 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaceX: Understanding Face Attribute Classifiers through Summary Model Explanations
Dec 10, 2024



EXplainable Artificial Intelligence (XAI) approaches are widely applied for identifying fairness issues in Artificial Intelligence (AI) systems. However, in the context of facial analysis, existing XAI approaches, such as pixel attribution methods, offer explanations for individual images, posing challenges in assessing the overall behavior of a model, which would require labor-intensive manual inspection of a very large number of instances and leaving to the human the task of drawing a general impression of the model behavior from the individual outputs. Addressing this limitation, we introduce FaceX, the first method that provides a comprehensive understanding of face attribute classifiers through summary model explanations. Specifically, FaceX leverages the presence of distinct regions across all facial images to compute a region-level aggregation of model activations, allowing for the visualization of the model's region attribution across 19 predefined regions of interest in facial images, such as hair, ears, or skin. Beyond spatial explanations, FaceX enhances interpretability by visualizing specific image patches with the highest impact on the model's decisions for each facial region within a test benchmark. Through extensive evaluation in various experimental setups, including scenarios with or without intentional biases and mitigation efforts on four benchmarks, namely CelebA, FairFace, CelebAMask-HQ, and Racial Faces in the Wild, FaceX demonstrates high effectiveness in identifying the models' biases.
MAVias: Mitigate any Visual Bias
Dec 09, 2024Mitigating biases in computer vision models is an essential step towards the trustworthiness of artificial intelligence models. Existing bias mitigation methods focus on a small set of predefined biases, limiting their applicability in visual datasets where multiple, possibly unknown biases exist. To address this limitation, we introduce MAVias, an open-set bias mitigation approach leveraging foundation models to discover spurious associations between visual attributes and target classes. MAVias first captures a wide variety of visual features in natural language via a foundation image tagging model, and then leverages a large language model to select those visual features defining the target class, resulting in a set of language-coded potential visual biases. We then translate this set of potential biases into vision-language embeddings and introduce an in-processing bias mitigation approach to prevent the model from encoding information related to them. Our experiments on diverse datasets, including CelebA, Waterbirds, ImageNet, and UrbanCars, show that MAVias effectively detects and mitigates a wide range of biases in visual recognition tasks outperforming current state-of-the-art.
BAdd: Bias Mitigation through Bias Addition
Aug 21, 2024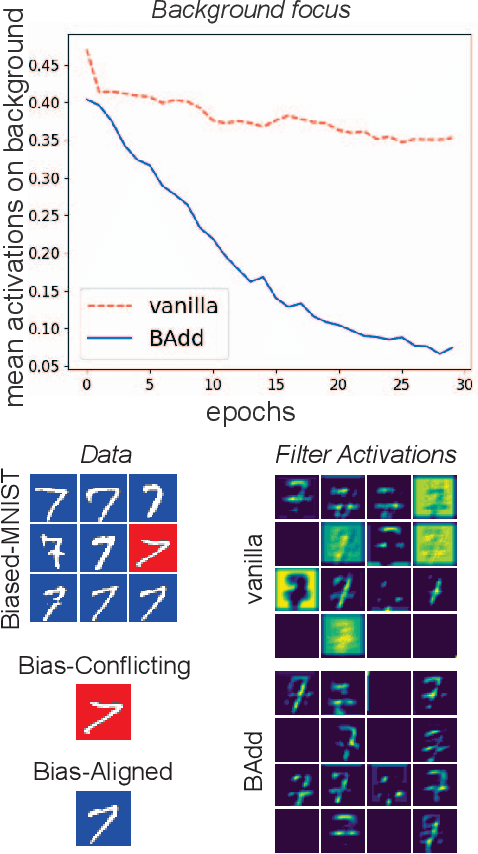

Computer vision (CV) datasets often exhibit biases that are perpetuated by deep learning models. While recent efforts aim to mitigate these biases and foster fair representations, they fail in complex real-world scenarios. In particular, existing methods excel in controlled experiments involving benchmarks with single-attribute injected biases, but struggle with multi-attribute biases being present in well-established CV datasets. Here, we introduce BAdd, a simple yet effective method that allows for learning fair representations invariant to the attributes introducing bias by incorporating features representing these attributes into the backbone. BAdd is evaluated on seven benchmarks and exhibits competitive performance, surpassing state-of-the-art methods on both single- and multi-attribute benchmarks. Notably, BAdd achieves +27.5% and +5.5% absolute accuracy improvements on the challenging multi-attribute benchmarks, FB-Biased-MNIST and CelebA, respectively.
SDFD: Building a Versatile Synthetic Face Image Dataset with Diverse Attributes
Apr 29, 2024



AI systems rely on extensive training on large datasets to address various tasks. However, image-based systems, particularly those used for demographic attribute prediction, face significant challenges. Many current face image datasets primarily focus on demographic factors such as age, gender, and skin tone, overlooking other crucial facial attributes like hairstyle and accessories. This narrow focus limits the diversity of the data and consequently the robustness of AI systems trained on them. This work aims to address this limitation by proposing a methodology for generating synthetic face image datasets that capture a broader spectrum of facial diversity. Specifically, our approach integrates a systematic prompt formulation strategy, encompassing not only demographics and biometrics but also non-permanent traits like make-up, hairstyle, and accessories. These prompts guide a state-of-the-art text-to-image model in generating a comprehensive dataset of high-quality realistic images and can be used as an evaluation set in face analysis systems. Compared to existing datasets, our proposed dataset proves equally or more challenging in image classification tasks while being much smaller in size.
FRCSyn Challenge at WACV 2024:Face Recognition Challenge in the Era of Synthetic Data
Nov 17, 2023



Despite the widespread adoption of face recognition technology around the world, and its remarkable performance on current benchmarks, there are still several challenges that must be covered in more detail. This paper offers an overview of the Face Recognition Challenge in the Era of Synthetic Data (FRCSyn) organized at WACV 2024. This is the first international challenge aiming to explore the use of synthetic data in face recognition to address existing limitations in the technology. Specifically, the FRCSyn Challenge targets concerns related to data privacy issues, demographic biases, generalization to unseen scenarios, and performance limitations in challenging scenarios, including significant age disparities between enrollment and testing, pose variations, and occlusions. The results achieved in the FRCSyn Challenge, together with the proposed benchmark, contribute significantly to the application of synthetic data to improve face recognition technology.
Mitigating Viewer Impact from Disturbing Imagery using AI Filters: A User-Study
Jul 19, 2023Exposure to disturbing imagery can significantly impact individuals, especially professionals who encounter such content as part of their work. This paper presents a user study, involving 107 participants, predominantly journalists and human rights investigators, that explores the capability of Artificial Intelligence (AI)-based image filters to potentially mitigate the emotional impact of viewing such disturbing content. We tested five different filter styles, both traditional (Blurring and Partial Blurring) and AI-based (Drawing, Colored Drawing, and Painting), and measured their effectiveness in terms of conveying image information while reducing emotional distress. Our findings suggest that the AI-based Drawing style filter demonstrates the best performance, offering a promising solution for reducing negative feelings (-30.38%) while preserving the interpretability of the image (97.19%). Despite the requirement for many professionals to eventually inspect the original images, participants suggested potential strategies for integrating AI filters into their workflow, such as using AI filters as an initial, preparatory step before viewing the original image. Overall, this paper contributes to the development of a more ethically considerate and effective visual environment for professionals routinely engaging with potentially disturbing imagery.
Towards Fair Face Verification: An In-depth Analysis of Demographic Biases
Jul 19, 2023
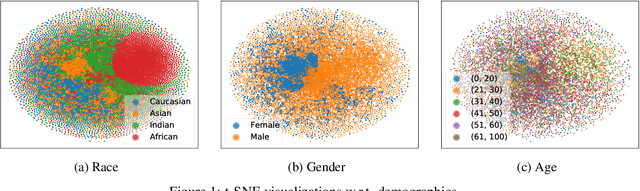
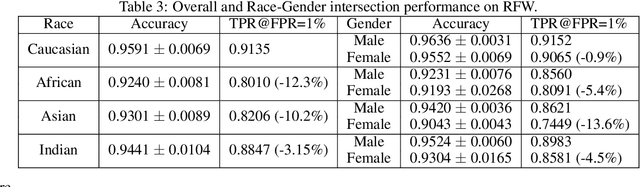

Deep learning-based person identification and verification systems have remarkably improved in terms of accuracy in recent years; however, such systems, including widely popular cloud-based solutions, have been found to exhibit significant biases related to race, age, and gender, a problem that requires in-depth exploration and solutions. This paper presents an in-depth analysis, with a particular emphasis on the intersectionality of these demographic factors. Intersectional bias refers to the performance discrepancies w.r.t. the different combinations of race, age, and gender groups, an area relatively unexplored in current literature. Furthermore, the reliance of most state-of-the-art approaches on accuracy as the principal evaluation metric often masks significant demographic disparities in performance. To counter this crucial limitation, we incorporate five additional metrics in our quantitative analysis, including disparate impact and mistreatment metrics, which are typically ignored by the relevant fairness-aware approaches. Results on the Racial Faces in-the-Wild (RFW) benchmark indicate pervasive biases in face recognition systems, extending beyond race, with different demographic factors yielding significantly disparate outcomes. In particular, Africans demonstrate an 11.25% lower True Positive Rate (TPR) compared to Caucasians, while only a 3.51% accuracy drop is observed. Even more concerning, the intersections of multiple protected groups, such as African females over 60 years old, demonstrate a +39.89% disparate mistreatment rate compared to the highest Caucasians rate. By shedding light on these biases and their implications, this paper aims to stimulate further research towards developing fairer, more equitable face recognition and verification systems.
FLAC: Fairness-Aware Representation Learning by Suppressing Attribute-Class Associations
Apr 27, 2023Bias in computer vision systems can perpetuate or even amplify discrimination against certain populations. Considering that bias is often introduced by biased visual datasets, many recent research efforts focus on training fair models using such data. However, most of them heavily rely on the availability of protected attribute labels in the dataset, which limits their applicability, while label-unaware approaches, i.e., approaches operating without such labels, exhibit considerably lower performance. To overcome these limitations, this work introduces FLAC, a methodology that minimizes mutual information between the features extracted by the model and a protected attribute, without the use of attribute labels. To do that, FLAC proposes a sampling strategy that highlights underrepresented samples in the dataset, and casts the problem of learning fair representations as a probability matching problem that leverages representations extracted by a bias-capturing classifier. It is theoretically shown that FLAC can indeed lead to fair representations, that are independent of the protected attributes. FLAC surpasses the current state-of-the-art on Biased MNIST, CelebA, and UTKFace, by 29.1%, 18.1%, and 21.9%, respectively. Additionally, FLAC exhibits 2.2% increased accuracy on ImageNet-A consisting of the most challenging samples of ImageNet. Finally, in most experiments, FLAC even outperforms the bias label-aware state-of-the-art methods.
Leveraging Large-scale Multimedia Datasets to Refine Content Moderation Models
Dec 01, 2022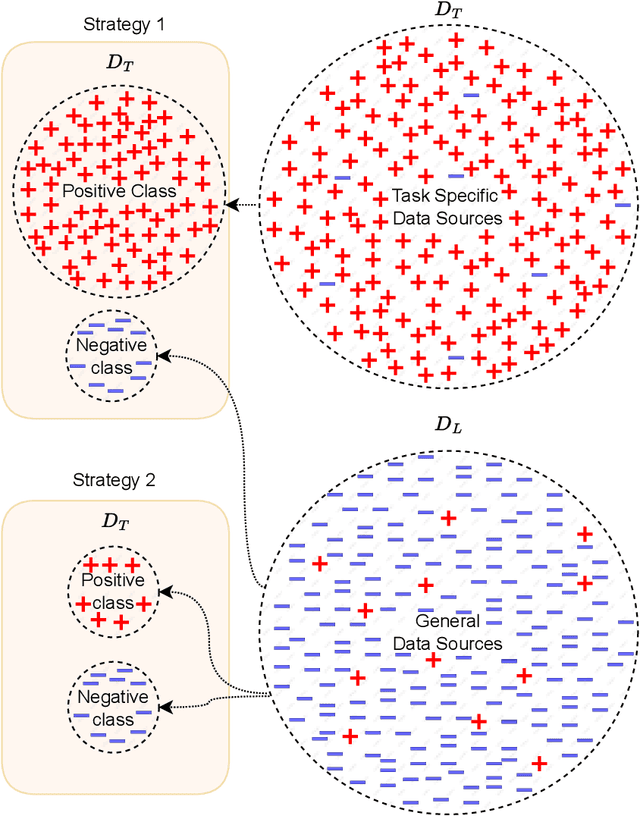



The sheer volume of online user-generated content has rendered content moderation technologies essential in order to protect digital platform audiences from content that may cause anxiety, worry, or concern. Despite the efforts towards developing automated solutions to tackle this problem, creating accurate models remains challenging due to the lack of adequate task-specific training data. The fact that manually annotating such data is a highly demanding procedure that could severely affect the annotators' emotional well-being is directly related to the latter limitation. In this paper, we propose the CM-Refinery framework that leverages large-scale multimedia datasets to automatically extend initial training datasets with hard examples that can refine content moderation models, while significantly reducing the involvement of human annotators. We apply our method on two model adaptation strategies designed with respect to the different challenges observed while collecting data, i.e. lack of (i) task-specific negative data or (ii) both positive and negative data. Additionally, we introduce a diversity criterion applied to the data collection process that further enhances the generalization performance of the refined models. The proposed method is evaluated on the Not Safe for Work (NSFW) and disturbing content detection tasks on benchmark datasets achieving 1.32% and 1.94% accuracy improvements compared to the state of the art, respectively. Finally, it significantly reduces human involvement, as 92.54% of data are automatically annotated in case of disturbing content while no human intervention is required for the NSFW task.
InDistill: Transferring Knowledge From Pruned Intermediate Layers
May 20, 2022

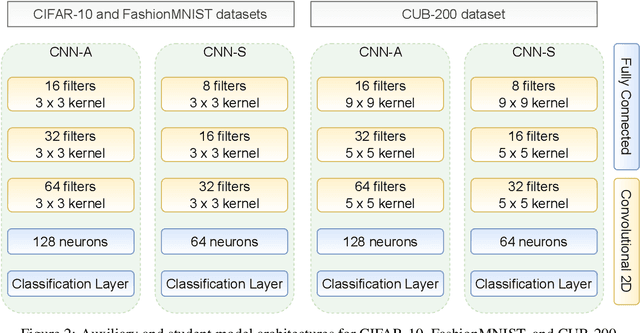

Deploying deep neural networks on hardware with limited resources, such as smartphones and drones, constitutes a great challenge due to their computational complexity. Knowledge distillation approaches aim at transferring knowledge from a large model to a lightweight one, also known as teacher and student respectively, while distilling the knowledge from intermediate layers provides an additional supervision to that task. The capacity gap between the models, the information encoding that collapses its architectural alignment, and the absence of appropriate learning schemes for transferring multiple layers restrict the performance of existing methods. In this paper, we propose a novel method, termed InDistill, that can drastically improve the performance of existing single-layer knowledge distillation methods by leveraging the properties of channel pruning to both reduce the capacity gap between the models and retain the architectural alignment. Furthermore, we propose a curriculum learning based scheme for enhancing the effectiveness of transferring knowledge from multiple intermediate layers. The proposed method surpasses state-of-the-art performance on three benchmark image datasets.