 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArc2Morph: Identity-Preserving Facial Morphing with Arc2Face
Feb 18, 2026Face morphing attacks are widely recognized as one of the most challenging threats to face recognition systems used in electronic identity documents. These attacks exploit a critical vulnerability in passport enrollment procedures adopted by many countries, where the facial image is often acquired without a supervised live capture process. In this paper, we propose a novel face morphing technique based on Arc2Face, an identity-conditioned face foundation model capable of synthesizing photorealistic facial images from compact identity representations. We demonstrate the effectiveness of the proposed approach by comparing the morphing attack potential metric on two large-scale sequestered face morphing attack detection datasets against several state-of-the-art morphing methods, as well as on two novel morphed face datasets derived from FEI and ONOT. Experimental results show that the proposed deep learning-based approach achieves a morphing attack potential comparable to that of landmark-based techniques, which have traditionally been regarded as the most challenging. These findings confirm the ability of the proposed method to effectively preserve and manage identity information during the morph generation process.
Detecting Localized Deepfakes: How Well Do Synthetic Image Detectors Handle Inpainting?
Dec 18, 2025

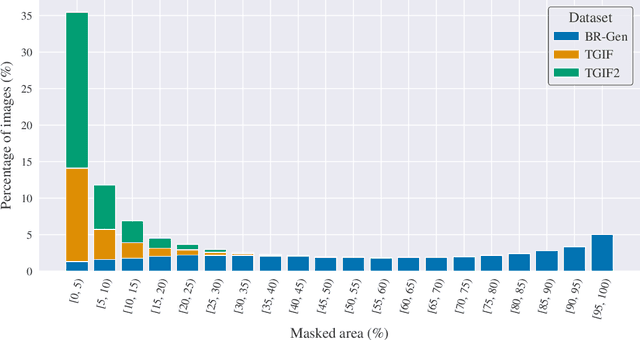
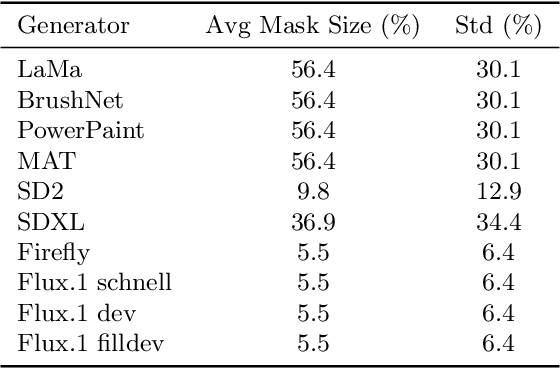
The rapid progress of generative AI has enabled highly realistic image manipulations, including inpainting and region-level editing. These approaches preserve most of the original visual context and are increasingly exploited in cybersecurity-relevant threat scenarios. While numerous detectors have been proposed for identifying fully synthetic images, their ability to generalize to localized manipulations remains insufficiently characterized. This work presents a systematic evaluation of state-of-the-art detectors, originally trained for the deepfake detection on fully synthetic images, when applied to a distinct challenge: localized inpainting detection. The study leverages multiple datasets spanning diverse generators, mask sizes, and inpainting techniques. Our experiments show that models trained on a large set of generators exhibit partial transferability to inpainting-based edits and can reliably detect medium- and large-area manipulations or regeneration-style inpainting, outperforming many existing ad hoc detection approaches.
AI-GenBench: A New Ongoing Benchmark for AI-Generated Image Detection
Apr 29, 2025



The rapid advancement of generative AI has revolutionized image creation, enabling high-quality synthesis from text prompts while raising critical challenges for media authenticity. We present Ai-GenBench, a novel benchmark designed to address the urgent need for robust detection of AI-generated images in real-world scenarios. Unlike existing solutions that evaluate models on static datasets, Ai-GenBench introduces a temporal evaluation framework where detection methods are incrementally trained on synthetic images, historically ordered by their generative models, to test their ability to generalize to new generative models, such as the transition from GANs to diffusion models. Our benchmark focuses on high-quality, diverse visual content and overcomes key limitations of current approaches, including arbitrary dataset splits, unfair comparisons, and excessive computational demands. Ai-GenBench provides a comprehensive dataset, a standardized evaluation protocol, and accessible tools for both researchers and non-experts (e.g., journalists, fact-checkers), ensuring reproducibility while maintaining practical training requirements. By establishing clear evaluation rules and controlled augmentation strategies, Ai-GenBench enables meaningful comparison of detection methods and scalable solutions. Code and data are publicly available to ensure reproducibility and to support the development of robust forensic detectors to keep pace with the rise of new synthetic generators.
From Gaming to Research: GTA V for Synthetic Data Generation for Robotics and Navigations
Feb 17, 2025In computer vision, the development of robust algorithms capable of generalizing effectively in real-world scenarios more and more often requires large-scale datasets collected under diverse environmental conditions. However, acquiring such datasets is time-consuming, costly, and sometimes unfeasible. To address these limitations, the use of synthetic data has gained attention as a viable alternative, allowing researchers to generate vast amounts of data while simulating various environmental contexts in a controlled setting. In this study, we investigate the use of synthetic data in robotics and navigation, specifically focusing on Simultaneous Localization and Mapping (SLAM) and Visual Place Recognition (VPR). In particular, we introduce a synthetic dataset created using the virtual environment of the video game Grand Theft Auto V (GTA V), along with an algorithm designed to generate a VPR dataset, without human supervision. Through a series of experiments centered on SLAM and VPR, we demonstrate that synthetic data derived from GTA V are qualitatively comparable to real-world data. Furthermore, these synthetic data can complement or even substitute real-world data in these applications. This study sets the stage for the creation of large-scale synthetic datasets, offering a cost-effective and scalable solution for future research and development.
ONOT: a High-Quality ICAO-compliant Synthetic Mugshot Dataset
Apr 17, 2024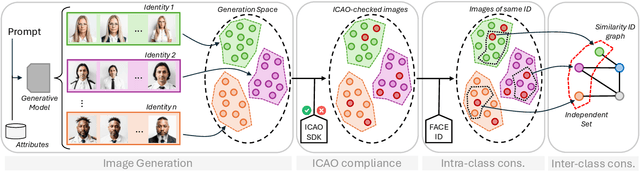



Nowadays, state-of-the-art AI-based generative models represent a viable solution to overcome privacy issues and biases in the collection of datasets containing personal information, such as faces. Following this intuition, in this paper we introduce ONOT, a synthetic dataset specifically focused on the generation of high-quality faces in adherence to the requirements of the ISO/IEC 39794-5 standards that, following the guidelines of the International Civil Aviation Organization (ICAO), defines the interchange formats of face images in electronic Machine-Readable Travel Documents (eMRTD). The strictly controlled and varied mugshot images included in ONOT are useful in research fields related to the analysis of face images in eMRTD, such as Morphing Attack Detection and Face Quality Assessment. The dataset is publicly released, in combination with the generation procedure details in order to improve the reproducibility and enable future extensions.
Dealing with Subject Similarity in Differential Morphing Attack Detection
Apr 11, 2024



The advent of morphing attacks has posed significant security concerns for automated Face Recognition systems, raising the pressing need for robust and effective Morphing Attack Detection (MAD) methods able to effectively address this issue. In this paper, we focus on Differential MAD (D-MAD), where a trusted live capture, usually representing the criminal, is compared with the document image to classify it as morphed or bona fide. We show these approaches based on identity features are effective when the morphed image and the live one are sufficiently diverse; unfortunately, the effectiveness is significantly reduced when the same approaches are applied to look-alike subjects or in all those cases when the similarity between the two compared images is high (e.g. comparison between the morphed image and the accomplice). Therefore, in this paper, we propose ACIdA, a modular D-MAD system, consisting of a module for the attempt type classification, and two modules for the identity and artifacts analysis on input images. Successfully addressing this task would allow broadening the D-MAD applications including, for instance, the document enrollment stage, which currently relies entirely on human evaluation, thus limiting the possibility of releasing ID documents with manipulated images, as well as the automated gates to detect both accomplices and criminals. An extensive cross-dataset experimental evaluation conducted on the introduced scenario shows that ACIdA achieves state-of-the-art results, outperforming literature competitors, while maintaining good performance in traditional D-MAD benchmarks.
V-MAD: Video-based Morphing Attack Detection in Operational Scenarios
Apr 10, 2024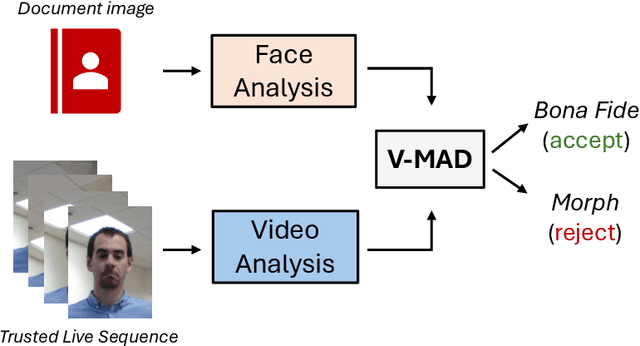

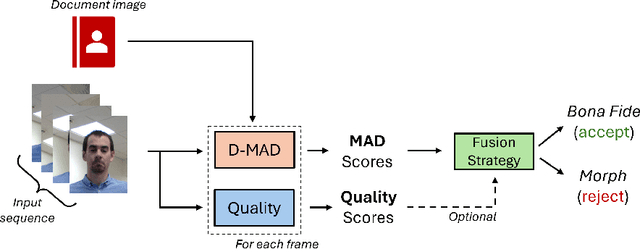

In response to the rising threat of the face morphing attack, this paper introduces and explores the potential of Video-based Morphing Attack Detection (V-MAD) systems in real-world operational scenarios. While current morphing attack detection methods primarily focus on a single or a pair of images, V-MAD is based on video sequences, exploiting the video streams often acquired by face verification tools available, for instance, at airport gates. Through this study, we show for the first time the advantages that the availability of multiple probe frames can bring to the morphing attack detection task, especially in scenarios where the quality of probe images is varied and might be affected, for instance, by pose or illumination variations. Experimental results on a real operational database demonstrate that video sequences represent valuable information for increasing the robustness and performance of morphing attack detection systems.
SDFR: Synthetic Data for Face Recognition Competition
Apr 09, 2024



Large-scale face recognition datasets are collected by crawling the Internet and without individuals' consent, raising legal, ethical, and privacy concerns. With the recent advances in generative models, recently several works proposed generating synthetic face recognition datasets to mitigate concerns in web-crawled face recognition datasets. This paper presents the summary of the Synthetic Data for Face Recognition (SDFR) Competition held in conjunction with the 18th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2024) and established to investigate the use of synthetic data for training face recognition models. The SDFR competition was split into two tasks, allowing participants to train face recognition systems using new synthetic datasets and/or existing ones. In the first task, the face recognition backbone was fixed and the dataset size was limited, while the second task provided almost complete freedom on the model backbone, the dataset, and the training pipeline. The submitted models were trained on existing and also new synthetic datasets and used clever methods to improve training with synthetic data. The submissions were evaluated and ranked on a diverse set of seven benchmarking datasets. The paper gives an overview of the submitted face recognition models and reports achieved performance compared to baseline models trained on real and synthetic datasets. Furthermore, the evaluation of submissions is extended to bias assessment across different demography groups. Lastly, an outlook on the current state of the research in training face recognition models using synthetic data is presented, and existing problems as well as potential future directions are also discussed.
Enabling On-device Continual Learning with Binary Neural Networks
Jan 18, 2024


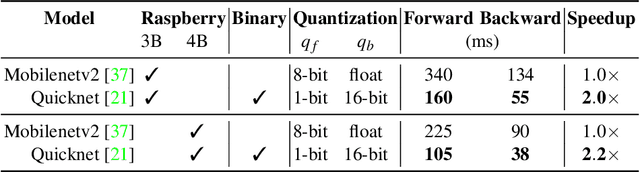
On-device learning remains a formidable challenge, especially when dealing with resource-constrained devices that have limited computational capabilities. This challenge is primarily rooted in two key issues: first, the memory available on embedded devices is typically insufficient to accommodate the memory-intensive back-propagation algorithm, which often relies on floating-point precision. Second, the development of learning algorithms on models with extreme quantization levels, such as Binary Neural Networks (BNNs), is critical due to the drastic reduction in bit representation. In this study, we propose a solution that combines recent advancements in the field of Continual Learning (CL) and Binary Neural Networks to enable on-device training while maintaining competitive performance. Specifically, our approach leverages binary latent replay (LR) activations and a novel quantization scheme that significantly reduces the number of bits required for gradient computation. The experimental validation demonstrates a significant accuracy improvement in combination with a noticeable reduction in memory requirement, confirming the suitability of our approach in expanding the practical applications of deep learning in real-world scenarios.
On-Device Learning with Binary Neural Networks
Aug 29, 2023



Existing Continual Learning (CL) solutions only partially address the constraints on power, memory and computation of the deep learning models when deployed on low-power embedded CPUs. In this paper, we propose a CL solution that embraces the recent advancements in CL field and the efficiency of the Binary Neural Networks (BNN), that use 1-bit for weights and activations to efficiently execute deep learning models. We propose a hybrid quantization of CWR* (an effective CL approach) that considers differently forward and backward pass in order to retain more precision during gradient update step and at the same time minimizing the latency overhead. The choice of a binary network as backbone is essential to meet the constraints of low power devices and, to the best of authors' knowledge, this is the first attempt to prove on-device learning with BNN. The experimental validation carried out confirms the validity and the suitability of the proposed method.