges to the detection of manipulated media content. Parallel to that, some adversarial attack techniques have been developed to fool the deepfake detectors and make deepfakes even more difficult to be detected. This paper explores the application of super resolution techniques as a possible adversarial attack in deepfake detection. Through our experiments, we demonstrate that minimal changes made by these methods in the visual appearance of images can have a profound impact on the performance of deepfake detection systems. We propose a novel attack using super resolution as a quick, black-box and effective method to camouflage fake images and/or generate false alarms on pristine images. Our results indicate that the usage of super resolution can significantly impair the accuracy of deepfake detectors, thereby highlighting the vulnerability of such systems to adversarial attacks. The code to reproduce our experiments is available at: https://github.com/davide-coccomini/Adversarial-Magnification-to-Deceive-Deepfake-Detection-through-Super-Resolution
Deepfake Detection without Deepfakes: Generalization via Synthetic Frequency Patterns Injection
Mar 20, 2024Deepfake detectors are typically trained on large sets of pristine and generated images, resulting in limited generalization capacity; they excel at identifying deepfakes created through methods encountered during training but struggle with those generated by unknown techniques. This paper introduces a learning approach aimed at significantly enhancing the generalization capabilities of deepfake detectors. Our method takes inspiration from the unique "fingerprints" that image generation processes consistently introduce into the frequency domain. These fingerprints manifest as structured and distinctly recognizable frequency patterns. We propose to train detectors using only pristine images injecting in part of them crafted frequency patterns, simulating the effects of various deepfake generation techniques without being specific to any. These synthetic patterns are based on generic shapes, grids, or auras. We evaluated our approach using diverse architectures across 25 different generation methods. The models trained with our approach were able to perform state-of-the-art deepfake detection, demonstrating also superior generalization capabilities in comparison with previous methods. Indeed, they are untied to any specific generation technique and can effectively identify deepfakes regardless of how they were made.
The devil is in the fine-grained details: Evaluating open-vocabulary object detectors for fine-grained understanding
Nov 29, 2023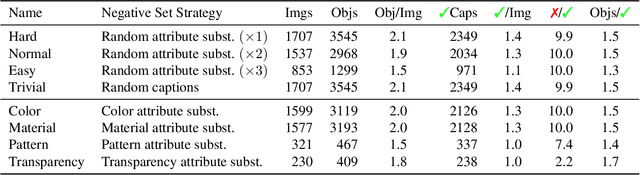


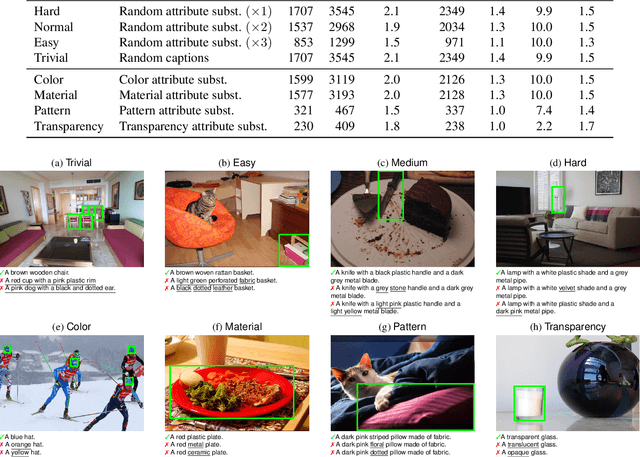
Recent advancements in large vision-language models enabled visual object detection in open-vocabulary scenarios, where object classes are defined in free-text formats during inference. In this paper, we aim to probe the state-of-the-art methods for open-vocabulary object detection to determine to what extent they understand fine-grained properties of objects and their parts. To this end, we introduce an evaluation protocol based on dynamic vocabulary generation to test whether models detect, discern, and assign the correct fine-grained description to objects in the presence of hard-negative classes. We contribute with a benchmark suite of increasing difficulty and probing different properties like color, pattern, and material. We further enhance our investigation by evaluating several state-of-the-art open-vocabulary object detectors using the proposed protocol and find that most existing solutions, which shine in standard open-vocabulary benchmarks, struggle to accurately capture and distinguish finer object details. We conclude the paper by highlighting the limitations of current methodologies and exploring promising research directions to overcome the discovered drawbacks. Data and code are available at https://github.com/lorebianchi98/FG-OVD.
Synaptic Plasticity Models and Bio-Inspired Unsupervised Deep Learning: A Survey
Jul 30, 2023



Recently emerged technologies based on Deep Learning (DL) achieved outstanding results on a variety of tasks in the field of Artificial Intelligence (AI). However, these encounter several challenges related to robustness to adversarial inputs, ecological impact, and the necessity of huge amounts of training data. In response, researchers are focusing more and more interest on biologically grounded mechanisms, which are appealing due to the impressive capabilities exhibited by biological brains. This survey explores a range of these biologically inspired models of synaptic plasticity, their application in DL scenarios, and the connections with models of plasticity in Spiking Neural Networks (SNNs). Overall, Bio-Inspired Deep Learning (BIDL) represents an exciting research direction, aiming at advancing not only our current technologies but also our understanding of intelligence.
Spiking Neural Networks and Bio-Inspired Supervised Deep Learning: A Survey
Jul 30, 2023



For a long time, biology and neuroscience fields have been a great source of inspiration for computer scientists, towards the development of Artificial Intelligence (AI) technologies. This survey aims at providing a comprehensive review of recent biologically-inspired approaches for AI. After introducing the main principles of computation and synaptic plasticity in biological neurons, we provide a thorough presentation of Spiking Neural Network (SNN) models, and we highlight the main challenges related to SNN training, where traditional backprop-based optimization is not directly applicable. Therefore, we discuss recent bio-inspired training methods, which pose themselves as alternatives to backprop, both for traditional and spiking networks. Bio-Inspired Deep Learning (BIDL) approaches towards advancing the computational capabilities and biological plausibility of current models.
Detecting Images Generated by Diffusers
Mar 09, 2023This paper explores the task of detecting images generated by text-to-image diffusion models. To evaluate this, we consider images generated from captions in the MSCOCO and Wikimedia datasets using two state-of-the-art models: Stable Diffusion and GLIDE. Our experiments show that it is possible to detect the generated images using simple Multi-Layer Perceptrons (MLPs), starting from features extracted by CLIP, or traditional Convolutional Neural Networks (CNNs). We also observe that models trained on images generated by Stable Diffusion can detect images generated by GLIDE relatively well, however, the reverse is not true. Lastly, we find that incorporating the associated textual information with the images rarely leads to significant improvement in detection results but that the type of subject depicted in the image can have a significant impact on performance. This work provides insights into the feasibility of detecting generated images, and has implications for security and privacy concerns in real-world applications.