 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightweight Cross-Spectral Face Recognition via Contrastive Alignment and Distillation
May 06, 2026Heterogeneous Face Recognition (HFR) aims at matching face images captured across different sensing modalities, such as thermal-to-visible or near-infrared-to-visible, enhancing the usability of face recognition systems in challenging real-world conditions. Although recent HFR methods have achieved significant improvements in performance, many rely on computationally expensive models, making them impractical for deployment on resource-limited edge devices. In this work, we introduce a lightweight yet effective HFR framework by adapting a hybrid CNN-Transformer model originally developed for RGB homogeneous face recognition. Our approach enables efficient end-to-end training with only a small amount of paired heterogeneous data, while still maintaining strong performance on standard RGB face recognition benchmarks. This makes it suitable for both homogeneous and heterogeneous settings. Comprehensive experiments on several challenging HFR and face recognition benchmarks show that our method achieves state-of-the-art or competitive performance while keeping computational requirements low.
Enhancing Domain Diversity in Synthetic Data Face Recognition with Dataset Fusion
Jul 22, 2025While the accuracy of face recognition systems has improved significantly in recent years, the datasets used to train these models are often collected through web crawling without the explicit consent of users, raising ethical and privacy concerns. To address this, many recent approaches have explored the use of synthetic data for training face recognition models. However, these models typically underperform compared to those trained on real-world data. A common limitation is that a single generator model is often used to create the entire synthetic dataset, leading to model-specific artifacts that may cause overfitting to the generator's inherent biases and artifacts. In this work, we propose a solution by combining two state-of-the-art synthetic face datasets generated using architecturally distinct backbones. This fusion reduces model-specific artifacts, enhances diversity in pose, lighting, and demographics, and implicitly regularizes the face recognition model by emphasizing identity-relevant features. We evaluate the performance of models trained on this combined dataset using standard face recognition benchmarks and demonstrate that our approach achieves superior performance across many of these benchmarks.
The Invisible Threat: Evaluating the Vulnerability of Cross-Spectral Face Recognition to Presentation Attacks
May 01, 2025Cross-spectral face recognition systems are designed to enhance the performance of facial recognition systems by enabling cross-modal matching under challenging operational conditions. A particularly relevant application is the matching of near-infrared (NIR) images to visible-spectrum (VIS) images, enabling the verification of individuals by comparing NIR facial captures acquired with VIS reference images. The use of NIR imaging offers several advantages, including greater robustness to illumination variations, better visibility through glasses and glare, and greater resistance to presentation attacks. Despite these claimed benefits, the robustness of NIR-based systems against presentation attacks has not been systematically studied in the literature. In this work, we conduct a comprehensive evaluation into the vulnerability of NIR-VIS cross-spectral face recognition systems to presentation attacks. Our empirical findings indicate that, although these systems exhibit a certain degree of reliability, they remain vulnerable to specific attacks, emphasizing the need for further research in this area.
xEdgeFace: Efficient Cross-Spectral Face Recognition for Edge Devices
Apr 28, 2025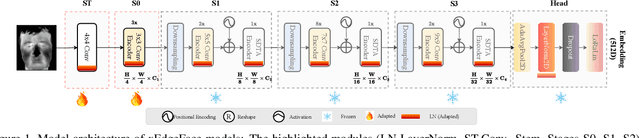
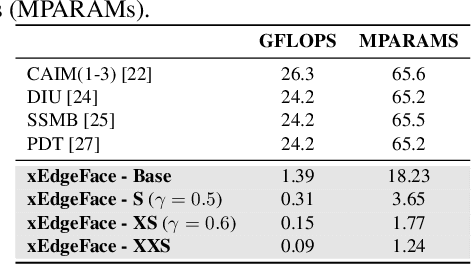
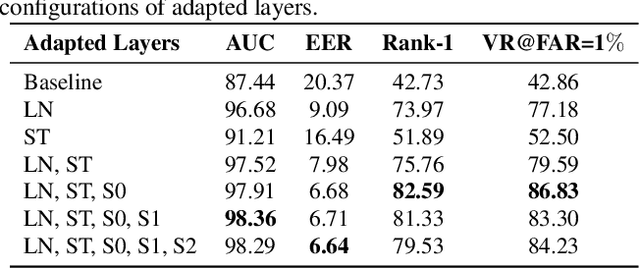
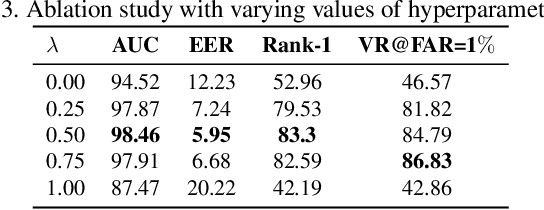
Heterogeneous Face Recognition (HFR) addresses the challenge of matching face images across different sensing modalities, such as thermal to visible or near-infrared to visible, expanding the applicability of face recognition systems in real-world, unconstrained environments. While recent HFR methods have shown promising results, many rely on computation-intensive architectures, limiting their practicality for deployment on resource-constrained edge devices. In this work, we present a lightweight yet effective HFR framework by adapting a hybrid CNN-Transformer architecture originally designed for face recognition. Our approach enables efficient end-to-end training with minimal paired heterogeneous data while preserving strong performance on standard RGB face recognition tasks. This makes it a compelling solution for both homogeneous and heterogeneous scenarios. Extensive experiments across multiple challenging HFR and face recognition benchmarks demonstrate that our method consistently outperforms state-of-the-art approaches while maintaining a low computational overhead.
Exploring ChatGPT for Face Presentation Attack Detection in Zero and Few-Shot in-Context Learning
Jan 15, 2025
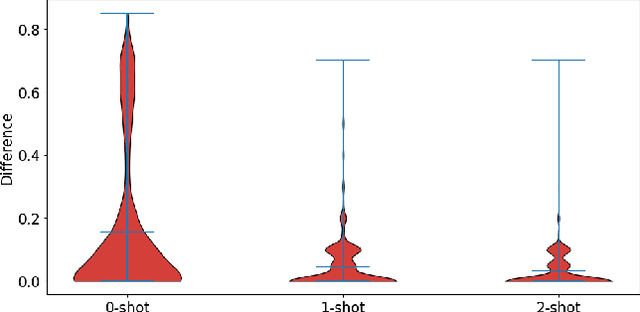

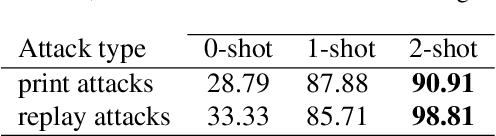
This study highlights the potential of ChatGPT (specifically GPT-4o) as a competitive alternative for Face Presentation Attack Detection (PAD), outperforming several PAD models, including commercial solutions, in specific scenarios. Our results show that GPT-4o demonstrates high consistency, particularly in few-shot in-context learning, where its performance improves as more examples are provided (reference data). We also observe that detailed prompts enable the model to provide scores reliably, a behavior not observed with concise prompts. Additionally, explanation-seeking prompts slightly enhance the model's performance by improving its interpretability. Remarkably, the model exhibits emergent reasoning capabilities, correctly predicting the attack type (print or replay) with high accuracy in few-shot scenarios, despite not being explicitly instructed to classify attack types. Despite these strengths, GPT-4o faces challenges in zero-shot tasks, where its performance is limited compared to specialized PAD systems. Experiments were conducted on a subset of the SOTERIA dataset, ensuring compliance with data privacy regulations by using only data from consenting individuals. These findings underscore GPT-4o's promise in PAD applications, laying the groundwork for future research to address broader data privacy concerns and improve cross-dataset generalization. Code available here: https://gitlab.idiap.ch/bob/bob.paper.wacv2025_chatgpt_face_pad
Second FRCSyn-onGoing: Winning Solutions and Post-Challenge Analysis to Improve Face Recognition with Synthetic Data
Dec 02, 2024Synthetic data is gaining increasing popularity for face recognition technologies, mainly due to the privacy concerns and challenges associated with obtaining real data, including diverse scenarios, quality, and demographic groups, among others. It also offers some advantages over real data, such as the large amount of data that can be generated or the ability to customize it to adapt to specific problem-solving needs. To effectively use such data, face recognition models should also be specifically designed to exploit synthetic data to its fullest potential. In order to promote the proposal of novel Generative AI methods and synthetic data, and investigate the application of synthetic data to better train face recognition systems, we introduce the 2nd FRCSyn-onGoing challenge, based on the 2nd Face Recognition Challenge in the Era of Synthetic Data (FRCSyn), originally launched at CVPR 2024. This is an ongoing challenge that provides researchers with an accessible platform to benchmark i) the proposal of novel Generative AI methods and synthetic data, and ii) novel face recognition systems that are specifically proposed to take advantage of synthetic data. We focus on exploring the use of synthetic data both individually and in combination with real data to solve current challenges in face recognition such as demographic bias, domain adaptation, and performance constraints in demanding situations, such as age disparities between training and testing, changes in the pose, or occlusions. Very interesting findings are obtained in this second edition, including a direct comparison with the first one, in which synthetic databases were restricted to DCFace and GANDiffFace.
Face Reconstruction from Face Embeddings using Adapter to a Face Foundation Model
Nov 06, 2024



Face recognition systems extract embedding vectors from face images and use these embeddings to verify or identify individuals. Face reconstruction attack (also known as template inversion) refers to reconstructing face images from face embeddings and using the reconstructed face image to enter a face recognition system. In this paper, we propose to use a face foundation model to reconstruct face images from the embeddings of a blackbox face recognition model. The foundation model is trained with 42M images to generate face images from the facial embeddings of a fixed face recognition model. We propose to use an adapter to translate target embeddings into the embedding space of the foundation model. The generated images are evaluated on different face recognition models and different datasets, demonstrating the effectiveness of our method to translate embeddings of different face recognition models. We also evaluate the transferability of reconstructed face images when attacking different face recognition models. Our experimental results show that our reconstructed face images outperform previous reconstruction attacks against face recognition models.
Digi2Real: Bridging the Realism Gap in Synthetic Data Face Recognition via Foundation Models
Nov 05, 2024
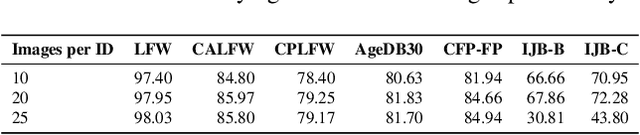


The accuracy of face recognition systems has improved significantly in the past few years, thanks to the large amount of data collected and the advancement in neural network architectures. However, these large-scale datasets are often collected without explicit consent, raising ethical and privacy concerns. To address this, there have been proposals to use synthetic datasets for training face recognition models. Yet, such models still rely on real data to train the generative models and generally exhibit inferior performance compared to those trained on real datasets. One of these datasets, DigiFace, uses a graphics pipeline to generate different identities and different intra-class variations without using real data in training the models. However, the performance of this approach is poor on face recognition benchmarks, possibly due to the lack of realism in the images generated from the graphics pipeline. In this work, we introduce a novel framework for realism transfer aimed at enhancing the realism of synthetically generated face images. Our method leverages the large-scale face foundation model, and we adapt the pipeline for realism enhancement. By integrating the controllable aspects of the graphics pipeline with our realism enhancement technique, we generate a large amount of realistic variations-combining the advantages of both approaches. Our empirical evaluations demonstrate that models trained using our enhanced dataset significantly improve the performance of face recognition systems over the baseline. The source code and datasets will be made available publicly.
Modality Agnostic Heterogeneous Face Recognition with Switch Style Modulators
Jul 11, 2024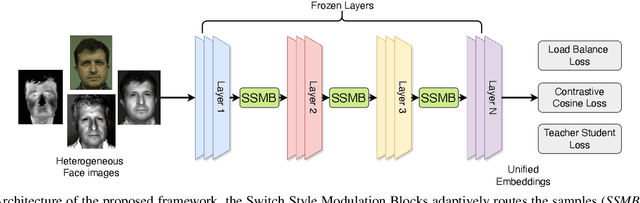
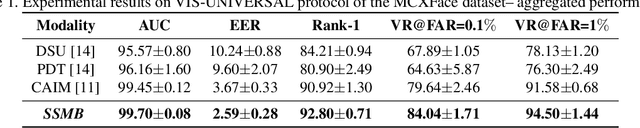
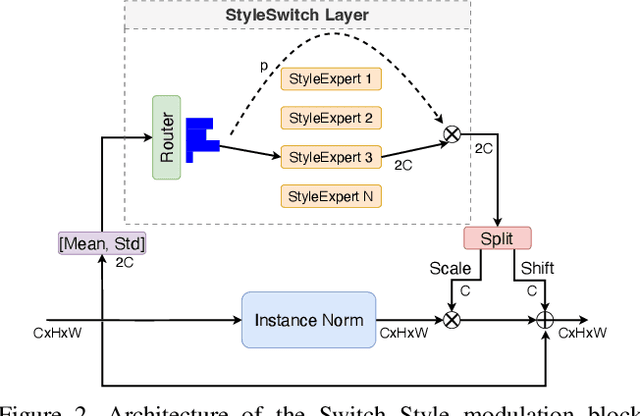
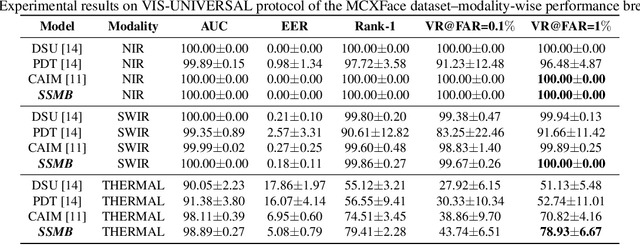
Heterogeneous Face Recognition (HFR) systems aim to enhance the capability of face recognition in challenging cross-modal authentication scenarios. However, the significant domain gap between the source and target modalities poses a considerable challenge for cross-domain matching. Existing literature primarily focuses on developing HFR approaches for specific pairs of face modalities, necessitating the explicit training of models for each source-target combination. In this work, we introduce a novel framework designed to train a modality-agnostic HFR method capable of handling multiple modalities during inference, all without explicit knowledge of the target modality labels. We achieve this by implementing a computationally efficient automatic routing mechanism called Switch Style Modulation Blocks (SSMB) that trains various domain expert modulators which transform the feature maps adaptively reducing the domain gap. Our proposed SSMB can be trained end-to-end and seamlessly integrated into pre-trained face recognition models, transforming them into modality-agnostic HFR models. We have performed extensive evaluations on HFR benchmark datasets to demonstrate its effectiveness. The source code and protocols will be made publicly available.
Heterogeneous Face Recognition Using Domain Invariant Units
Apr 22, 2024



Heterogeneous Face Recognition (HFR) aims to expand the applicability of Face Recognition (FR) systems to challenging scenarios, enabling the matching of face images across different domains, such as matching thermal images to visible spectra. However, the development of HFR systems is challenging because of the significant domain gap between modalities and the lack of availability of large-scale paired multi-channel data. In this work, we leverage a pretrained face recognition model as a teacher network to learn domaininvariant network layers called Domain-Invariant Units (DIU) to reduce the domain gap. The proposed DIU can be trained effectively even with a limited amount of paired training data, in a contrastive distillation framework. This proposed approach has the potential to enhance pretrained models, making them more adaptable to a wider range of variations in data. We extensively evaluate our approach on multiple challenging benchmarks, demonstrating superior performance compared to state-of-the-art methods.