 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTGIF2: Extended Text-Guided Inpainting Forgery Dataset & Benchmark
Mar 30, 2026Generative AI has made text-guided inpainting a powerful image editing tool, but at the same time a growing challenge for media forensics. Existing benchmarks, including our text-guided inpainting forgery (TGIF) dataset, show that image forgery localization (IFL) methods can localize manipulations in spliced images but struggle not in fully regenerated (FR) images, while synthetic image detection (SID) methods can detect fully regenerated images but cannot perform localization. With new generative inpainting models emerging and the open problem of localization in FR images remaining, updated datasets and benchmarks are needed. We introduce TGIF2, an extended version of TGIF, that captures recent advances in text-guided inpainting and enables a deeper analysis of forensic robustness. TGIF2 augments the original dataset with edits generated by FLUX.1 models, as well as with random non-semantic masks. Using the TGIF2 dataset, we conduct a forensic evaluation spanning IFL and SID, including fine-tuning IFL methods on FR images and generative super-resolution attacks. Our experiments show that both IFL and SID methods degrade on FLUX.1 manipulations, highlighting limited generalization. Additionally, while fine-tuning improves localization on FR images, evaluation with random non-semantic masks reveals object bias. Furthermore, generative super-resolution significantly weakens forensic traces, demonstrating that common image enhancement operations can undermine current forensic pipelines. In summary, TGIF2 provides an updated dataset and benchmark, which enables new insights into the challenges posed by modern inpainting and AI-based image enhancements. TGIF2 is available at https://github.com/IDLabMedia/tgif-dataset.
A Large-scale AI-generated Image Inpainting Benchmark
Feb 10, 2025



Recent advances in generative models enable highly realistic image manipulations, creating an urgent need for robust forgery detection methods. Current datasets for training and evaluating these methods are limited in scale and diversity. To address this, we propose a methodology for creating high-quality inpainting datasets and apply it to create DiQuID, comprising over 95,000 inpainted images generated from 78,000 original images sourced from MS-COCO, RAISE, and OpenImages. Our methodology consists of three components: (1) Semantically Aligned Object Replacement (SAOR) that identifies suitable objects through instance segmentation and generates contextually appropriate prompts, (2) Multiple Model Image Inpainting (MMII) that employs various state-of-the-art inpainting pipelines primarily based on diffusion models to create diverse manipulations, and (3) Uncertainty-Guided Deceptiveness Assessment (UGDA) that evaluates image realism through comparative analysis with originals. The resulting dataset surpasses existing ones in diversity, aesthetic quality, and technical quality. We provide comprehensive benchmarking results using state-of-the-art forgery detection methods, demonstrating the dataset's effectiveness in evaluating and improving detection algorithms. Through a human study with 42 participants on 1,000 images, we show that while humans struggle with images classified as deceiving by our methodology, models trained on our dataset maintain high performance on these challenging cases. Code and dataset are available at https://github.com/mever-team/DiQuID.
Any-Resolution AI-Generated Image Detection by Spectral Learning
Nov 28, 2024



Recent works have established that AI models introduce spectral artifacts into generated images and propose approaches for learning to capture them using labeled data. However, the significant differences in such artifacts among different generative models hinder these approaches from generalizing to generators not seen during training. In this work, we build upon the key idea that the spectral distribution of real images constitutes both an invariant and highly discriminative pattern for AI-generated image detection. To model this under a self-supervised setup, we employ masked spectral learning using the pretext task of frequency reconstruction. Since generated images constitute out-of-distribution samples for this model, we propose spectral reconstruction similarity to capture this divergence. Moreover, we introduce spectral context attention, which enables our approach to efficiently capture subtle spectral inconsistencies in images of any resolution. Our spectral AI-generated image detection approach (SPAI) achieves a 5.5% absolute improvement in AUC over the previous state-of-the-art across 13 recent generative approaches, while exhibiting robustness against common online perturbations.
Evolution of Detection Performance throughout the Online Lifespan of Synthetic Images
Aug 21, 2024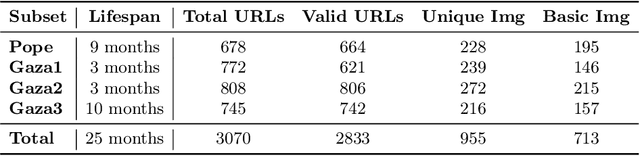



Synthetic images disseminated online significantly differ from those used during the training and evaluation of the state-of-the-art detectors. In this work, we analyze the performance of synthetic image detectors as deceptive synthetic images evolve throughout their online lifespan. Our study reveals that, despite advancements in the field, current state-of-the-art detectors struggle to distinguish between synthetic and real images in the wild. Moreover, we show that the time elapsed since the initial online appearance of a synthetic image negatively affects the performance of most detectors. Ultimately, by employing a retrieval-assisted detection approach, we demonstrate the feasibility to maintain initial detection performance throughout the whole online lifespan of an image and enhance the average detection efficacy across several state-of-the-art detectors by 6.7% and 7.8% for balanced accuracy and AUC metrics, respectively.
TGIF: Text-Guided Inpainting Forgery Dataset
Jul 16, 2024


Digital image manipulation has become increasingly accessible and realistic with the advent of generative AI technologies. Recent developments allow for text-guided inpainting, making sophisticated image edits possible with minimal effort. This poses new challenges for digital media forensics. For example, diffusion model-based approaches could either splice the inpainted region into the original image, or regenerate the entire image. In the latter case, traditional image forgery localization (IFL) methods typically fail. This paper introduces the Text-Guided Inpainting Forgery (TGIF) dataset, a comprehensive collection of images designed to support the training and evaluation of image forgery localization and synthetic image detection (SID) methods. The TGIF dataset includes approximately 80k forged images, originating from popular open-source and commercial methods; SD2, SDXL, and Adobe Firefly. Using this data, we benchmark several state-of-the-art IFL and SID methods. Whereas traditional IFL methods can detect spliced images, they fail to detect regenerated inpainted images. Moreover, traditional SID may detect the regenerated inpainted images to be fake, but cannot localize the inpainted area. Finally, both types of methods fail when exposed to stronger compression, while they are less robust to modern compression algorithms, such as WEBP. As such, this work demonstrates the inefficiency of state-of-the-art detectors on local manipulations performed by modern generative approaches, and aspires to help with the development of more capable IFL and SID methods. The dataset can be downloaded at https://github.com/IDLabMedia/tgif-dataset.
Fusion Transformer with Object Mask Guidance for Image Forgery Analysis
Mar 18, 2024
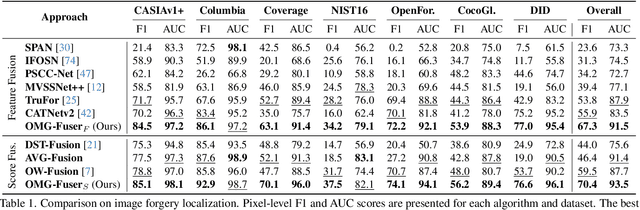
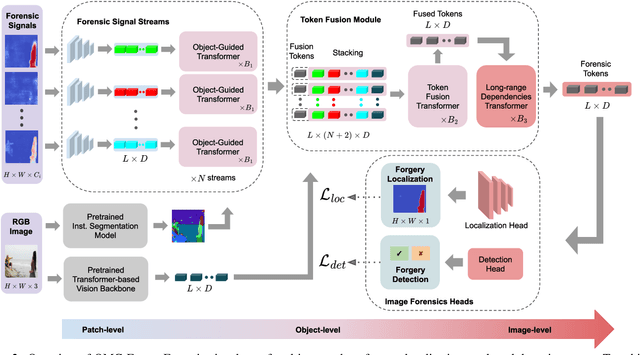
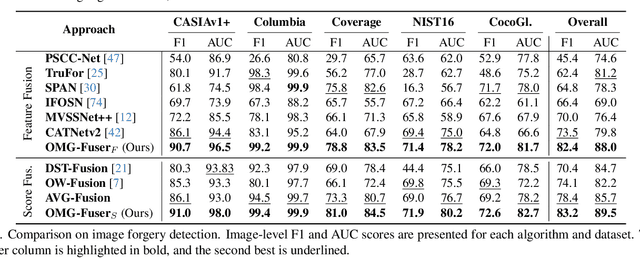
In this work, we introduce OMG-Fuser, a fusion transformer-based network designed to extract information from various forensic signals to enable robust image forgery detection and localization. Our approach can operate with an arbitrary number of forensic signals and leverages object information for their analysis -- unlike previous methods that rely on fusion schemes with few signals and often disregard image semantics. To this end, we design a forensic signal stream composed of a transformer guided by an object attention mechanism, associating patches that depict the same objects. In that way, we incorporate object-level information from the image. Each forensic signal is processed by a different stream that adapts to its peculiarities. Subsequently, a token fusion transformer efficiently aggregates the outputs of an arbitrary number of network streams and generates a fused representation for each image patch. These representations are finally processed by a long-range dependencies transformer that captures the intrinsic relations between the image patches. We assess two fusion variants on top of the proposed approach: (i) score-level fusion that fuses the outputs of multiple image forensics algorithms and (ii) feature-level fusion that fuses low-level forensic traces directly. Both variants exceed state-of-the-art performance on seven datasets for image forgery detection and localization, with a relative average improvement of 12.1% and 20.4% in terms of F1. Our network demonstrates robustness against traditional and novel forgery attacks and can be expanded with new signals without training from scratch.