 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLLM-HWSI: A Multimodal Large Language Model for Hierarchical Whole Slide Image Understanding
Mar 25, 2026Whole Slide Images (WSIs) exhibit hierarchical structure, where diagnostic information emerges from cellular morphology, regional tissue organization, and global context. Existing Computational Pathology (CPath) Multimodal Large Language Models (MLLMs) typically compress an entire WSI into a single embedding, which hinders fine-grained grounding and ignores how pathologists synthesize evidence across different scales. We introduce \textbf{MLLM-HWSI}, a Hierarchical WSI-level MLLM that aligns visual features with pathology language at four distinct scales, cell as word, patch as phrase, region as sentence, and WSI as paragraph to support interpretable evidence-grounded reasoning. MLLM-HWSI decomposes each WSI into multi-scale embeddings with scale-specific projectors and jointly enforces (i) a hierarchical contrastive objective and (ii) a cross-scale consistency loss, preserving semantic coherence from cells to the WSI. We compute diagnostically relevant patches and aggregate segmented cell embeddings into a compact cellular token per-patch using a lightweight \textit{Cell-Cell Attention Fusion (CCAF)} transformer. The projected multi-scale tokens are fused with text tokens and fed to an instruction-tuned LLM for open-ended reasoning, VQA, report, and caption generation tasks. Trained in three stages, MLLM-HWSI achieves new SOTA results on 13 WSI-level benchmarks across six CPath tasks. By aligning language with multi-scale visual evidence, MLLM-HWSI provides accurate, interpretable outputs that mirror diagnostic workflows and advance holistic WSI understanding. Code is available at: \href{https://github.com/BasitAlawode/HWSI-MLLM}{GitHub}.
AgriChat: A Multimodal Large Language Model for Agriculture Image Understanding
Mar 14, 2026The deployment of Multimodal Large Language Models (MLLMs) in agriculture is currently stalled by a critical trade-off: the existing literature lacks the large-scale agricultural datasets required for robust model development and evaluation, while current state-of-the-art models lack the verified domain expertise necessary to reason across diverse taxonomies. To address these challenges, we propose the Vision-to-Verified-Knowledge (V2VK) pipeline, a novel generative AI-driven annotation framework that integrates visual captioning with web-augmented scientific retrieval to autonomously generate the AgriMM benchmark, effectively eliminating biological hallucinations by grounding training data in verified phytopathological literature. The AgriMM benchmark contains over 3,000 agricultural classes and more than 607k VQAs spanning multiple tasks, including fine-grained plant species identification, plant disease symptom recognition, crop counting, and ripeness assessment. Leveraging this verifiable data, we present AgriChat, a specialized MLLM that presents broad knowledge across thousands of agricultural classes and provides detailed agricultural assessments with extensive explanations. Extensive evaluation across diverse tasks, datasets, and evaluation conditions reveals both the capabilities and limitations of current agricultural MLLMs, while demonstrating AgriChat's superior performance over other open-source models, including internal and external benchmarks. The results validate that preserving visual detail combined with web-verified knowledge constitutes a reliable pathway toward robust and trustworthy agricultural AI. The code and dataset are publicly available at https://github.com/boudiafA/AgriChat .
SPARROW: Learning Spatial Precision and Temporal Referential Consistency in Pixel-Grounded Video MLLMs
Mar 12, 2026Multimodal large language models (MLLMs) have advanced from image-level reasoning to pixel-level grounding, but extending these capabilities to videos remains challenging as models must achieve spatial precision and temporally consistent reference tracking. Existing video MLLMs often rely on a static segmentation token ([SEG]) for frame-wise grounding, which provides semantics but lacks temporal context, causing spatial drift, identity switches, and unstable initialization when objects move or reappear. We introduce SPARROW, a pixel-grounded video MLLM that unifies spatial accuracy and temporal stability through two key components: (i) Target-Specific Tracked Features (TSF), which inject temporally aligned referent cues during training, and (ii) a dual-prompt design that decodes box ([BOX]) and segmentation ([SEG]) tokens to fuse geometric priors with semantic grounding. SPARROW is supported by a curated referential video dataset of 30,646 videos and 45,231 Q&A pairs and operates end-to-end without external detectors via a class-agnostic SAM2-based proposer. Integrated into three recent open-source video MLLMs (UniPixel, GLUS, and VideoGLaMM), SPARROW delivers consistent gains across six benchmarks, improving up to +8.9 J&F on RVOS, +5 mIoU on visual grounding, and +5.4 CLAIR on GCG. These results demonstrate that SPARROW substantially improves referential stability, spatial precision, and temporal coherence in pixel-grounded video understanding. Project page: https://risys-lab.github.io/SPARROW
Rethinking Memory Design in SAM-Based Visual Object Tracking
Dec 27, 2025\noindent Memory has become the central mechanism enabling robust visual object tracking in modern segmentation-based frameworks. Recent methods built upon Segment Anything Model 2 (SAM2) have demonstrated strong performance by refining how past observations are stored and reused. However, existing approaches address memory limitations in a method-specific manner, leaving the broader design principles of memory in SAM-based tracking poorly understood. Moreover, it remains unclear how these memory mechanisms transfer to stronger, next-generation foundation models such as Segment Anything Model 3 (SAM3). In this work, we present a systematic memory-centric study of SAM-based visual object tracking. We first analyze representative SAM2-based trackers and show that most methods primarily differ in how short-term memory frames are selected, while sharing a common object-centric representation. Building on this insight, we faithfully reimplement these memory mechanisms within the SAM3 framework and conduct large-scale evaluations across ten diverse benchmarks, enabling a controlled analysis of memory design independent of backbone strength. Guided by our empirical findings, we propose a unified hybrid memory framework that explicitly decomposes memory into short-term appearance memory and long-term distractor-resolving memory. This decomposition enables the integration of existing memory policies in a modular and principled manner. Extensive experiments demonstrate that the proposed framework consistently improves robustness under long-term occlusion, complex motion, and distractor-heavy scenarios on both SAM2 and SAM3 backbones. Code is available at: https://github.com/HamadYA/SAM3_Tracking_Zoo. \textbf{This is a preprint. Some results are being finalized and may be updated in a future revision.}
Cytoplasmic Strings Analysis in Human Embryo Time-Lapse Videos using Deep Learning Framework
Dec 10, 2025Infertility is a major global health issue, and while in-vitro fertilization has improved treatment outcomes, embryo selection remains a critical bottleneck. Time-lapse imaging enables continuous, non-invasive monitoring of embryo development, yet most automated assessment methods rely solely on conventional morphokinetic features and overlook emerging biomarkers. Cytoplasmic Strings, thin filamentous structures connecting the inner cell mass and trophectoderm in expanded blastocysts, have been associated with faster blastocyst formation, higher blastocyst grades, and improved viability. However, CS assessment currently depends on manual visual inspection, which is labor-intensive, subjective, and severely affected by detection and subtle visual appearance. In this work, we present, to the best of our knowledge, the first computational framework for CS analysis in human IVF embryos. We first design a human-in-the-loop annotation pipeline to curate a biologically validated CS dataset from TLI videos, comprising 13,568 frames with highly sparse CS-positive instances. Building on this dataset, we propose a two-stage deep learning framework that (i) classifies CS presence at the frame level and (ii) localizes CS regions in positive cases. To address severe imbalance and feature uncertainty, we introduce the Novel Uncertainty-aware Contractive Embedding (NUCE) loss, which couples confidence-aware reweighting with an embedding contraction term to form compact, well-separated class clusters. NUCE consistently improves F1-score across five transformer backbones, while RF-DETR-based localization achieves state-of-the-art (SOTA) detection performance for thin, low-contrast CS structures. The source code will be made publicly available at: https://github.com/HamadYA/CS_Detection.
Spatio-Temporal State Space Model For Efficient Event-Based Optical Flow
Jun 09, 2025Event cameras unlock new frontiers that were previously unthinkable with standard frame-based cameras. One notable example is low-latency motion estimation (optical flow), which is critical for many real-time applications. In such applications, the computational efficiency of algorithms is paramount. Although recent deep learning paradigms such as CNN, RNN, or ViT have shown remarkable performance, they often lack the desired computational efficiency. Conversely, asynchronous event-based methods including SNNs and GNNs are computationally efficient; however, these approaches fail to capture sufficient spatio-temporal information, a powerful feature required to achieve better performance for optical flow estimation. In this work, we introduce Spatio-Temporal State Space Model (STSSM) module along with a novel network architecture to develop an extremely efficient solution with competitive performance. Our STSSM module leverages state-space models to effectively capture spatio-temporal correlations in event data, offering higher performance with lower complexity compared to ViT, CNN-based architectures in similar settings. Our model achieves 4.5x faster inference and 8x lower computations compared to TMA and 2x lower computations compared to EV-FlowNet with competitive performance on the DSEC benchmark. Our code will be available at https://github.com/AhmedHumais/E-STMFlow
CLDTracker: A Comprehensive Language Description for Visual Tracking
May 29, 2025VOT remains a fundamental yet challenging task in computer vision due to dynamic appearance changes, occlusions, and background clutter. Traditional trackers, relying primarily on visual cues, often struggle in such complex scenarios. Recent advancements in VLMs have shown promise in semantic understanding for tasks like open-vocabulary detection and image captioning, suggesting their potential for VOT. However, the direct application of VLMs to VOT is hindered by critical limitations: the absence of a rich and comprehensive textual representation that semantically captures the target object's nuances, limiting the effective use of language information; inefficient fusion mechanisms that fail to optimally integrate visual and textual features, preventing a holistic understanding of the target; and a lack of temporal modeling of the target's evolving appearance in the language domain, leading to a disconnect between the initial description and the object's subsequent visual changes. To bridge these gaps and unlock the full potential of VLMs for VOT, we propose CLDTracker, a novel Comprehensive Language Description framework for robust visual Tracking. Our tracker introduces a dual-branch architecture consisting of a textual and a visual branch. In the textual branch, we construct a rich bag of textual descriptions derived by harnessing the powerful VLMs such as CLIP and GPT-4V, enriched with semantic and contextual cues to address the lack of rich textual representation. Experiments on six standard VOT benchmarks demonstrate that CLDTracker achieves SOTA performance, validating the effectiveness of leveraging robust and temporally-adaptive vision-language representations for tracking. Code and models are publicly available at: https://github.com/HamadYA/CLDTracker
Multi-Resolution Pathology-Language Pre-training Model with Text-Guided Visual Representation
Apr 26, 2025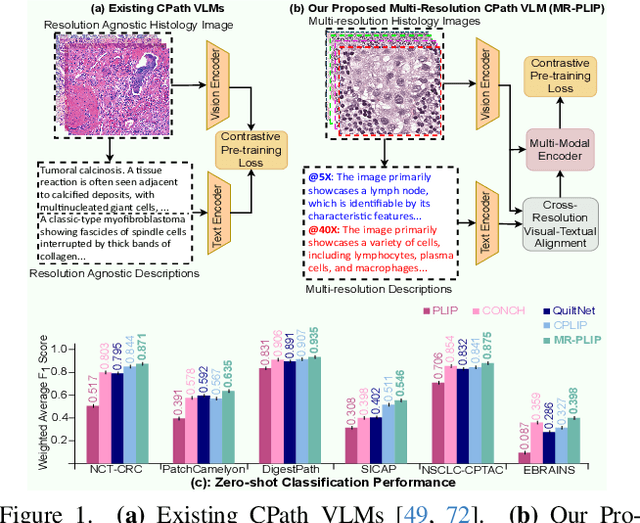
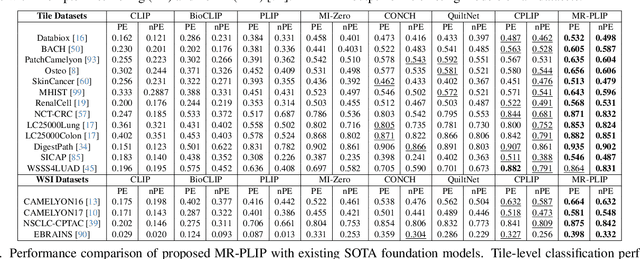
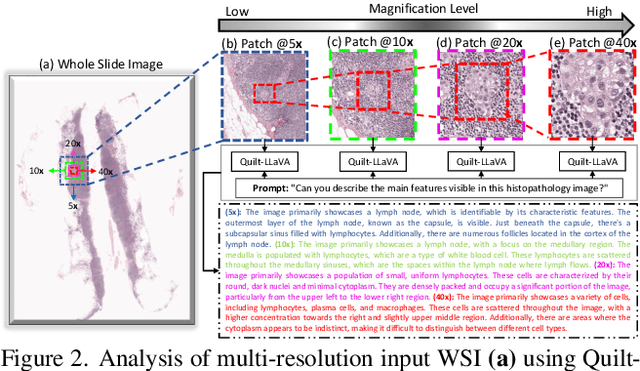
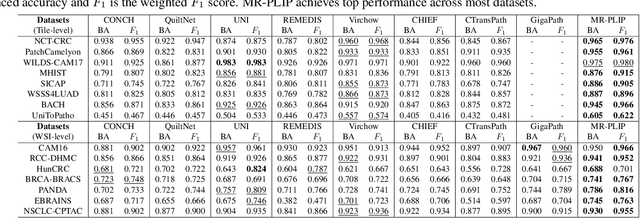
In Computational Pathology (CPath), the introduction of Vision-Language Models (VLMs) has opened new avenues for research, focusing primarily on aligning image-text pairs at a single magnification level. However, this approach might not be sufficient for tasks like cancer subtype classification, tissue phenotyping, and survival analysis due to the limited level of detail that a single-resolution image can provide. Addressing this, we propose a novel multi-resolution paradigm leveraging Whole Slide Images (WSIs) to extract histology patches at multiple resolutions and generate corresponding textual descriptions through advanced CPath VLM. We introduce visual-textual alignment at multiple resolutions as well as cross-resolution alignment to establish more effective text-guided visual representations. Cross-resolution alignment using a multimodal encoder enhances the model's ability to capture context from multiple resolutions in histology images. Our model aims to capture a broader range of information, supported by novel loss functions, enriches feature representation, improves discriminative ability, and enhances generalization across different resolutions. Pre-trained on a comprehensive TCGA dataset with 34 million image-language pairs at various resolutions, our fine-tuned model outperforms state-of-the-art (SOTA) counterparts across multiple datasets and tasks, demonstrating its effectiveness in CPath. The code is available on GitHub at: https://github.com/BasitAlawode/MR-PLIP
snnTrans-DHZ: A Lightweight Spiking Neural Network Architecture for Underwater Image Dehazing
Apr 13, 2025Underwater image dehazing is critical for vision-based marine operations because light scattering and absorption can severely reduce visibility. This paper introduces snnTrans-DHZ, a lightweight Spiking Neural Network (SNN) specifically designed for underwater dehazing. By leveraging the temporal dynamics of SNNs, snnTrans-DHZ efficiently processes time-dependent raw image sequences while maintaining low power consumption. Static underwater images are first converted into time-dependent sequences by repeatedly inputting the same image over user-defined timesteps. These RGB sequences are then transformed into LAB color space representations and processed concurrently. The architecture features three key modules: (i) a K estimator that extracts features from multiple color space representations; (ii) a Background Light Estimator that jointly infers the background light component from the RGB-LAB images; and (iii) a soft image reconstruction module that produces haze-free, visibility-enhanced outputs. The snnTrans-DHZ model is directly trained using a surrogate gradient-based backpropagation through time (BPTT) strategy alongside a novel combined loss function. Evaluated on the UIEB benchmark, snnTrans-DHZ achieves a PSNR of 21.68 dB and an SSIM of 0.8795, and on the EUVP dataset, it yields a PSNR of 23.46 dB and an SSIM of 0.8439. With only 0.5670 million network parameters, and requiring just 7.42 GSOPs and 0.0151 J of energy, the algorithm significantly outperforms existing state-of-the-art methods in terms of efficiency. These features make snnTrans-DHZ highly suitable for deployment in underwater robotics, marine exploration, and environmental monitoring.
Underwater Image Enhancement by Convolutional Spiking Neural Networks
Mar 26, 2025



Underwater image enhancement (UIE) is fundamental for marine applications, including autonomous vision-based navigation. Deep learning methods using convolutional neural networks (CNN) and vision transformers advanced UIE performance. Recently, spiking neural networks (SNN) have gained attention for their lightweight design, energy efficiency, and scalability. This paper introduces UIE-SNN, the first SNN-based UIE algorithm to improve visibility of underwater images. UIE-SNN is a 19- layered convolutional spiking encoder-decoder framework with skip connections, directly trained using surrogate gradient-based backpropagation through time (BPTT) strategy. We explore and validate the influence of training datasets on energy reduction, a unique advantage of UIE-SNN architecture, in contrast to the conventional learning-based architectures, where energy consumption is model-dependent. UIE-SNN optimizes the loss function in latent space representation to reconstruct clear underwater images. Our algorithm performs on par with its non-spiking counterpart methods in terms of PSNR and structural similarity index (SSIM) at reduced timesteps ($T=5$) and energy consumption of $85\%$. The algorithm is trained on two publicly available benchmark datasets, UIEB and EUVP, and tested on unseen images from UIEB, EUVP, LSUI, U45, and our custom UIE dataset. The UIE-SNN algorithm achieves PSNR of \(17.7801~dB\) and SSIM of \(0.7454\) on UIEB, and PSNR of \(23.1725~dB\) and SSIM of \(0.7890\) on EUVP. UIE-SNN achieves this algorithmic performance with fewer operators (\(147.49\) GSOPs) and energy (\(0.1327~J\)) compared to its non-spiking counterpart (GFLOPs = \(218.88\) and Energy=\(1.0068~J\)). Compared with existing SOTA UIE methods, UIE-SNN achieves an average of \(6.5\times\) improvement in energy efficiency. The source code is available at \href{https://github.com/vidya-rejul/UIE-SNN.git}{UIE-SNN}.