 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentity-Preserving Aging and De-Aging of Faces in the StyleGAN Latent Space
Aug 12, 2025Face aging or de-aging with generative AI has gained significant attention for its applications in such fields like forensics, security, and media. However, most state of the art methods rely on conditional Generative Adversarial Networks (GANs), Diffusion-based models, or Visual Language Models (VLMs) to age or de-age faces based on predefined age categories and conditioning via loss functions, fine-tuning, or text prompts. The reliance on such conditioning leads to complex training requirements, increased data needs, and challenges in generating consistent results. Additionally, identity preservation is rarely taken into accountor evaluated on a single face recognition system without any control or guarantees on whether identity would be preserved in a generated aged/de-aged face. In this paper, we propose to synthesize aged and de-aged faces via editing latent space of StyleGAN2 using a simple support vector modeling of aging/de-aging direction and several feature selection approaches. By using two state-of-the-art face recognition systems, we empirically find the identity preserving subspace within the StyleGAN2 latent space, so that an apparent age of a given face can changed while preserving the identity. We then propose a simple yet practical formula for estimating the limits on aging/de-aging parameters that ensures identity preservation for a given input face. Using our method and estimated parameters we have generated a public dataset of synthetic faces at different ages that can be used for benchmarking cross-age face recognition, age assurance systems, or systems for detection of synthetic images. Our code and dataset are available at the project page https://www.idiap.ch/paper/agesynth/
Investigation of Accuracy and Bias in Face Recognition Trained with Synthetic Data
Jul 28, 2025Synthetic data has emerged as a promising alternative for training face recognition (FR) models, offering advantages in scalability, privacy compliance, and potential for bias mitigation. However, critical questions remain on whether both high accuracy and fairness can be achieved with synthetic data. In this work, we evaluate the impact of synthetic data on bias and performance of FR systems. We generate balanced face dataset, FairFaceGen, using two state of the art text-to-image generators, Flux.1-dev and Stable Diffusion v3.5 (SD35), and combine them with several identity augmentation methods, including Arc2Face and four IP-Adapters. By maintaining equal identity count across synthetic and real datasets, we ensure fair comparisons when evaluating FR performance on standard (LFW, AgeDB-30, etc.) and challenging IJB-B/C benchmarks and FR bias on Racial Faces in-the-Wild (RFW) dataset. Our results demonstrate that although synthetic data still lags behind the real datasets in the generalization on IJB-B/C, demographically balanced synthetic datasets, especially those generated with SD35, show potential for bias mitigation. We also observe that the number and quality of intra-class augmentations significantly affect FR accuracy and fairness. These findings provide practical guidelines for constructing fairer FR systems using synthetic data.
Second Competition on Presentation Attack Detection on ID Card
Jul 27, 2025This work summarises and reports the results of the second Presentation Attack Detection competition on ID cards. This new version includes new elements compared to the previous one. (1) An automatic evaluation platform was enabled for automatic benchmarking; (2) Two tracks were proposed in order to evaluate algorithms and datasets, respectively; and (3) A new ID card dataset was shared with Track 1 teams to serve as the baseline dataset for the training and optimisation. The Hochschule Darmstadt, Fraunhofer-IGD, and Facephi company jointly organised this challenge. 20 teams were registered, and 74 submitted models were evaluated. For Track 1, the "Dragons" team reached first place with an Average Ranking and Equal Error rate (EER) of AV-Rank of 40.48% and 11.44% EER, respectively. For the more challenging approach in Track 2, the "Incode" team reached the best results with an AV-Rank of 14.76% and 6.36% EER, improving on the results of the first edition of 74.30% and 21.87% EER, respectively. These results suggest that PAD on ID cards is improving, but it is still a challenging problem related to the number of images, especially of bona fide images.
Enhancing Domain Diversity in Synthetic Data Face Recognition with Dataset Fusion
Jul 22, 2025While the accuracy of face recognition systems has improved significantly in recent years, the datasets used to train these models are often collected through web crawling without the explicit consent of users, raising ethical and privacy concerns. To address this, many recent approaches have explored the use of synthetic data for training face recognition models. However, these models typically underperform compared to those trained on real-world data. A common limitation is that a single generator model is often used to create the entire synthetic dataset, leading to model-specific artifacts that may cause overfitting to the generator's inherent biases and artifacts. In this work, we propose a solution by combining two state-of-the-art synthetic face datasets generated using architecturally distinct backbones. This fusion reduces model-specific artifacts, enhances diversity in pose, lighting, and demographics, and implicitly regularizes the face recognition model by emphasizing identity-relevant features. We evaluate the performance of models trained on this combined dataset using standard face recognition benchmarks and demonstrate that our approach achieves superior performance across many of these benchmarks.
ScoreMix: Improving Face Recognition via Score Composition in Diffusion Generators
Jun 11, 2025In this paper, we propose ScoreMix, a novel yet simple data augmentation strategy leveraging the score compositional properties of diffusion models to enhance discriminator performance, particularly under scenarios with limited labeled data. By convexly mixing the scores from different class-conditioned trajectories during diffusion sampling, we generate challenging synthetic samples that significantly improve discriminative capabilities in all studied benchmarks. We systematically investigate class-selection strategies for mixing and discover that greater performance gains arise when combining classes distant in the discriminator's embedding space, rather than close in the generator's condition space. Moreover, we empirically show that, under standard metrics, the correlation between the generator's learned condition space and the discriminator's embedding space is minimal. Our approach achieves notable performance improvements without extensive parameter searches, demonstrating practical advantages for training discriminative models while effectively mitigating problems regarding collections of large datasets. Paper website: https://parsa-ra.github.io/scoremix
The Invisible Threat: Evaluating the Vulnerability of Cross-Spectral Face Recognition to Presentation Attacks
May 01, 2025Cross-spectral face recognition systems are designed to enhance the performance of facial recognition systems by enabling cross-modal matching under challenging operational conditions. A particularly relevant application is the matching of near-infrared (NIR) images to visible-spectrum (VIS) images, enabling the verification of individuals by comparing NIR facial captures acquired with VIS reference images. The use of NIR imaging offers several advantages, including greater robustness to illumination variations, better visibility through glasses and glare, and greater resistance to presentation attacks. Despite these claimed benefits, the robustness of NIR-based systems against presentation attacks has not been systematically studied in the literature. In this work, we conduct a comprehensive evaluation into the vulnerability of NIR-VIS cross-spectral face recognition systems to presentation attacks. Our empirical findings indicate that, although these systems exhibit a certain degree of reliability, they remain vulnerable to specific attacks, emphasizing the need for further research in this area.
xEdgeFace: Efficient Cross-Spectral Face Recognition for Edge Devices
Apr 28, 2025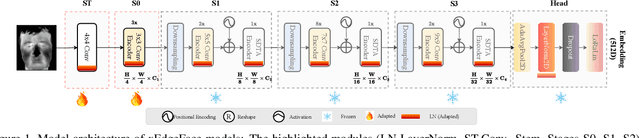
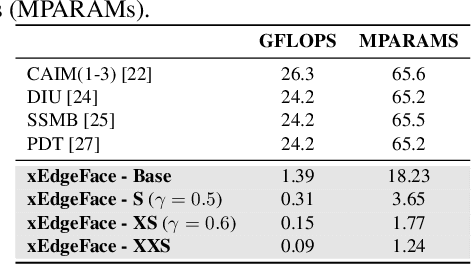
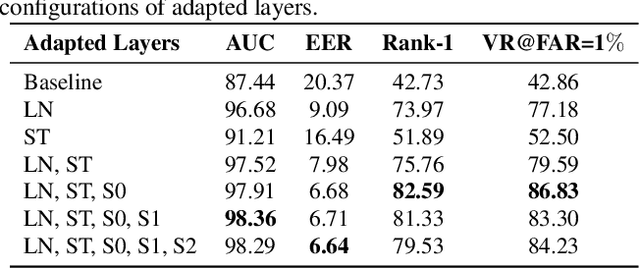
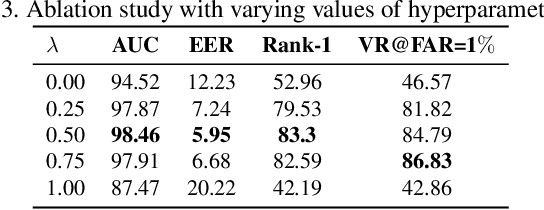
Heterogeneous Face Recognition (HFR) addresses the challenge of matching face images across different sensing modalities, such as thermal to visible or near-infrared to visible, expanding the applicability of face recognition systems in real-world, unconstrained environments. While recent HFR methods have shown promising results, many rely on computation-intensive architectures, limiting their practicality for deployment on resource-constrained edge devices. In this work, we present a lightweight yet effective HFR framework by adapting a hybrid CNN-Transformer architecture originally designed for face recognition. Our approach enables efficient end-to-end training with minimal paired heterogeneous data while preserving strong performance on standard RGB face recognition tasks. This makes it a compelling solution for both homogeneous and heterogeneous scenarios. Extensive experiments across multiple challenging HFR and face recognition benchmarks demonstrate that our method consistently outperforms state-of-the-art approaches while maintaining a low computational overhead.
AugGen: Synthetic Augmentation Can Improve Discriminative Models
Mar 14, 2025



The increasing dependence on large-scale datasets in machine learning introduces significant privacy and ethical challenges. Synthetic data generation offers a promising solution; however, most current methods rely on external datasets or pre-trained models, which add complexity and escalate resource demands. In this work, we introduce a novel self-contained synthetic augmentation technique that strategically samples from a conditional generative model trained exclusively on the target dataset. This approach eliminates the need for auxiliary data sources. Applied to face recognition datasets, our method achieves 1--12\% performance improvements on the IJB-C and IJB-B benchmarks. It outperforms models trained solely on real data and exceeds the performance of state-of-the-art synthetic data generation baselines. Notably, these enhancements often surpass those achieved through architectural improvements, underscoring the significant impact of synthetic augmentation in data-scarce environments. These findings demonstrate that carefully integrated synthetic data not only addresses privacy and resource constraints but also substantially boosts model performance. Project page https://parsa-ra.github.io/auggen
Review of Demographic Bias in Face Recognition
Feb 04, 2025Demographic bias in face recognition (FR) has emerged as a critical area of research, given its impact on fairness, equity, and reliability across diverse applications. As FR technologies are increasingly deployed globally, disparities in performance across demographic groups -- such as race, ethnicity, and gender -- have garnered significant attention. These biases not only compromise the credibility of FR systems but also raise ethical concerns, especially when these technologies are employed in sensitive domains. This review consolidates extensive research efforts providing a comprehensive overview of the multifaceted aspects of demographic bias in FR. We systematically examine the primary causes, datasets, assessment metrics, and mitigation approaches associated with demographic disparities in FR. By categorizing key contributions in these areas, this work provides a structured approach to understanding and addressing the complexity of this issue. Finally, we highlight current advancements and identify emerging challenges that need further investigation. This article aims to provide researchers with a unified perspective on the state-of-the-art while emphasizing the critical need for equitable and trustworthy FR systems.
Exploring ChatGPT for Face Presentation Attack Detection in Zero and Few-Shot in-Context Learning
Jan 15, 2025
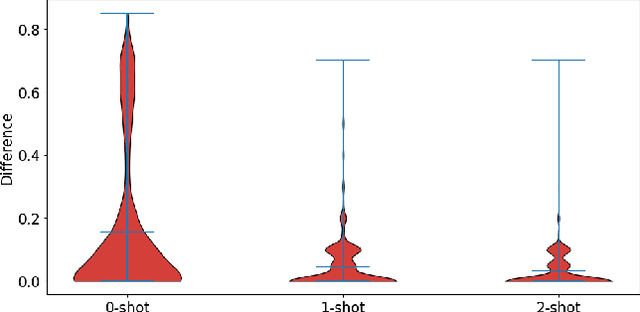

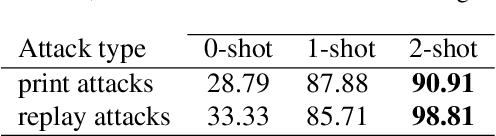
This study highlights the potential of ChatGPT (specifically GPT-4o) as a competitive alternative for Face Presentation Attack Detection (PAD), outperforming several PAD models, including commercial solutions, in specific scenarios. Our results show that GPT-4o demonstrates high consistency, particularly in few-shot in-context learning, where its performance improves as more examples are provided (reference data). We also observe that detailed prompts enable the model to provide scores reliably, a behavior not observed with concise prompts. Additionally, explanation-seeking prompts slightly enhance the model's performance by improving its interpretability. Remarkably, the model exhibits emergent reasoning capabilities, correctly predicting the attack type (print or replay) with high accuracy in few-shot scenarios, despite not being explicitly instructed to classify attack types. Despite these strengths, GPT-4o faces challenges in zero-shot tasks, where its performance is limited compared to specialized PAD systems. Experiments were conducted on a subset of the SOTERIA dataset, ensuring compliance with data privacy regulations by using only data from consenting individuals. These findings underscore GPT-4o's promise in PAD applications, laying the groundwork for future research to address broader data privacy concerns and improve cross-dataset generalization. Code available here: https://gitlab.idiap.ch/bob/bob.paper.wacv2025_chatgpt_face_pad