 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGolden Goose: A Simple Trick to Synthesize Unlimited RLVR Tasks from Unverifiable Internet Text
Jan 30, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has become a cornerstone for unlocking complex reasoning in Large Language Models (LLMs). Yet, scaling up RL is bottlenecked by limited existing verifiable data, where improvements increasingly saturate over prolonged training. To overcome this, we propose Golden Goose, a simple trick to synthesize unlimited RLVR tasks from unverifiable internet text by constructing a multiple-choice question-answering version of the fill-in-the-middle task. Given a source text, we prompt an LLM to identify and mask key reasoning steps, then generate a set of diverse, plausible distractors. This enables us to leverage reasoning-rich unverifiable corpora typically excluded from prior RLVR data construction (e.g., science textbooks) to synthesize GooseReason-0.7M, a large-scale RLVR dataset with over 0.7 million tasks spanning mathematics, programming, and general scientific domains. Empirically, GooseReason effectively revives models saturated on existing RLVR data, yielding robust, sustained gains under continuous RL and achieving new state-of-the-art results for 1.5B and 4B-Instruct models across 15 diverse benchmarks. Finally, we deploy Golden Goose in a real-world setting, synthesizing RLVR tasks from raw FineWeb scrapes for the cybersecurity domain, where no prior RLVR data exists. Training Qwen3-4B-Instruct on the resulting data GooseReason-Cyber sets a new state-of-the-art in cybersecurity, surpassing a 7B domain-specialized model with extensive domain-specific pre-training and post-training. This highlights the potential of automatically scaling up RLVR data by exploiting abundant, reasoning-rich, unverifiable internet text.
FRoM-W1: Towards General Humanoid Whole-Body Control with Language Instructions
Jan 19, 2026Humanoid robots are capable of performing various actions such as greeting, dancing and even backflipping. However, these motions are often hard-coded or specifically trained, which limits their versatility. In this work, we present FRoM-W1, an open-source framework designed to achieve general humanoid whole-body motion control using natural language. To universally understand natural language and generate corresponding motions, as well as enable various humanoid robots to stably execute these motions in the physical world under gravity, FRoM-W1 operates in two stages: (a) H-GPT: utilizing massive human data, a large-scale language-driven human whole-body motion generation model is trained to generate diverse natural behaviors. We further leverage the Chain-of-Thought technique to improve the model's generalization in instruction understanding. (b) H-ACT: After retargeting generated human whole-body motions into robot-specific actions, a motion controller that is pretrained and further fine-tuned through reinforcement learning in physical simulation enables humanoid robots to accurately and stably perform corresponding actions. It is then deployed on real robots via a modular simulation-to-reality module. We extensively evaluate FRoM-W1 on Unitree H1 and G1 robots. Results demonstrate superior performance on the HumanML3D-X benchmark for human whole-body motion generation, and our introduced reinforcement learning fine-tuning consistently improves both motion tracking accuracy and task success rates of these humanoid robots. We open-source the entire FRoM-W1 framework and hope it will advance the development of humanoid intelligence.
DDSA: Dual-Domain Strategic Attack for Spatial-Temporal Efficiency in Adversarial Robustness Testing
Jan 18, 2026Image transmission and processing systems in resource-critical applications face significant challenges from adversarial perturbations that compromise mission-specific object classification. Current robustness testing methods require excessive computational resources through exhaustive frame-by-frame processing and full-image perturbations, proving impractical for large-scale deployments where massive image streams demand immediate processing. This paper presents DDSA (Dual-Domain Strategic Attack), a resource-efficient adversarial robustness testing framework that optimizes testing through temporal selectivity and spatial precision. We introduce a scenario-aware trigger function that identifies critical frames requiring robustness evaluation based on class priority and model uncertainty, and employ explainable AI techniques to locate influential pixel regions for targeted perturbation. Our dual-domain approach achieves substantial temporal-spatial resource conservation while maintaining attack effectiveness. The framework enables practical deployment of comprehensive adversarial robustness testing in resource-constrained real-time applications where computational efficiency directly impacts mission success.
Lying with Truths: Open-Channel Multi-Agent Collusion for Belief Manipulation via Generative Montage
Jan 04, 2026As large language models (LLMs) transition to autonomous agents synthesizing real-time information, their reasoning capabilities introduce an unexpected attack surface. This paper introduces a novel threat where colluding agents steer victim beliefs using only truthful evidence fragments distributed through public channels, without relying on covert communications, backdoors, or falsified documents. By exploiting LLMs' overthinking tendency, we formalize the first cognitive collusion attack and propose Generative Montage: a Writer-Editor-Director framework that constructs deceptive narratives through adversarial debate and coordinated posting of evidence fragments, causing victims to internalize and propagate fabricated conclusions. To study this risk, we develop CoPHEME, a dataset derived from real-world rumor events, and simulate attacks across diverse LLM families. Our results show pervasive vulnerability across 14 LLM families: attack success rates reach 74.4% for proprietary models and 70.6% for open-weights models. Counterintuitively, stronger reasoning capabilities increase susceptibility, with reasoning-specialized models showing higher attack success than base models or prompts. Furthermore, these false beliefs then cascade to downstream judges, achieving over 60% deception rates, highlighting a socio-technical vulnerability in how LLM-based agents interact with dynamic information environments. Our implementation and data are available at: https://github.com/CharlesJW222/Lying_with_Truth/tree/main.
Rethinking Multi-Agent Intelligence Through the Lens of Small-World Networks
Dec 19, 2025
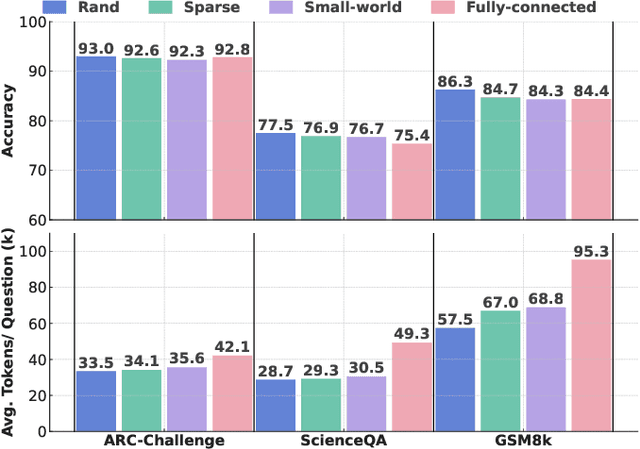
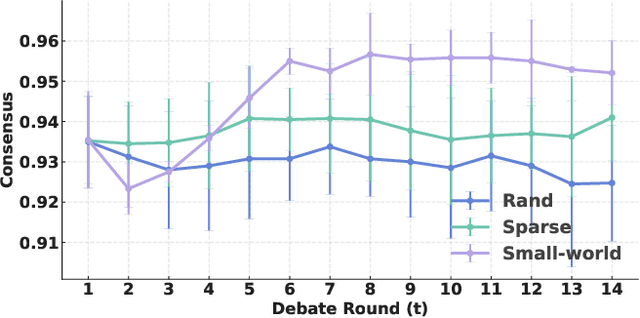
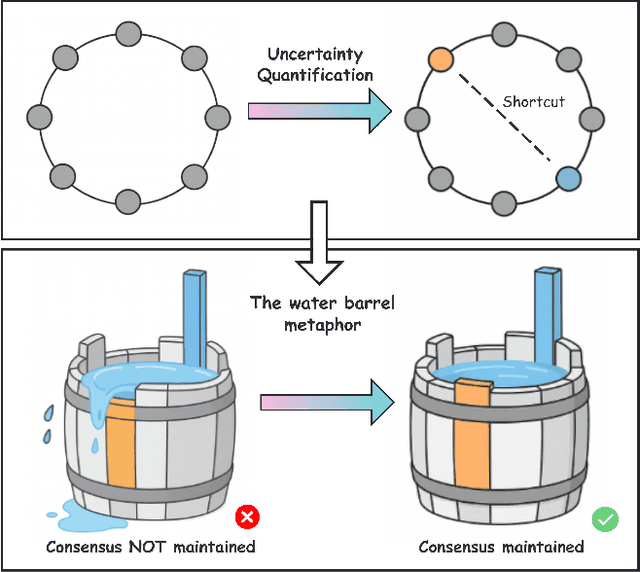
Large language models (LLMs) have enabled multi-agent systems (MAS) in which multiple agents argue, critique, and coordinate to solve complex tasks, making communication topology a first-class design choice. Yet most existing LLM-based MAS either adopt fully connected graphs, simple sparse rings, or ad-hoc dynamic selection, with little structural guidance. In this work, we revisit classic theory on small-world (SW) networks and ask: what changes if we treat SW connectivity as a design prior for MAS? We first bridge insights from neuroscience and complex networks to MAS, highlighting how SW structures balance local clustering and long-range integration. Using multi-agent debate (MAD) as a controlled testbed, experiment results show that SW connectivity yields nearly the same accuracy and token cost, while substantially stabilizing consensus trajectories. Building on this, we introduce an uncertainty-guided rewiring scheme for scaling MAS, where long-range shortcuts are added between epistemically divergent agents using LLM-oriented uncertainty signals (e.g., semantic entropy). This yields controllable SW structures that adapt to task difficulty and agent heterogeneity. Finally, we discuss broader implications of SW priors for MAS design, framing them as stabilizers of reasoning, enhancers of robustness, scalable coordinators, and inductive biases for emergent cognitive roles.
Chasing Consistency: Quantifying and Optimizing Human-Model Alignment in Chain-of-Thought Reasoning
Nov 09, 2025This paper presents a framework for evaluating and optimizing reasoning consistency in Large Language Models (LLMs) via a new metric, the Alignment Score, which quantifies the semantic alignment between model-generated reasoning chains and human-written reference chains in Chain-of-Thought (CoT) reasoning. Empirically, we find that 2-hop reasoning chains achieve the highest Alignment Score. To explain this phenomenon, we define four key error types: logical disconnection, thematic shift, redundant reasoning, and causal reversal, and show how each contributes to the degradation of the Alignment Score. Building on this analysis, we further propose Semantic Consistency Optimization Sampling (SCOS), a method that samples and favors chains with minimal alignment errors, significantly improving Alignment Scores by an average of 29.84% with longer reasoning chains, such as in 3-hop tasks.
ProfBench: Multi-Domain Rubrics requiring Professional Knowledge to Answer and Judge
Oct 21, 2025

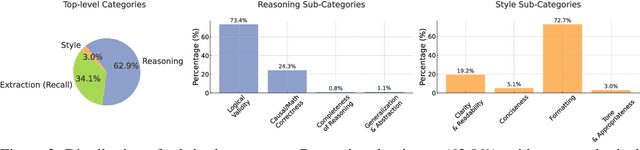

Evaluating progress in large language models (LLMs) is often constrained by the challenge of verifying responses, limiting assessments to tasks like mathematics, programming, and short-form question-answering. However, many real-world applications require evaluating LLMs in processing professional documents, synthesizing information, and generating comprehensive reports in response to user queries. We introduce ProfBench: a set of over 7000 response-criterion pairs as evaluated by human-experts with professional knowledge across Physics PhD, Chemistry PhD, Finance MBA and Consulting MBA. We build robust and affordable LLM-Judges to evaluate ProfBench rubrics, by mitigating self-enhancement bias and reducing the cost of evaluation by 2-3 orders of magnitude, to make it fair and accessible to the broader community. Our findings reveal that ProfBench poses significant challenges even for state-of-the-art LLMs, with top-performing models like GPT-5-high achieving only 65.9\% overall performance. Furthermore, we identify notable performance disparities between proprietary and open-weight models and provide insights into the role that extended thinking plays in addressing complex, professional-domain tasks. Data: https://huggingface.co/datasets/nvidia/ProfBench and Code: https://github.com/NVlabs/ProfBench
Distributed Nash Equilibrium Seeking Algorithm in Aggregative Games for Heterogeneous Multi-Robot Systems
Sep 19, 2025This paper develops a distributed Nash Equilibrium seeking algorithm for heterogeneous multi-robot systems. The algorithm utilises distributed optimisation and output control to achieve the Nash equilibrium by leveraging information shared among neighbouring robots. Specifically, we propose a distributed optimisation algorithm that calculates the Nash equilibrium as a tailored reference for each robot and designs output control laws for heterogeneous multi-robot systems to track it in an aggregative game. We prove that our algorithm is guaranteed to converge and result in efficient outcomes. The effectiveness of our approach is demonstrated through numerical simulations and empirical testing with physical robots.
MM-Food-100K: A 100,000-Sample Multimodal Food Intelligence Dataset with Verifiable Provenance
Aug 14, 2025



We present MM-Food-100K, a public 100,000-sample multimodal food intelligence dataset with verifiable provenance. It is a curated approximately 10% open subset of an original 1.2 million, quality-accepted corpus of food images annotated for a wide range of information (such as dish name, region of creation). The corpus was collected over six weeks from over 87,000 contributors using the Codatta contribution model, which combines community sourcing with configurable AI-assisted quality checks; each submission is linked to a wallet address in a secure off-chain ledger for traceability, with a full on-chain protocol on the roadmap. We describe the schema, pipeline, and QA, and validate utility by fine-tuning large vision-language models (ChatGPT 5, ChatGPT OSS, Qwen-Max) on image-based nutrition prediction. Fine-tuning yields consistent gains over out-of-box baselines across standard metrics; we report results primarily on the MM-Food-100K subset. We release MM-Food-100K for publicly free access and retain approximately 90% for potential commercial access with revenue sharing to contributors.
Iterative Distortion Cancellation Algorithms for Single-Sideband Systems
Aug 12, 2025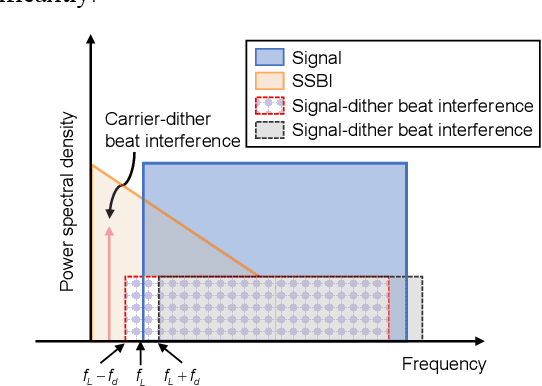
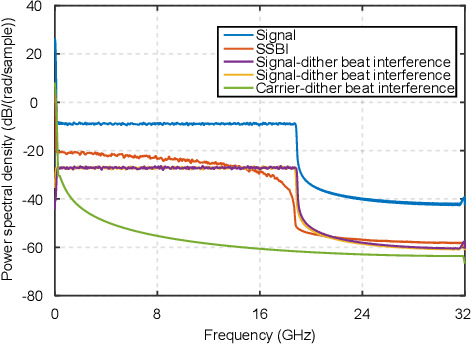
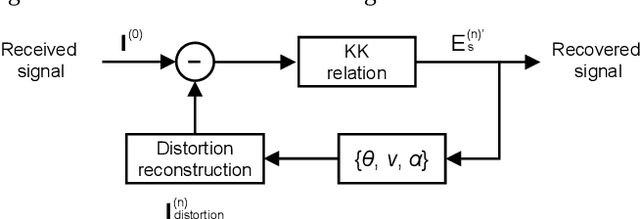
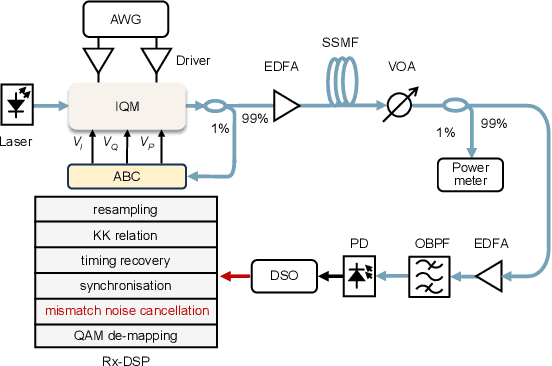
We propose an iterative distortion cancellation algorithm to digitally mitigate the impact of double-sideband dither signal amplitude from the automatic bias control module on Kramers-Kronig receivers without modifying physical layer structures. The algorithm utilizes the KK relation for initial signal decisions and reconstructs the distortion caused by dither signals. Experimental tests in back-to-back showed it improved tolerance to dither amplitudes up to 10% V{\pi}. For 80-km fiber transmission, the algorithm increased the receiver sensitivity by more than 1 dB, confirming the effectiveness of the proposed distortion cancellation method.