 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigation of Accuracy and Bias in Face Recognition Trained with Synthetic Data
Jul 28, 2025Synthetic data has emerged as a promising alternative for training face recognition (FR) models, offering advantages in scalability, privacy compliance, and potential for bias mitigation. However, critical questions remain on whether both high accuracy and fairness can be achieved with synthetic data. In this work, we evaluate the impact of synthetic data on bias and performance of FR systems. We generate balanced face dataset, FairFaceGen, using two state of the art text-to-image generators, Flux.1-dev and Stable Diffusion v3.5 (SD35), and combine them with several identity augmentation methods, including Arc2Face and four IP-Adapters. By maintaining equal identity count across synthetic and real datasets, we ensure fair comparisons when evaluating FR performance on standard (LFW, AgeDB-30, etc.) and challenging IJB-B/C benchmarks and FR bias on Racial Faces in-the-Wild (RFW) dataset. Our results demonstrate that although synthetic data still lags behind the real datasets in the generalization on IJB-B/C, demographically balanced synthetic datasets, especially those generated with SD35, show potential for bias mitigation. We also observe that the number and quality of intra-class augmentations significantly affect FR accuracy and fairness. These findings provide practical guidelines for constructing fairer FR systems using synthetic data.
Second Competition on Presentation Attack Detection on ID Card
Jul 27, 2025This work summarises and reports the results of the second Presentation Attack Detection competition on ID cards. This new version includes new elements compared to the previous one. (1) An automatic evaluation platform was enabled for automatic benchmarking; (2) Two tracks were proposed in order to evaluate algorithms and datasets, respectively; and (3) A new ID card dataset was shared with Track 1 teams to serve as the baseline dataset for the training and optimisation. The Hochschule Darmstadt, Fraunhofer-IGD, and Facephi company jointly organised this challenge. 20 teams were registered, and 74 submitted models were evaluated. For Track 1, the "Dragons" team reached first place with an Average Ranking and Equal Error rate (EER) of AV-Rank of 40.48% and 11.44% EER, respectively. For the more challenging approach in Track 2, the "Incode" team reached the best results with an AV-Rank of 14.76% and 6.36% EER, improving on the results of the first edition of 74.30% and 21.87% EER, respectively. These results suggest that PAD on ID cards is improving, but it is still a challenging problem related to the number of images, especially of bona fide images.
Review of Demographic Bias in Face Recognition
Feb 04, 2025Demographic bias in face recognition (FR) has emerged as a critical area of research, given its impact on fairness, equity, and reliability across diverse applications. As FR technologies are increasingly deployed globally, disparities in performance across demographic groups -- such as race, ethnicity, and gender -- have garnered significant attention. These biases not only compromise the credibility of FR systems but also raise ethical concerns, especially when these technologies are employed in sensitive domains. This review consolidates extensive research efforts providing a comprehensive overview of the multifaceted aspects of demographic bias in FR. We systematically examine the primary causes, datasets, assessment metrics, and mitigation approaches associated with demographic disparities in FR. By categorizing key contributions in these areas, this work provides a structured approach to understanding and addressing the complexity of this issue. Finally, we highlight current advancements and identify emerging challenges that need further investigation. This article aims to provide researchers with a unified perspective on the state-of-the-art while emphasizing the critical need for equitable and trustworthy FR systems.
VRBiom: A New Periocular Dataset for Biometric Applications of HMD
Jul 02, 2024With advancements in hardware, high-quality HMD devices are being developed by numerous companies, driving increased consumer interest in AR, VR, and MR applications. In this work, we present a new dataset, called VRBiom, of periocular videos acquired using a Virtual Reality headset. The VRBiom, targeted at biometric applications, consists of 900 short videos acquired from 25 individuals recorded in the NIR spectrum. These 10s long videos have been captured using the internal tracking cameras of Meta Quest Pro at 72 FPS. To encompass real-world variations, the dataset includes recordings under three gaze conditions: steady, moving, and partially closed eyes. We have also ensured an equal split of recordings without and with glasses to facilitate the analysis of eye-wear. These videos, characterized by non-frontal views of the eye and relatively low spatial resolutions (400 x 400), can be instrumental in advancing state-of-the-art research across various biometric applications. The VRBiom dataset can be utilized to evaluate, train, or adapt models for biometric use-cases such as iris and/or periocular recognition and associated sub-tasks such as detection and semantic segmentation. In addition to data from real individuals, we have included around 1100 PA constructed from 92 PA instruments. These PAIs fall into six categories constructed through combinations of print attacks (real and synthetic identities), fake 3D eyeballs, plastic eyes, and various types of masks and mannequins. These PA videos, combined with genuine (bona-fide) data, can be utilized to address concerns related to spoofing, which is a significant threat if these devices are to be used for authentication. The VRBiom dataset is publicly available for research purposes related to biometric applications only.
\textit{sweet} -- An Open Source Modular Platform for Contactless Hand Vascular Biometric Experiments
Apr 14, 2024



Current finger-vein or palm-vein recognition systems usually require direct contact of the subject with the apparatus. This can be problematic in environments where hygiene is of primary importance. In this work we present a contactless vascular biometrics sensor platform named \sweet which can be used for hand vascular biometrics studies (wrist-, palm- and finger-vein) and surface features such as palmprint. It supports several acquisition modalities such as multi-spectral Near-Infrared (NIR), RGB-color, Stereo Vision (SV) and Photometric Stereo (PS). Using this platform we collect a dataset consisting of the fingers, palm and wrist vascular data of 120 subjects and develop a powerful 3D pipeline for the pre-processing of this data. We then present biometric experimental results, focusing on Finger-Vein Recognition (FVR). Finally, we discuss fusion of multiple modalities, such palm-vein combined with palm-print biometrics. The acquisition software, parts of the hardware design, the new FV dataset, as well as source-code for our experiments are publicly available for research purposes.
Latent Enhancing AutoEncoder for Occluded Image Classification
Feb 10, 2024Large occlusions result in a significant decline in image classification accuracy. During inference, diverse types of unseen occlusions introduce out-of-distribution data to the classification model, leading to accuracy dropping as low as 50%. As occlusions encompass spatially connected regions, conventional methods involving feature reconstruction are inadequate for enhancing classification performance. We introduce LEARN: Latent Enhancing feAture Reconstruction Network -- An auto-encoder based network that can be incorporated into the classification model before its classifier head without modifying the weights of classification model. In addition to reconstruction and classification losses, training of LEARN effectively combines intra- and inter-class losses calculated over its latent space -- which lead to improvement in recovering latent space of occluded data, while preserving its class-specific discriminative information. On the OccludedPASCAL3D+ dataset, the proposed LEARN outperforms standard classification models (VGG16 and ResNet-50) by a large margin and up to 2% over state-of-the-art methods. In cross-dataset testing, our method improves the average classification accuracy by more than 5% over the state-of-the-art methods. In every experiment, our model consistently maintains excellent accuracy on in-distribution data.
EFaR 2023: Efficient Face Recognition Competition
Aug 08, 2023



This paper presents the summary of the Efficient Face Recognition Competition (EFaR) held at the 2023 International Joint Conference on Biometrics (IJCB 2023). The competition received 17 submissions from 6 different teams. To drive further development of efficient face recognition models, the submitted solutions are ranked based on a weighted score of the achieved verification accuracies on a diverse set of benchmarks, as well as the deployability given by the number of floating-point operations and model size. The evaluation of submissions is extended to bias, cross-quality, and large-scale recognition benchmarks. Overall, the paper gives an overview of the achieved performance values of the submitted solutions as well as a diverse set of baselines. The submitted solutions use small, efficient network architectures to reduce the computational cost, some solutions apply model quantization. An outlook on possible techniques that are underrepresented in current solutions is given as well.
EdgeFace: Efficient Face Recognition Model for Edge Devices
Jul 04, 2023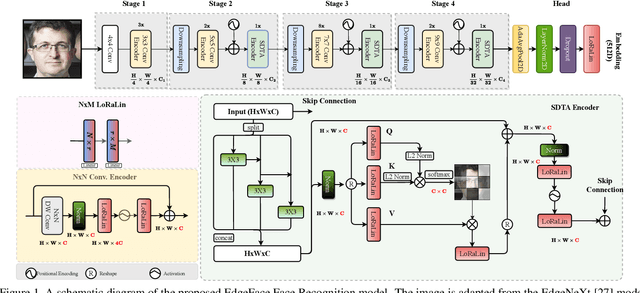



In this paper, we present EdgeFace, a lightweight and efficient face recognition network inspired by the hybrid architecture of EdgeNeXt. By effectively combining the strengths of both CNN and Transformer models, and a low rank linear layer, EdgeFace achieves excellent face recognition performance optimized for edge devices. The proposed EdgeFace network not only maintains low computational costs and compact storage, but also achieves high face recognition accuracy, making it suitable for deployment on edge devices. Extensive experiments on challenging benchmark face datasets demonstrate the effectiveness and efficiency of EdgeFace in comparison to state-of-the-art lightweight models and deep face recognition models. Our EdgeFace model with 1.77M parameters achieves state of the art results on LFW (99.73%), IJB-B (92.67%), and IJB-C (94.85%), outperforming other efficient models with larger computational complexities. The code to replicate the experiments will be made available publicly.
Residual Feature Pyramid Network for Enhancement of Vascular Patterns
Jun 29, 2023



The accuracy of finger vein recognition systems gets degraded due to low and uneven contrast between veins and surroundings, often resulting in poor detection of vein patterns. We propose a finger-vein enhancement technique, ResFPN (Residual Feature Pyramid Network), as a generic preprocessing method agnostic to the recognition pipeline. A bottom-up pyramidal architecture using the novel Structure Detection block (SDBlock) facilitates extraction of veins of varied widths. Using a feature aggregation module (FAM), we combine these vein-structures, and train the proposed ResFPN for detection of veins across scales. With enhanced presentations, our experiments indicate a reduction upto 5% in the average recognition errors for commonly used recognition pipeline over two publicly available datasets. These improvements are persistent even in cross-dataset scenario where the dataset used to train the ResFPN is different from the one used for recognition.
* published in Conference on Computer Vision and Pattern Recognition Workshops (CVPR-W) 2022
Fairness Index Measures to Evaluate Bias in Biometric Recognition
Jun 19, 2023



The demographic disparity of biometric systems has led to serious concerns regarding their societal impact as well as applicability of such systems in private and public domains. A quantitative evaluation of demographic fairness is an important step towards understanding, assessment, and mitigation of demographic bias in biometric applications. While few, existing fairness measures are based on post-decision data (such as verification accuracy) of biometric systems, we discuss how pre-decision data (score distributions) provide useful insights towards demographic fairness. In this paper, we introduce multiple measures, based on the statistical characteristics of score distributions, for the evaluation of demographic fairness of a generic biometric verification system. We also propose different variants for each fairness measure depending on how the contribution from constituent demographic groups needs to be combined towards the final measure. In each case, the behavior of the measure has been illustrated numerically and graphically on synthetic data. The demographic imbalance in benchmarking datasets is often overlooked during fairness assessment. We provide a novel weighing strategy to reduce the effect of such imbalance through a non-linear function of sample sizes of demographic groups. The proposed measures are independent of the biometric modality, and thus, applicable across commonly used biometric modalities (e.g., face, fingerprint, etc.).