 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatio-Temporal State Space Model For Efficient Event-Based Optical Flow
Jun 09, 2025Event cameras unlock new frontiers that were previously unthinkable with standard frame-based cameras. One notable example is low-latency motion estimation (optical flow), which is critical for many real-time applications. In such applications, the computational efficiency of algorithms is paramount. Although recent deep learning paradigms such as CNN, RNN, or ViT have shown remarkable performance, they often lack the desired computational efficiency. Conversely, asynchronous event-based methods including SNNs and GNNs are computationally efficient; however, these approaches fail to capture sufficient spatio-temporal information, a powerful feature required to achieve better performance for optical flow estimation. In this work, we introduce Spatio-Temporal State Space Model (STSSM) module along with a novel network architecture to develop an extremely efficient solution with competitive performance. Our STSSM module leverages state-space models to effectively capture spatio-temporal correlations in event data, offering higher performance with lower complexity compared to ViT, CNN-based architectures in similar settings. Our model achieves 4.5x faster inference and 8x lower computations compared to TMA and 2x lower computations compared to EV-FlowNet with competitive performance on the DSEC benchmark. Our code will be available at https://github.com/AhmedHumais/E-STMFlow
Simultaneous Pre-compensation for Bandwidth Limitation and Fiber Dispersion in Cost-Sensitive IM/DD Transmission Systems
Apr 02, 2025


We propose a pre-compensation scheme for bandwidth limitation and fiber dispersion (pre-BL-EDC) based on the modified Gerchberg-Saxton (GS) algorithm. Experimental results demonstrate 1.0/1.0/2.0 dB gains compared to modified GS pre-EDC for 20/28/32 Gbit/s bandwidth-limited systems.
Bimodal SegNet: Instance Segmentation Fusing Events and RGB Frames for Robotic Grasping
Mar 20, 2023



Object segmentation for robotic grasping under dynamic conditions often faces challenges such as occlusion, low light conditions, motion blur and object size variance. To address these challenges, we propose a Deep Learning network that fuses two types of visual signals, event-based data and RGB frame data. The proposed Bimodal SegNet network has two distinct encoders, one for each signal input and a spatial pyramidal pooling with atrous convolutions. Encoders capture rich contextual information by pooling the concatenated features at different resolutions while the decoder obtains sharp object boundaries. The evaluation of the proposed method undertakes five unique image degradation challenges including occlusion, blur, brightness, trajectory and scale variance on the Event-based Segmentation (ESD) Dataset. The evaluation results show a 6-10\% segmentation accuracy improvement over state-of-the-art methods in terms of mean intersection over the union and pixel accuracy. The model code is available at https://github.com/sanket0707/Bimodal-SegNet.git
A Neuromorphic Dataset for Object Segmentation in Indoor Cluttered Environment
Feb 17, 2023

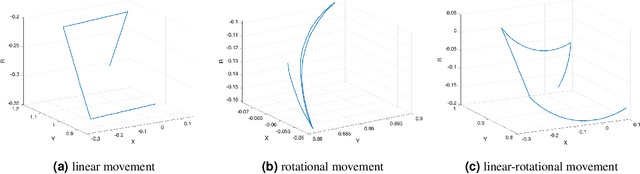

Taking advantage of an event-based camera, the issues of motion blur, low dynamic range and low time sampling of standard cameras can all be addressed. However, there is a lack of event-based datasets dedicated to the benchmarking of segmentation algorithms, especially those that provide depth information which is critical for segmentation in occluded scenes. This paper proposes a new Event-based Segmentation Dataset (ESD), a high-quality 3D spatial and temporal dataset for object segmentation in an indoor cluttered environment. Our proposed dataset ESD comprises 145 sequences with 14,166 RGB frames that are manually annotated with instance masks. Overall 21.88 million and 20.80 million events from two event-based cameras in a stereo-graphic configuration are collected, respectively. To the best of our knowledge, this densely annotated and 3D spatial-temporal event-based segmentation benchmark of tabletop objects is the first of its kind. By releasing ESD, we expect to provide the community with a challenging segmentation benchmark with high quality.
Multi-Modal MRI Reconstruction Assisted with Spatial Alignment Network
Aug 30, 2021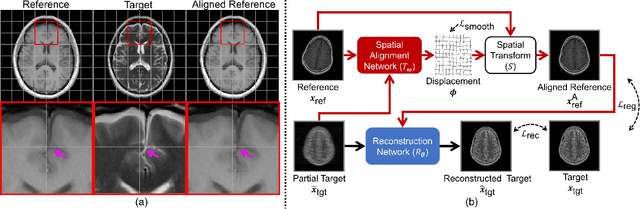
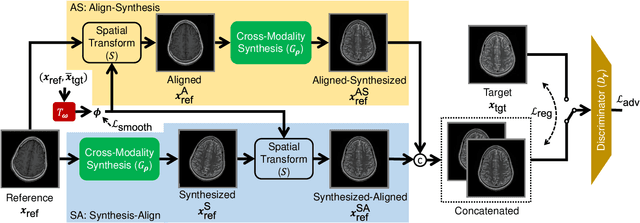

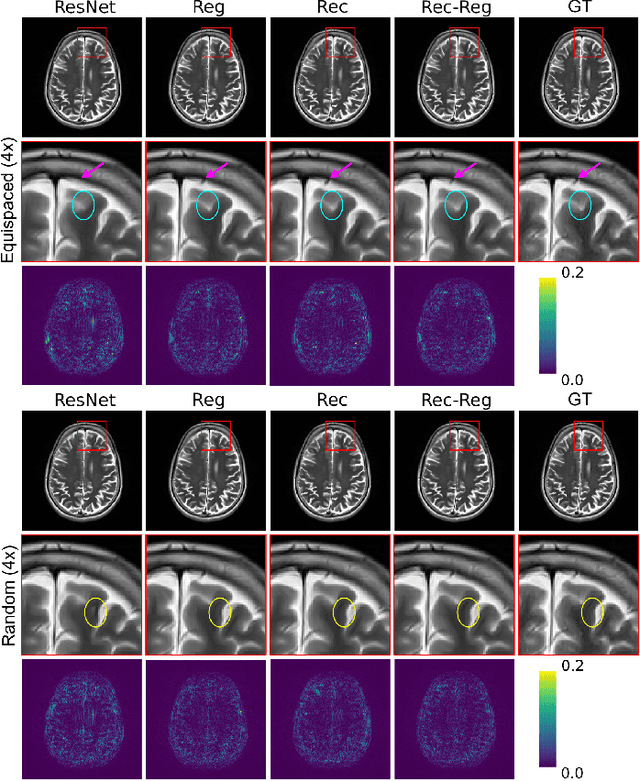
In clinical practice, magnetic resonance imaging (MRI) with multiple contrasts is usually acquired in a single study to assess different properties of the same region of interest in human body. The whole acquisition process can be accelerated by having one or more modalities under-sampled in the $k$-space. Recent researches demonstrate that, considering the redundancy between different contrasts or modalities, a target MRI modality under-sampled in the $k$-space can be more efficiently reconstructed with a fully-sampled MRI contrast as the reference modality. However, we find that the performance of the above multi-modal reconstruction can be negatively affected by subtle spatial misalignment between different contrasts, which is actually common in clinical practice. In this paper, to compensate for such spatial misalignment, we integrate the spatial alignment network with multi-modal reconstruction towards better reconstruction quality of the target modality. First, the spatial alignment network estimates the spatial misalignment between the fully-sampled reference and the under-sampled target images, and warps the reference image accordingly. Then, the aligned fully-sampled reference image joins the multi-modal reconstruction of the under-sampled target image. Also, considering the contrast difference between the target and the reference images, we particularly design the cross-modality-synthesis-based registration loss, in combination with the reconstruction loss, to jointly train the spatial alignment network and the reconstruction network. Experiments on both clinical MRI and multi-coil $k$-space raw data demonstrate the superiority and robustness of multi-modal MRI reconstruction empowered with our spatial alignment network. Our code is publicly available at \url{https://github.com/woxuankai/SpatialAlignmentNetwork}.
Real-Time Grasping Strategies Using Event Camera
Jul 15, 2021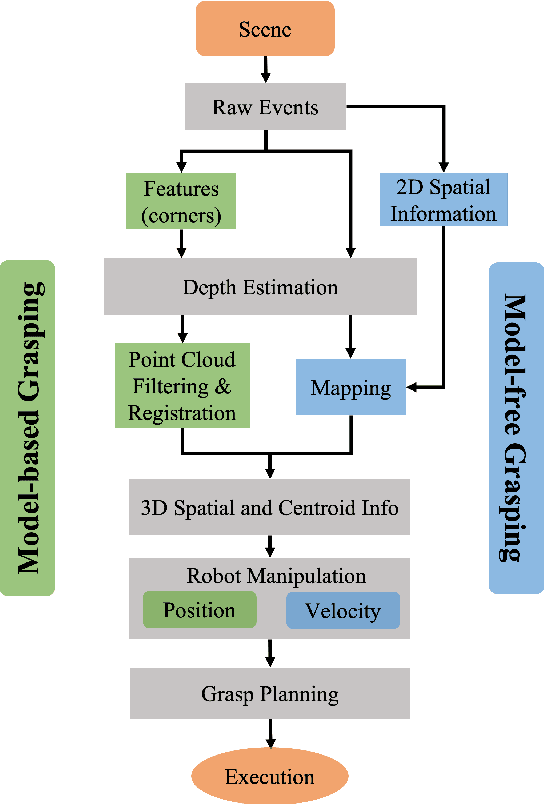

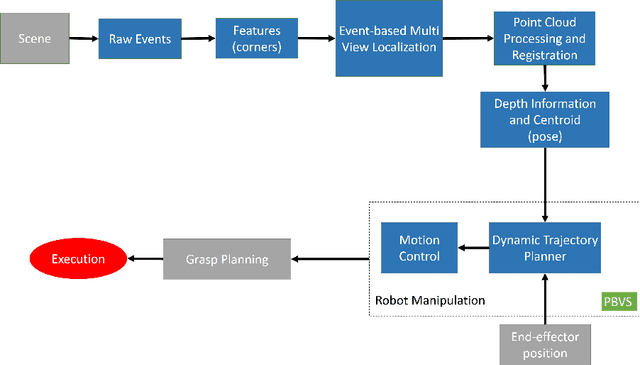

Robotic vision plays a key role for perceiving the environment in grasping applications. However, the conventional framed-based robotic vision, suffering from motion blur and low sampling rate, may not meet the automation needs of evolving industrial requirements. This paper, for the first time, proposes an event-based robotic grasping framework for multiple known and unknown objects in a cluttered scene. Compared with standard frame-based vision, neuromorphic vision has advantages of microsecond-level sampling rate and no motion blur. Building on that, the model-based and model-free approaches are developed for known and unknown objects' grasping respectively. For the model-based approach, event-based multi-view approach is used to localize the objects in the scene, and then point cloud processing allows for the clustering and registering of objects. Differently, the proposed model-free approach utilizes the developed event-based object segmentation, visual servoing and grasp planning to localize, align to, and grasp the targeting object. The proposed approaches are experimentally validated with objects of different sizes, using a UR10 robot with an eye-in-hand neuromorphic camera and a Barrett hand gripper. Moreover, the robustness of the two proposed event-based grasping approaches are validated in a low-light environment. This low-light operating ability shows a great advantage over the grasping using the standard frame-based vision. Furthermore, the developed model-free approach demonstrates the advantage of dealing with unknown object without prior knowledge compared to the proposed model-based approach.
Neuromorphic Event-Based Slip Detection and suppression in Robotic Grasping and Manipulation
Apr 15, 2020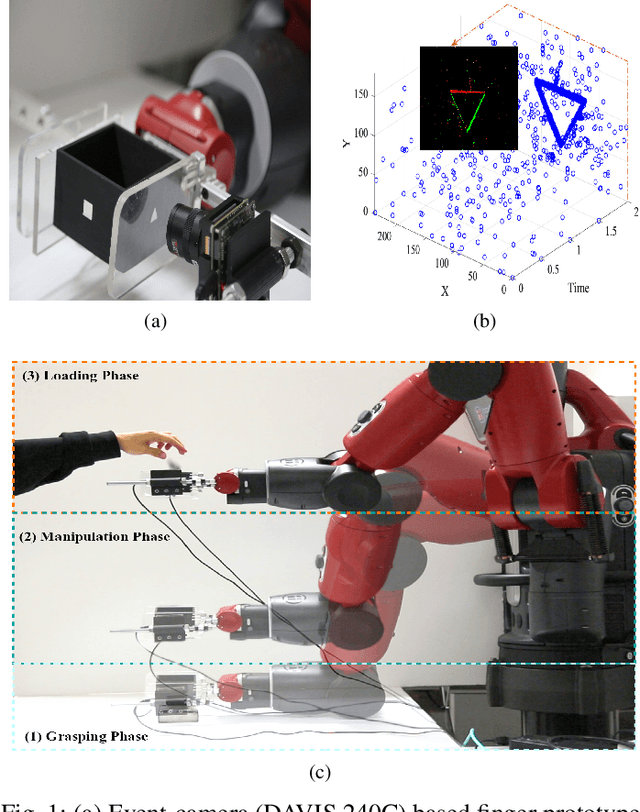
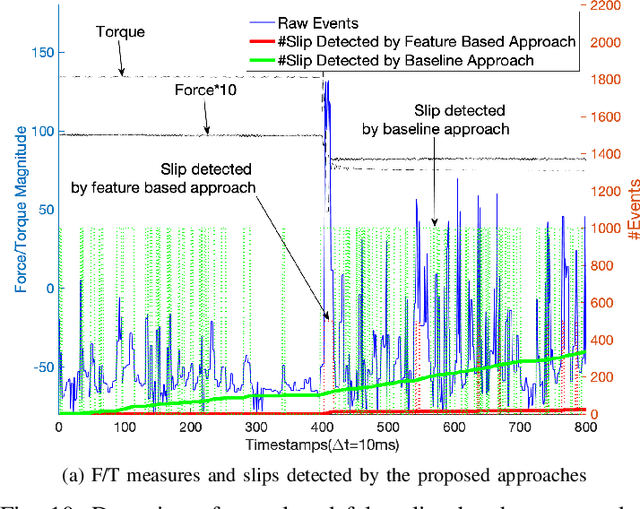
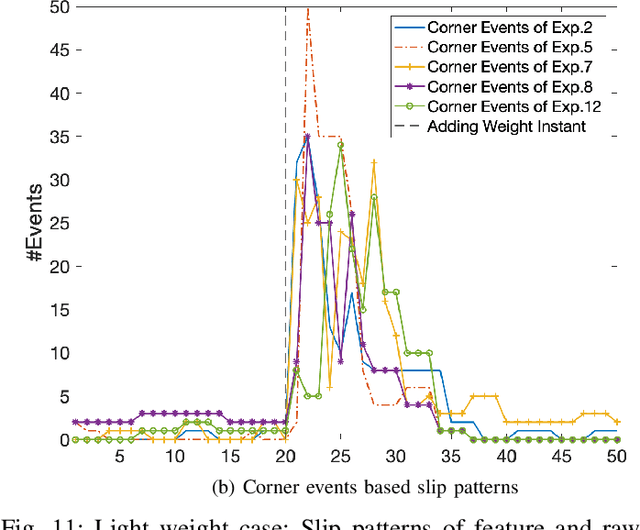
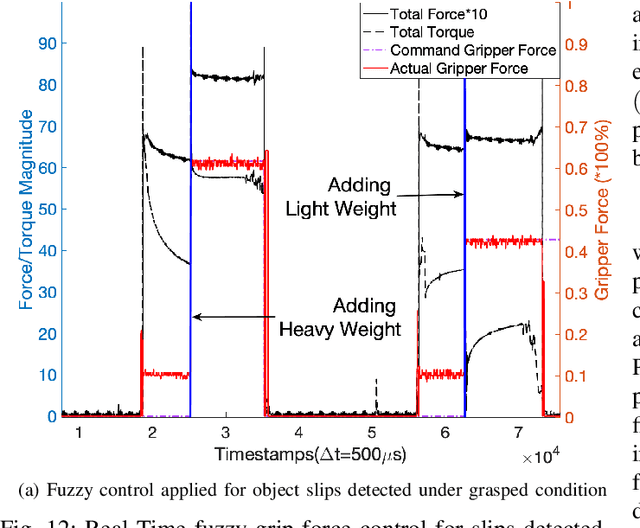
Slip detection is essential for robots to make robust grasping and fine manipulation. In this paper, a novel dynamic vision-based finger system for slip detection and suppression is proposed. We also present a baseline and feature based approach to detect object slips under illumination and vibration uncertainty. A threshold method is devised to autonomously sample noise in real-time to improve slip detection. Moreover, a fuzzy based suppression strategy using incipient slip feedback is proposed for regulating the grip force. A comprehensive experimental study of our proposed approaches under uncertainty and system for high-performance precision manipulation are presented. We also propose a slip metric to evaluate such performance quantitatively. Results indicate that the system can effectively detect incipient slip events at a sampling rate of 2kHz ($\Delta t = 500\mu s$) and suppress them before a gross slip occurs. The event-based approach holds promises to high precision manipulation task requirement in industrial manufacturing and household services.