 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Strengths and Weaknesses of Super-Resolution Attack in Deepfake Detection
Oct 05, 2024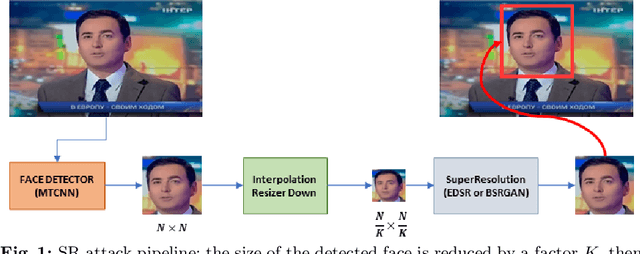
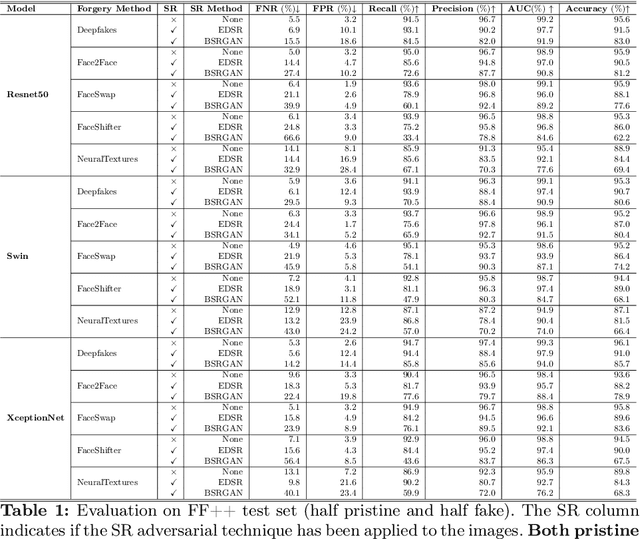
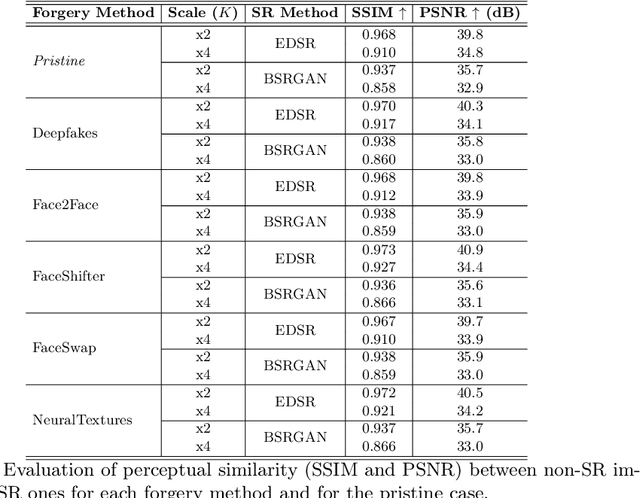

Image manipulation is rapidly evolving, allowing the creation of credible content that can be used to bend reality. Although the results of deepfake detectors are promising, deepfakes can be made even more complicated to detect through adversarial attacks. They aim to further manipulate the image to camouflage deepfakes' artifacts or to insert signals making the image appear pristine. In this paper, we further explore the potential of super-resolution attacks based on different super-resolution techniques and with different scales that can impact the performance of deepfake detectors with more or less intensity. We also evaluated the impact of the attack on more diverse datasets discovering that the super-resolution process is effective in hiding the artifacts introduced by deepfake generation models but fails in hiding the traces contained in fully synthetic images. Finally, we propose some changes to the detectors' training process to improve their robustness to this kind of attack.
Adversarial Magnification to Deceive Deepfake Detection through Super Resolution
Jul 02, 2024



Deepfake technology is rapidly advancing, posing significant challenges to the detection of manipulated media content. Parallel to that, some adversarial attack techniques have been developed to fool the deepfake detectors and make deepfakes even more difficult to be detected. This paper explores the application of super resolution techniques as a possible adversarial attack in deepfake detection. Through our experiments, we demonstrate that minimal changes made by these methods in the visual appearance of images can have a profound impact on the performance of deepfake detection systems. We propose a novel attack using super resolution as a quick, black-box and effective method to camouflage fake images and/or generate false alarms on pristine images. Our results indicate that the usage of super resolution can significantly impair the accuracy of deepfake detectors, thereby highlighting the vulnerability of such systems to adversarial attacks. The code to reproduce our experiments is available at: https://github.com/davide-coccomini/Adversarial-Magnification-to-Deceive-Deepfake-Detection-through-Super-Resolution
Deepfake Detection without Deepfakes: Generalization via Synthetic Frequency Patterns Injection
Mar 20, 2024Deepfake detectors are typically trained on large sets of pristine and generated images, resulting in limited generalization capacity; they excel at identifying deepfakes created through methods encountered during training but struggle with those generated by unknown techniques. This paper introduces a learning approach aimed at significantly enhancing the generalization capabilities of deepfake detectors. Our method takes inspiration from the unique "fingerprints" that image generation processes consistently introduce into the frequency domain. These fingerprints manifest as structured and distinctly recognizable frequency patterns. We propose to train detectors using only pristine images injecting in part of them crafted frequency patterns, simulating the effects of various deepfake generation techniques without being specific to any. These synthetic patterns are based on generic shapes, grids, or auras. We evaluated our approach using diverse architectures across 25 different generation methods. The models trained with our approach were able to perform state-of-the-art deepfake detection, demonstrating also superior generalization capabilities in comparison with previous methods. Indeed, they are untied to any specific generation technique and can effectively identify deepfakes regardless of how they were made.
Detecting Images Generated by Diffusers
Mar 09, 2023This paper explores the task of detecting images generated by text-to-image diffusion models. To evaluate this, we consider images generated from captions in the MSCOCO and Wikimedia datasets using two state-of-the-art models: Stable Diffusion and GLIDE. Our experiments show that it is possible to detect the generated images using simple Multi-Layer Perceptrons (MLPs), starting from features extracted by CLIP, or traditional Convolutional Neural Networks (CNNs). We also observe that models trained on images generated by Stable Diffusion can detect images generated by GLIDE relatively well, however, the reverse is not true. Lastly, we find that incorporating the associated textual information with the images rarely leads to significant improvement in detection results but that the type of subject depicted in the image can have a significant impact on performance. This work provides insights into the feasibility of detecting generated images, and has implications for security and privacy concerns in real-world applications.
MINTIME: Multi-Identity Size-Invariant Video Deepfake Detection
Dec 07, 2022



In this paper, we introduce MINTIME, a video deepfake detection approach that captures spatial and temporal anomalies and handles instances of multiple people in the same video and variations in face sizes. Previous approaches disregard such information either by using simple a-posteriori aggregation schemes, i.e., average or max operation, or using only one identity for the inference, i.e., the largest one. On the contrary, the proposed approach builds on a Spatio-Temporal TimeSformer combined with a Convolutional Neural Network backbone to capture spatio-temporal anomalies from the face sequences of multiple identities depicted in a video. This is achieved through an Identity-aware Attention mechanism that attends to each face sequence independently based on a masking operation and facilitates video-level aggregation. In addition, two novel embeddings are employed: (i) the Temporal Coherent Positional Embedding that encodes each face sequence's temporal information and (ii) the Size Embedding that encodes the size of the faces as a ratio to the video frame size. These extensions allow our system to adapt particularly well in the wild by learning how to aggregate information of multiple identities, which is usually disregarded by other methods in the literature. It achieves state-of-the-art results on the ForgeryNet dataset with an improvement of up to 14% AUC in videos containing multiple people and demonstrates ample generalization capabilities in cross-forgery and cross-dataset settings. The code is publicly available at https://github.com/davide-coccomini/MINTIME-Multi-Identity-size-iNvariant-TIMEsformer-for-Video-Deepfake-Detection.
Predicting Tornadoes days ahead with Machine Learning
Aug 11, 2022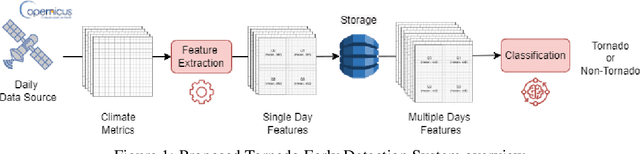


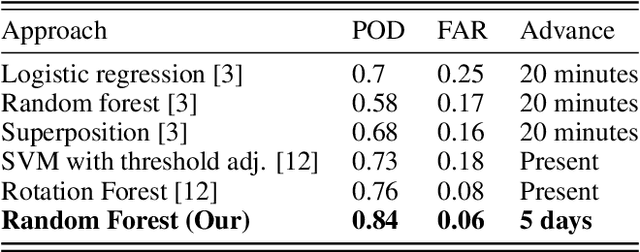
Developing methods to predict disastrous natural phenomena is more important than ever, and tornadoes are among the most dangerous ones in nature. Due to the unpredictability of the weather, counteracting them is not an easy task and today it is mainly carried out by expert meteorologists, who interpret meteorological models. In this paper we propose a system for the early detection of a tornado, validating its effectiveness in a real-world context and exploiting meteorological data collection systems that are already widespread throughout the world. Our system was able to predict tornadoes with a maximum probability of 84% up to five days before the event on a novel dataset of more than 5000 tornadic and non-tornadic events. The dataset and the code to reproduce our results are available at: https://tinyurl.com/3brsfwpk
Cross-Forgery Analysis of Vision Transformers and CNNs for Deepfake Image Detection
Jun 28, 2022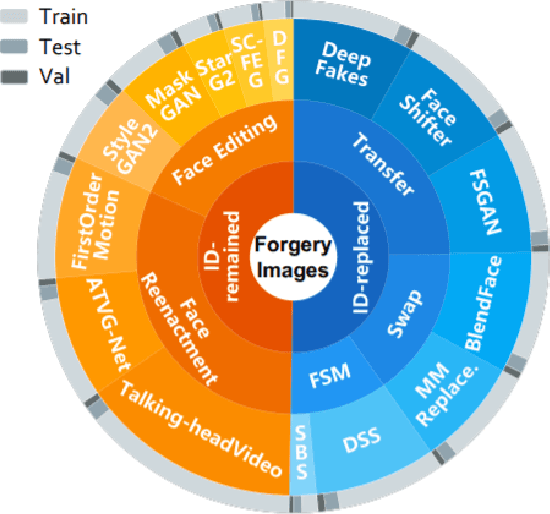
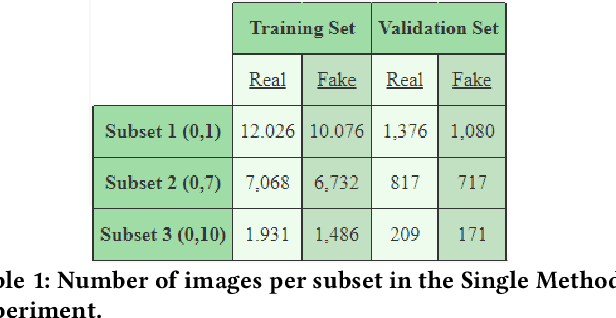

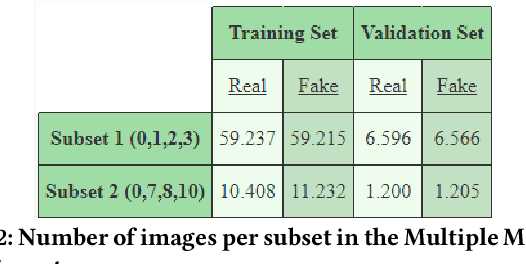
Deepfake Generation Techniques are evolving at a rapid pace, making it possible to create realistic manipulated images and videos and endangering the serenity of modern society. The continual emergence of new and varied techniques brings with it a further problem to be faced, namely the ability of deepfake detection models to update themselves promptly in order to be able to identify manipulations carried out using even the most recent methods. This is an extremely complex problem to solve, as training a model requires large amounts of data, which are difficult to obtain if the deepfake generation method is too recent. Moreover, continuously retraining a network would be unfeasible. In this paper, we ask ourselves if, among the various deep learning techniques, there is one that is able to generalise the concept of deepfake to such an extent that it does not remain tied to one or more specific deepfake generation methods used in the training set. We compared a Vision Transformer with an EfficientNetV2 on a cross-forgery context based on the ForgeryNet dataset. From our experiments, It emerges that EfficientNetV2 has a greater tendency to specialize often obtaining better results on training methods while Vision Transformers exhibit a superior generalization ability that makes them more competent even on images generated with new methodologies.
Transformer-Based Multi-modal Proposal and Re-Rank for Wikipedia Image-Caption Matching
Jun 21, 2022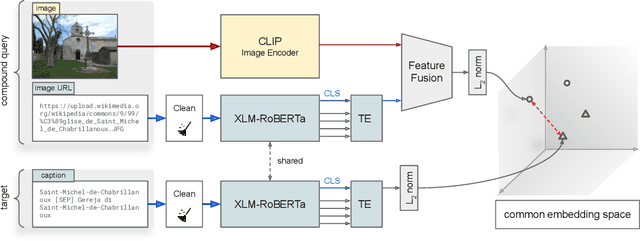
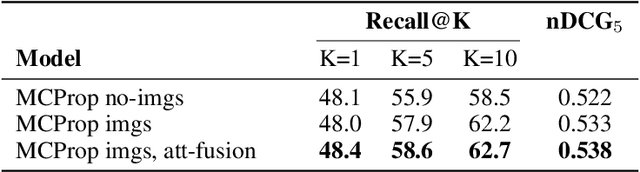
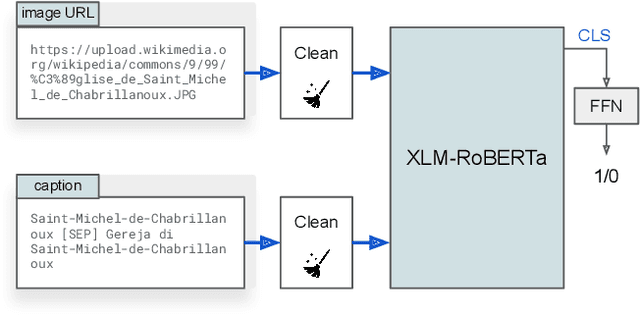
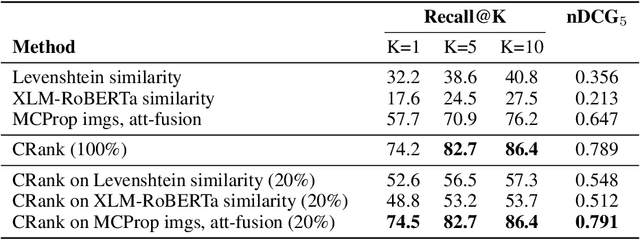
With the increased accessibility of web and online encyclopedias, the amount of data to manage is constantly increasing. In Wikipedia, for example, there are millions of pages written in multiple languages. These pages contain images that often lack the textual context, remaining conceptually floating and therefore harder to find and manage. In this work, we present the system we designed for participating in the Wikipedia Image-Caption Matching challenge on Kaggle, whose objective is to use data associated with images (URLs and visual data) to find the correct caption among a large pool of available ones. A system able to perform this task would improve the accessibility and completeness of multimedia content on large online encyclopedias. Specifically, we propose a cascade of two models, both powered by the recent Transformer model, able to efficiently and effectively infer a relevance score between the query image data and the captions. We verify through extensive experimentation that the proposed two-model approach is an effective way to handle a large pool of images and captions while maintaining bounded the overall computational complexity at inference time. Our approach achieves remarkable results, obtaining a normalized Discounted Cumulative Gain (nDCG) value of 0.53 on the private leaderboard of the Kaggle challenge.