 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring ChatGPT for Face Presentation Attack Detection in Zero and Few-Shot in-Context Learning
Jan 15, 2025
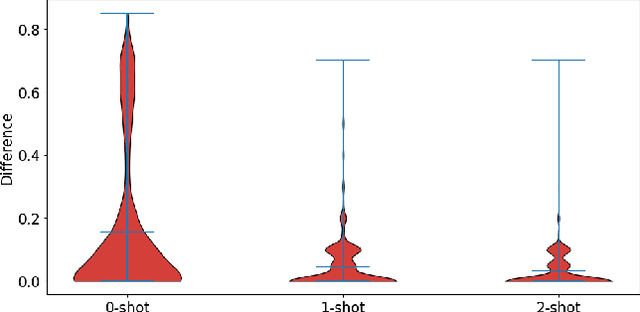

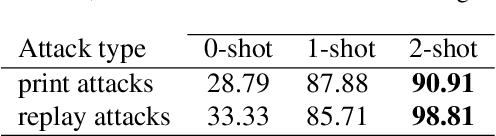
This study highlights the potential of ChatGPT (specifically GPT-4o) as a competitive alternative for Face Presentation Attack Detection (PAD), outperforming several PAD models, including commercial solutions, in specific scenarios. Our results show that GPT-4o demonstrates high consistency, particularly in few-shot in-context learning, where its performance improves as more examples are provided (reference data). We also observe that detailed prompts enable the model to provide scores reliably, a behavior not observed with concise prompts. Additionally, explanation-seeking prompts slightly enhance the model's performance by improving its interpretability. Remarkably, the model exhibits emergent reasoning capabilities, correctly predicting the attack type (print or replay) with high accuracy in few-shot scenarios, despite not being explicitly instructed to classify attack types. Despite these strengths, GPT-4o faces challenges in zero-shot tasks, where its performance is limited compared to specialized PAD systems. Experiments were conducted on a subset of the SOTERIA dataset, ensuring compliance with data privacy regulations by using only data from consenting individuals. These findings underscore GPT-4o's promise in PAD applications, laying the groundwork for future research to address broader data privacy concerns and improve cross-dataset generalization. Code available here: https://gitlab.idiap.ch/bob/bob.paper.wacv2025_chatgpt_face_pad
in-Car Biometrics (iCarB) Datasets for Driver Recognition: Face, Fingerprint, and Voice
Nov 26, 2024We present three biometric datasets (iCarB-Face, iCarB-Fingerprint, iCarB-Voice) containing face videos, fingerprint images, and voice samples, collected inside a car from 200 consenting volunteers. The data was acquired using a near-infrared camera, two fingerprint scanners, and two microphones, while the volunteers were seated in the driver's seat of the car. The data collection took place while the car was parked both indoors and outdoors, and different "noises" were added to simulate non-ideal biometric data capture that may be encountered in real-life driver recognition. Although the datasets are specifically tailored to in-vehicle biometric recognition, their utility is not limited to the automotive environment. The iCarB datasets, which are available to the research community, can be used to: (i) evaluate and benchmark face, fingerprint, and voice recognition systems (we provide several evaluation protocols); (ii) create multimodal pseudo-identities, to train/test multimodal fusion algorithms; (iii) create Presentation Attacks from the biometric data, to evaluate Presentation Attack Detection algorithms; (iv) investigate demographic and environmental biases in biometric systems, using the provided metadata. To the best of our knowledge, ours are the largest and most diverse publicly available in-vehicle biometric datasets. Most other datasets contain only one biometric modality (usually face), while our datasets consist of three modalities, all acquired in the same automotive environment. Moreover, iCarB-Fingerprint seems to be the first publicly available in-vehicle fingerprint dataset. Finally, the iCarB datasets boast a rare level of demographic diversity among the 200 data subjects, including a 50/50 gender split, skin colours across the whole Fitzpatrick-scale spectrum, and a wide age range (18-60+). So, these datasets will be valuable for advancing biometrics research.