 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecond FRCSyn-onGoing: Winning Solutions and Post-Challenge Analysis to Improve Face Recognition with Synthetic Data
Dec 02, 2024Synthetic data is gaining increasing popularity for face recognition technologies, mainly due to the privacy concerns and challenges associated with obtaining real data, including diverse scenarios, quality, and demographic groups, among others. It also offers some advantages over real data, such as the large amount of data that can be generated or the ability to customize it to adapt to specific problem-solving needs. To effectively use such data, face recognition models should also be specifically designed to exploit synthetic data to its fullest potential. In order to promote the proposal of novel Generative AI methods and synthetic data, and investigate the application of synthetic data to better train face recognition systems, we introduce the 2nd FRCSyn-onGoing challenge, based on the 2nd Face Recognition Challenge in the Era of Synthetic Data (FRCSyn), originally launched at CVPR 2024. This is an ongoing challenge that provides researchers with an accessible platform to benchmark i) the proposal of novel Generative AI methods and synthetic data, and ii) novel face recognition systems that are specifically proposed to take advantage of synthetic data. We focus on exploring the use of synthetic data both individually and in combination with real data to solve current challenges in face recognition such as demographic bias, domain adaptation, and performance constraints in demanding situations, such as age disparities between training and testing, changes in the pose, or occlusions. Very interesting findings are obtained in this second edition, including a direct comparison with the first one, in which synthetic databases were restricted to DCFace and GANDiffFace.
Second Edition FRCSyn Challenge at CVPR 2024: Face Recognition Challenge in the Era of Synthetic Data
Apr 16, 2024



Synthetic data is gaining increasing relevance for training machine learning models. This is mainly motivated due to several factors such as the lack of real data and intra-class variability, time and errors produced in manual labeling, and in some cases privacy concerns, among others. This paper presents an overview of the 2nd edition of the Face Recognition Challenge in the Era of Synthetic Data (FRCSyn) organized at CVPR 2024. FRCSyn aims to investigate the use of synthetic data in face recognition to address current technological limitations, including data privacy concerns, demographic biases, generalization to novel scenarios, and performance constraints in challenging situations such as aging, pose variations, and occlusions. Unlike the 1st edition, in which synthetic data from DCFace and GANDiffFace methods was only allowed to train face recognition systems, in this 2nd edition we propose new sub-tasks that allow participants to explore novel face generative methods. The outcomes of the 2nd FRCSyn Challenge, along with the proposed experimental protocol and benchmarking contribute significantly to the application of synthetic data to face recognition.
* arXiv admin note: text overlap with arXiv:2311.10476
SDFR: Synthetic Data for Face Recognition Competition
Apr 09, 2024



Large-scale face recognition datasets are collected by crawling the Internet and without individuals' consent, raising legal, ethical, and privacy concerns. With the recent advances in generative models, recently several works proposed generating synthetic face recognition datasets to mitigate concerns in web-crawled face recognition datasets. This paper presents the summary of the Synthetic Data for Face Recognition (SDFR) Competition held in conjunction with the 18th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2024) and established to investigate the use of synthetic data for training face recognition models. The SDFR competition was split into two tasks, allowing participants to train face recognition systems using new synthetic datasets and/or existing ones. In the first task, the face recognition backbone was fixed and the dataset size was limited, while the second task provided almost complete freedom on the model backbone, the dataset, and the training pipeline. The submitted models were trained on existing and also new synthetic datasets and used clever methods to improve training with synthetic data. The submissions were evaluated and ranked on a diverse set of seven benchmarking datasets. The paper gives an overview of the submitted face recognition models and reports achieved performance compared to baseline models trained on real and synthetic datasets. Furthermore, the evaluation of submissions is extended to bias assessment across different demography groups. Lastly, an outlook on the current state of the research in training face recognition models using synthetic data is presented, and existing problems as well as potential future directions are also discussed.
Synthetic Data for the Mitigation of Demographic Biases in Face Recognition
Feb 02, 2024This study investigates the possibility of mitigating the demographic biases that affect face recognition technologies through the use of synthetic data. Demographic biases have the potential to impact individuals from specific demographic groups, and can be identified by observing disparate performance of face recognition systems across demographic groups. They primarily arise from the unequal representations of demographic groups in the training data. In recent times, synthetic data have emerged as a solution to some problems that affect face recognition systems. In particular, during the generation process it is possible to specify the desired demographic and facial attributes of images, in order to control the demographic distribution of the synthesized dataset, and fairly represent the different demographic groups. We propose to fine-tune with synthetic data existing face recognition systems that present some demographic biases. We use synthetic datasets generated with GANDiffFace, a novel framework able to synthesize datasets for face recognition with controllable demographic distribution and realistic intra-class variations. We consider multiple datasets representing different demographic groups for training and evaluation. Also, we fine-tune different face recognition systems, and evaluate their demographic fairness with different metrics. Our results support the proposed approach and the use of synthetic data to mitigate demographic biases in face recognition.
* 8 pages, 3 figures
FRCSyn Challenge at WACV 2024:Face Recognition Challenge in the Era of Synthetic Data
Nov 17, 2023



Despite the widespread adoption of face recognition technology around the world, and its remarkable performance on current benchmarks, there are still several challenges that must be covered in more detail. This paper offers an overview of the Face Recognition Challenge in the Era of Synthetic Data (FRCSyn) organized at WACV 2024. This is the first international challenge aiming to explore the use of synthetic data in face recognition to address existing limitations in the technology. Specifically, the FRCSyn Challenge targets concerns related to data privacy issues, demographic biases, generalization to unseen scenarios, and performance limitations in challenging scenarios, including significant age disparities between enrollment and testing, pose variations, and occlusions. The results achieved in the FRCSyn Challenge, together with the proposed benchmark, contribute significantly to the application of synthetic data to improve face recognition technology.
Exploring Transformers for On-Line Handwritten Signature Verification
Jul 06, 2023


The application of mobile biometrics as a user-friendly authentication method has increased in the last years. Recent studies have proposed novel behavioral biometric recognition systems based on Transformers, which currently outperform the state of the art in several application scenarios. On-line handwritten signature verification aims to verify the identity of subjects, based on their biometric signatures acquired using electronic devices such as tablets or smartphones. This paper investigates the suitability of architectures based on recent Transformers for on-line signature verification. In particular, four different configurations are studied, two of them rely on the Vanilla Transformer encoder, and the two others have been successfully applied to the tasks of gait and activity recognition. We evaluate the four proposed configurations according to the experimental protocol proposed in the SVC-onGoing competition. The results obtained in our experiments are promising, and promote the use of Transformers for on-line signature verification.
GANDiffFace: Controllable Generation of Synthetic Datasets for Face Recognition with Realistic Variations
May 31, 2023



Face recognition systems have significantly advanced in recent years, driven by the availability of large-scale datasets. However, several issues have recently came up, including privacy concerns that have led to the discontinuation of well-established public datasets. Synthetic datasets have emerged as a solution, even though current synthesis methods present other drawbacks such as limited intra-class variations, lack of realism, and unfair representation of demographic groups. This study introduces GANDiffFace, a novel framework for the generation of synthetic datasets for face recognition that combines the power of Generative Adversarial Networks (GANs) and Diffusion models to overcome the limitations of existing synthetic datasets. In GANDiffFace, we first propose the use of GANs to synthesize highly realistic identities and meet target demographic distributions. Subsequently, we fine-tune Diffusion models with the images generated with GANs, synthesizing multiple images of the same identity with a variety of accessories, poses, expressions, and contexts. We generate multiple synthetic datasets by changing GANDiffFace settings, and compare their mated and non-mated score distributions with the distributions provided by popular real-world datasets for face recognition, i.e. VGG2 and IJB-C. Our results show the feasibility of the proposed GANDiffFace, in particular the use of Diffusion models to enhance the (limited) intra-class variations provided by GANs towards the level of real-world datasets.
Benchmarking of Cancelable Biometrics for Deep Templates
Feb 26, 2023In this paper, we benchmark several cancelable biometrics (CB) schemes on different biometric characteristics. We consider BioHashing, Multi-Layer Perceptron (MLP) Hashing, Bloom Filters, and two schemes based on Index-of-Maximum (IoM) Hashing (i.e., IoM-URP and IoM-GRP). In addition to the mentioned CB schemes, we introduce a CB scheme (as a baseline) based on user-specific random transformations followed by binarization. We evaluate the unlinkability, irreversibility, and recognition performance (which are the required criteria by the ISO/IEC 24745 standard) of these CB schemes on deep learning based templates extracted from different physiological and behavioral biometric characteristics including face, voice, finger vein, and iris. In addition, we provide an open-source implementation of all the experiments presented to facilitate the reproducibility of our results.
An Overview of Privacy-enhancing Technologies in Biometric Recognition
Jun 21, 2022



Privacy-enhancing technologies are technologies that implement fundamental data protection principles. With respect to biometric recognition, different types of privacy-enhancing technologies have been introduced for protecting stored biometric data which are generally classified as sensitive. In this regard, various taxonomies and conceptual categorizations have been proposed and standardization activities have been carried out. However, these efforts have mainly been devoted to certain sub-categories of privacy-enhancing technologies and therefore lack generalization. This work provides an overview of concepts of privacy-enhancing technologies for biometrics in a unified framework. Key aspects and differences between existing concepts are highlighted in detail at each processing step. Fundamental properties and limitations of existing approaches are discussed and related to data protection techniques and principles. Moreover, scenarios and methods for the assessment of privacy-enhancing technologies for biometrics are presented. This paper is meant as a point of entry to the field of biometric data protection and is directed towards experienced researchers as well as non-experts.
ECG Biometric Recognition: Review, System Proposal, and Benchmark Evaluation
Apr 08, 2022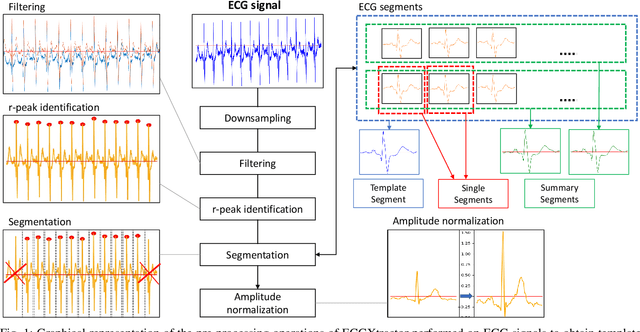



Electrocardiograms (ECGs) have shown unique patterns to distinguish between different subjects and present important advantages compared to other biometric traits, such as difficulty to counterfeit, liveness detection, and ubiquity. Also, with the success of Deep Learning technologies, ECG biometric recognition has received increasing interest in recent years. However, it is not easy to evaluate the improvements of novel ECG proposed methods, mainly due to the lack of public data and standard experimental protocols. In this study, we perform extensive analysis and comparison of different scenarios in ECG biometric recognition. Both verification and identification tasks are investigated, as well as single- and multi-session scenarios. Finally, we also perform single- and multi-lead ECG experiments, considering traditional scenarios using electrodes in the chest and limbs and current user-friendly wearable devices. In addition, we present ECGXtractor, a robust Deep Learning technology trained with an in-house large-scale database and able to operate successfully across various scenarios and multiple databases. We introduce our proposed feature extractor, trained with multiple sinus-rhythm heartbeats belonging to 55,967 subjects, and provide a general public benchmark evaluation with detailed experimental protocol. We evaluate the system performance over four different databases: i) our in-house database, ii) PTB, iii) ECG-ID, and iv) CYBHi. With the widely used PTB database, we achieve Equal Error Rates of 0.14% and 2.06% in verification, and accuracies of 100% and 96.46% in identification, respectively in single- and multi-session analysis. We release the source code, experimental protocol details, and pre-trained models in GitHub to advance in the field.