 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTGIF2: Extended Text-Guided Inpainting Forgery Dataset & Benchmark
Mar 30, 2026Generative AI has made text-guided inpainting a powerful image editing tool, but at the same time a growing challenge for media forensics. Existing benchmarks, including our text-guided inpainting forgery (TGIF) dataset, show that image forgery localization (IFL) methods can localize manipulations in spliced images but struggle not in fully regenerated (FR) images, while synthetic image detection (SID) methods can detect fully regenerated images but cannot perform localization. With new generative inpainting models emerging and the open problem of localization in FR images remaining, updated datasets and benchmarks are needed. We introduce TGIF2, an extended version of TGIF, that captures recent advances in text-guided inpainting and enables a deeper analysis of forensic robustness. TGIF2 augments the original dataset with edits generated by FLUX.1 models, as well as with random non-semantic masks. Using the TGIF2 dataset, we conduct a forensic evaluation spanning IFL and SID, including fine-tuning IFL methods on FR images and generative super-resolution attacks. Our experiments show that both IFL and SID methods degrade on FLUX.1 manipulations, highlighting limited generalization. Additionally, while fine-tuning improves localization on FR images, evaluation with random non-semantic masks reveals object bias. Furthermore, generative super-resolution significantly weakens forensic traces, demonstrating that common image enhancement operations can undermine current forensic pipelines. In summary, TGIF2 provides an updated dataset and benchmark, which enables new insights into the challenges posed by modern inpainting and AI-based image enhancements. TGIF2 is available at https://github.com/IDLabMedia/tgif-dataset.
"Humor, Art, or Misinformation?": A Multimodal Dataset for Intent-Aware Synthetic Image Detection
Aug 28, 2025Recent advances in multimodal AI have enabled progress in detecting synthetic and out-of-context content. However, existing efforts largely overlook the intent behind AI-generated images. To fill this gap, we introduce S-HArM, a multimodal dataset for intent-aware classification, comprising 9,576 "in the wild" image-text pairs from Twitter/X and Reddit, labeled as Humor/Satire, Art, or Misinformation. Additionally, we explore three prompting strategies (image-guided, description-guided, and multimodally-guided) to construct a large-scale synthetic training dataset with Stable Diffusion. We conduct an extensive comparative study including modality fusion, contrastive learning, reconstruction networks, attention mechanisms, and large vision-language models. Our results show that models trained on image- and multimodally-guided data generalize better to "in the wild" content, due to preserved visual context. However, overall performance remains limited, highlighting the complexity of inferring intent and the need for specialized architectures.
Improving Generalization in Deepfake Detection with Face Foundation Models and Metric Learning
Aug 27, 2025
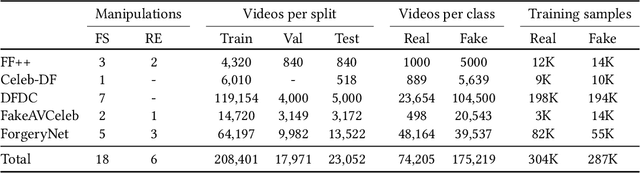

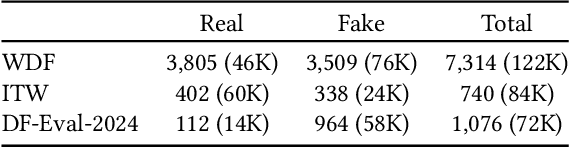
The increasing realism and accessibility of deepfakes have raised critical concerns about media authenticity and information integrity. Despite recent advances, deepfake detection models often struggle to generalize beyond their training distributions, particularly when applied to media content found in the wild. In this work, we present a robust video deepfake detection framework with strong generalization that takes advantage of the rich facial representations learned by face foundation models. Our method is built on top of FSFM, a self-supervised model trained on real face data, and is further fine-tuned using an ensemble of deepfake datasets spanning both face-swapping and face-reenactment manipulations. To enhance discriminative power, we incorporate triplet loss variants during training, guiding the model to produce more separable embeddings between real and fake samples. Additionally, we explore attribution-based supervision schemes, where deepfakes are categorized by manipulation type or source dataset, to assess their impact on generalization. Extensive experiments across diverse evaluation benchmarks demonstrate the effectiveness of our approach, especially in challenging real-world scenarios.
Composite Data Augmentations for Synthetic Image Detection Against Real-World Perturbations
Jun 13, 2025The advent of accessible Generative AI tools enables anyone to create and spread synthetic images on social media, often with the intention to mislead, thus posing a significant threat to online information integrity. Most existing Synthetic Image Detection (SID) solutions struggle on generated images sourced from the Internet, as these are often altered by compression and other operations. To address this, our research enhances SID by exploring data augmentation combinations, leveraging a genetic algorithm for optimal augmentation selection, and introducing a dual-criteria optimization approach. These methods significantly improve model performance under real-world perturbations. Our findings provide valuable insights for developing detection models capable of identifying synthetic images across varying qualities and transformations, with the best-performing model achieving a mean average precision increase of +22.53% compared to models without augmentations. The implementation is available at github.com/efthimia145/sid-composite-data-augmentation.
Few-Shot Class-Incremental Learning For Efficient SAR Automatic Target Recognition
May 26, 2025Synthetic aperture radar automatic target recognition (SAR-ATR) systems have rapidly evolved to tackle incremental recognition challenges in operational settings. Data scarcity remains a major hurdle that conventional SAR-ATR techniques struggle to address. To cope with this challenge, we propose a few-shot class-incremental learning (FSCIL) framework based on a dual-branch architecture that focuses on local feature extraction and leverages the discrete Fourier transform and global filters to capture long-term spatial dependencies. This incorporates a lightweight cross-attention mechanism that fuses domain-specific features with global dependencies to ensure robust feature interaction, while maintaining computational efficiency by introducing minimal scale-shift parameters. The framework combines focal loss for class distinction under imbalance and center loss for compact intra-class distributions to enhance class separation boundaries. Experimental results on the MSTAR benchmark dataset demonstrate that the proposed framework consistently outperforms state-of-the-art methods in FSCIL SAR-ATR, attesting to its effectiveness in real-world scenarios.
A Brief Review for Compression and Transfer Learning Techniques in DeepFake Detection
Apr 29, 2025Training and deploying deepfake detection models on edge devices offers the advantage of maintaining data privacy and confidentiality by processing it close to its source. However, this approach is constrained by the limited computational and memory resources available at the edge. To address this challenge, we explore compression techniques to reduce computational demands and inference time, alongside transfer learning methods to minimize training overhead. Using the Synthbuster, RAISE, and ForenSynths datasets, we evaluate the effectiveness of pruning, knowledge distillation (KD), quantization, fine-tuning, and adapter-based techniques. Our experimental results demonstrate that both compression and transfer learning can be effectively achieved, even with a high compression level of 90%, remaining at the same performance level when the training and validation data originate from the same DeepFake model. However, when the testing dataset is generated by DeepFake models not present in the training set, a domain generalization issue becomes evident.
Latent Multimodal Reconstruction for Misinformation Detection
Apr 08, 2025Multimodal misinformation, such as miscaptioned images, where captions misrepresent an image's origin, context, or meaning, poses a growing challenge in the digital age. To support fact-checkers, researchers have been focusing on creating datasets and developing methods for multimodal misinformation detection (MMD). Due to the scarcity of large-scale annotated MMD datasets, recent studies leverage synthetic training data via out-of-context image-caption pairs or named entity manipulations; altering names, dates, and locations. However, these approaches often produce simplistic misinformation that fails to reflect real-world complexity, limiting the robustness of detection models trained on them. Meanwhile, despite recent advancements, Large Vision-Language Models (LVLMs) remain underutilized for generating diverse, realistic synthetic training data for MMD. To address this gap, we introduce "MisCaption This!", a training dataset comprising LVLM-generated miscaptioned images. Additionally, we introduce "Latent Multimodal Reconstruction" (LAMAR), a network trained to reconstruct the embeddings of truthful captions, providing a strong auxiliary signal to the detection process. To optimize LAMAR, we explore different training strategies (end-to-end training and large-scale pre-training) and integration approaches (direct, mask, gate, and attention). Extensive experiments show that models trained on "MisCaption This!" generalize better on real-world misinformation, while LAMAR sets new state-of-the-art on both NewsCLIPpings and VERITE benchmarks; highlighting the potential of LVLM-generated data and reconstruction-based approaches for advancing MMD. We release our code at: https://github.com/stevejpapad/miscaptioned-image-reconstruction
A Large-scale AI-generated Image Inpainting Benchmark
Feb 10, 2025



Recent advances in generative models enable highly realistic image manipulations, creating an urgent need for robust forgery detection methods. Current datasets for training and evaluating these methods are limited in scale and diversity. To address this, we propose a methodology for creating high-quality inpainting datasets and apply it to create DiQuID, comprising over 95,000 inpainted images generated from 78,000 original images sourced from MS-COCO, RAISE, and OpenImages. Our methodology consists of three components: (1) Semantically Aligned Object Replacement (SAOR) that identifies suitable objects through instance segmentation and generates contextually appropriate prompts, (2) Multiple Model Image Inpainting (MMII) that employs various state-of-the-art inpainting pipelines primarily based on diffusion models to create diverse manipulations, and (3) Uncertainty-Guided Deceptiveness Assessment (UGDA) that evaluates image realism through comparative analysis with originals. The resulting dataset surpasses existing ones in diversity, aesthetic quality, and technical quality. We provide comprehensive benchmarking results using state-of-the-art forgery detection methods, demonstrating the dataset's effectiveness in evaluating and improving detection algorithms. Through a human study with 42 participants on 1,000 images, we show that while humans struggle with images classified as deceiving by our methodology, models trained on our dataset maintain high performance on these challenging cases. Code and dataset are available at https://github.com/mever-team/DiQuID.
FaceX: Understanding Face Attribute Classifiers through Summary Model Explanations
Dec 10, 2024



EXplainable Artificial Intelligence (XAI) approaches are widely applied for identifying fairness issues in Artificial Intelligence (AI) systems. However, in the context of facial analysis, existing XAI approaches, such as pixel attribution methods, offer explanations for individual images, posing challenges in assessing the overall behavior of a model, which would require labor-intensive manual inspection of a very large number of instances and leaving to the human the task of drawing a general impression of the model behavior from the individual outputs. Addressing this limitation, we introduce FaceX, the first method that provides a comprehensive understanding of face attribute classifiers through summary model explanations. Specifically, FaceX leverages the presence of distinct regions across all facial images to compute a region-level aggregation of model activations, allowing for the visualization of the model's region attribution across 19 predefined regions of interest in facial images, such as hair, ears, or skin. Beyond spatial explanations, FaceX enhances interpretability by visualizing specific image patches with the highest impact on the model's decisions for each facial region within a test benchmark. Through extensive evaluation in various experimental setups, including scenarios with or without intentional biases and mitigation efforts on four benchmarks, namely CelebA, FairFace, CelebAMask-HQ, and Racial Faces in the Wild, FaceX demonstrates high effectiveness in identifying the models' biases.
MAVias: Mitigate any Visual Bias
Dec 09, 2024Mitigating biases in computer vision models is an essential step towards the trustworthiness of artificial intelligence models. Existing bias mitigation methods focus on a small set of predefined biases, limiting their applicability in visual datasets where multiple, possibly unknown biases exist. To address this limitation, we introduce MAVias, an open-set bias mitigation approach leveraging foundation models to discover spurious associations between visual attributes and target classes. MAVias first captures a wide variety of visual features in natural language via a foundation image tagging model, and then leverages a large language model to select those visual features defining the target class, resulting in a set of language-coded potential visual biases. We then translate this set of potential biases into vision-language embeddings and introduce an in-processing bias mitigation approach to prevent the model from encoding information related to them. Our experiments on diverse datasets, including CelebA, Waterbirds, ImageNet, and UrbanCars, show that MAVias effectively detects and mitigates a wide range of biases in visual recognition tasks outperforming current state-of-the-art.