 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuse: Towards Reproducible Long-Form Song Generation with Fine-Grained Style Control
Jan 08, 2026Recent commercial systems such as Suno demonstrate strong capabilities in long-form song generation, while academic research remains largely non-reproducible due to the lack of publicly available training data, hindering fair comparison and progress. To this end, we release a fully open-source system for long-form song generation with fine-grained style conditioning, including a licensed synthetic dataset, training and evaluation pipelines, and Muse, an easy-to-deploy song generation model. The dataset consists of 116k fully licensed synthetic songs with automatically generated lyrics and style descriptions paired with audio synthesized by SunoV5. We train Muse via single-stage supervised finetuning of a Qwen-based language model extended with discrete audio tokens using MuCodec, without task-specific losses, auxiliary objectives, or additional architectural components. Our evaluations find that although Muse is trained with a modest data scale and model size, it achieves competitive performance on phoneme error rate, text--music style similarity, and audio aesthetic quality, while enabling controllable segment-level generation across different musical structures. All data, model weights, and training and evaluation pipelines will be publicly released, paving the way for continued progress in controllable long-form song generation research. The project repository is available at https://github.com/yuhui1038/Muse.
EAGLE: Episodic Appearance- and Geometry-aware Memory for Unified 2D-3D Visual Query Localization in Egocentric Vision
Nov 12, 2025Egocentric visual query localization is vital for embodied AI and VR/AR, yet remains challenging due to camera motion, viewpoint changes, and appearance variations. We present EAGLE, a novel framework that leverages episodic appearance- and geometry-aware memory to achieve unified 2D-3D visual query localization in egocentric vision. Inspired by avian memory consolidation, EAGLE synergistically integrates segmentation guided by an appearance-aware meta-learning memory (AMM), with tracking driven by a geometry-aware localization memory (GLM). This memory consolidation mechanism, through structured appearance and geometry memory banks, stores high-confidence retrieval samples, effectively supporting both long- and short-term modeling of target appearance variations. This enables precise contour delineation with robust spatial discrimination, leading to significantly improved retrieval accuracy. Furthermore, by integrating the VQL-2D output with a visual geometry grounded Transformer (VGGT), we achieve a efficient unification of 2D and 3D tasks, enabling rapid and accurate back-projection into 3D space. Our method achieves state-ofthe-art performance on the Ego4D-VQ benchmark.
From Scores to Preferences: Redefining MOS Benchmarking for Speech Quality Reward Modeling
Oct 01, 2025Assessing the perceptual quality of synthetic speech is crucial for guiding the development and refinement of speech generation models. However, it has traditionally relied on human subjective ratings such as the Mean Opinion Score (MOS), which depend on manual annotations and often suffer from inconsistent rating standards and poor reproducibility. To address these limitations, we introduce MOS-RMBench, a unified benchmark that reformulates diverse MOS datasets into a preference-comparison setting, enabling rigorous evaluation across different datasets. Building on MOS-RMBench, we systematically construct and evaluate three paradigms for reward modeling: scalar reward models, semi-scalar reward models, and generative reward models (GRMs). Our experiments reveal three key findings: (1) scalar models achieve the strongest overall performance, consistently exceeding 74% accuracy; (2) most models perform considerably worse on synthetic speech than on human speech; and (3) all models struggle on pairs with very small MOS differences. To improve performance on these challenging pairs, we propose a MOS-aware GRM that incorporates an MOS-difference-based reward function, enabling the model to adaptively scale rewards according to the difficulty of each sample pair. Experimental results show that the MOS-aware GRM significantly improves fine-grained quality discrimination and narrows the gap with scalar models on the most challenging cases. We hope this work will establish both a benchmark and a methodological framework to foster more rigorous and scalable research in automatic speech quality assessment.
MDAR: A Multi-scene Dynamic Audio Reasoning Benchmark
Sep 26, 2025The ability to reason from audio, including speech, paralinguistic cues, environmental sounds, and music, is essential for AI agents to interact effectively in real-world scenarios. Existing benchmarks mainly focus on static or single-scene settings and do not fully capture scenarios where multiple speakers, unfolding events, and heterogeneous audio sources interact. To address these challenges, we introduce MDAR, a benchmark for evaluating models on complex, multi-scene, and dynamically evolving audio reasoning tasks. MDAR comprises 3,000 carefully curated question-answer pairs linked to diverse audio clips, covering five categories of complex reasoning and spanning three question types. We benchmark 26 state-of-the-art audio language models on MDAR and observe that they exhibit limitations in complex reasoning tasks. On single-choice questions, Qwen2.5-Omni (open-source) achieves 76.67% accuracy, whereas GPT-4o Audio (closed-source) reaches 68.47%; however, GPT-4o Audio substantially outperforms Qwen2.5-Omni on the more challenging multiple-choice and open-ended tasks. Across all three question types, no model achieves 80% performance. These findings underscore the unique challenges posed by MDAR and its value as a benchmark for advancing audio reasoning research.Code and benchmark can be found at https://github.com/luckyerr/MDAR.
Speech-Language Models with Decoupled Tokenizers and Multi-Token Prediction
Jun 14, 2025
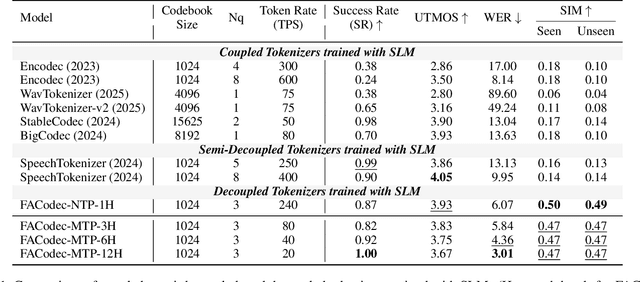
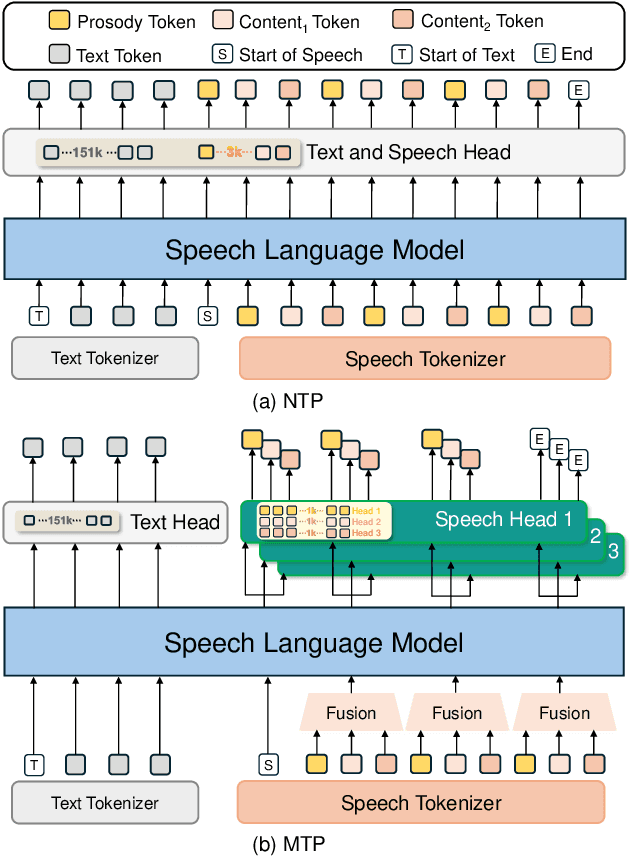
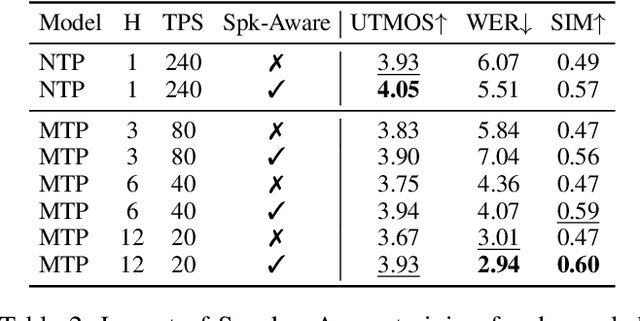
Speech-language models (SLMs) offer a promising path toward unifying speech and text understanding and generation. However, challenges remain in achieving effective cross-modal alignment and high-quality speech generation. In this work, we systematically investigate the impact of key components (i.e., speech tokenizers, speech heads, and speaker modeling) on the performance of LLM-centric SLMs. We compare coupled, semi-decoupled, and fully decoupled speech tokenizers under a fair SLM framework and find that decoupled tokenization significantly improves alignment and synthesis quality. To address the information density mismatch between speech and text, we introduce multi-token prediction (MTP) into SLMs, enabling each hidden state to decode multiple speech tokens. This leads to up to 12$\times$ faster decoding and a substantial drop in word error rate (from 6.07 to 3.01). Furthermore, we propose a speaker-aware generation paradigm and introduce RoleTriviaQA, a large-scale role-playing knowledge QA benchmark with diverse speaker identities. Experiments demonstrate that our methods enhance both knowledge understanding and speaker consistency.
Predicting Large Language Model Capabilities on Closed-Book QA Tasks Using Only Information Available Prior to Training
Feb 06, 2025The GPT-4 technical report from OpenAI suggests that model performance on specific tasks can be predicted prior to training, though methodologies remain unspecified. This approach is crucial for optimizing resource allocation and ensuring data alignment with target tasks. To achieve this vision, we focus on predicting performance on Closed-book Question Answering (CBQA) tasks, which are closely tied to pre-training data and knowledge retention. We address three major challenges: 1) mastering the entire pre-training process, especially data construction; 2) evaluating a model's knowledge retention; and 3) predicting task-specific knowledge retention using only information available prior to training. To tackle these challenges, we pre-train three large language models (i.e., 1.6B, 7B, and 13B) using 560k dollars and 520k GPU hours. We analyze the pre-training data with knowledge triples and assess knowledge retention using established methods. Additionally, we introduce the SMI metric, an information-theoretic measure that quantifies the relationship between pre-training data, model size, and task-specific knowledge retention. Our experiments reveal a strong linear correlation ($\text{R}^2 > 0.84$) between the SMI metric and the model's accuracy on CBQA tasks across models of varying sizes (i.e., 1.1B, 1.6B, 7B, and 13B). The dataset, model, and code are available at https://github.com/yuhui1038/SMI.
TranStable: Towards Robust Pixel-level Online Video Stabilization by Jointing Transformer and CNN
Jan 25, 2025Video stabilization often struggles with distortion and excessive cropping. This paper proposes a novel end-to-end framework, named TranStable, to address these challenges, comprising a genera tor and a discriminator. We establish TransformerUNet (TUNet) as the generator to utilize the Hierarchical Adaptive Fusion Module (HAFM), integrating Transformer and CNN to leverage both global and local features across multiple visual cues. By modeling frame-wise relationships, it generates robust pixel-level warping maps for stable geometric transformations. Furthermore, we design the Stability Discriminator Module (SDM), which provides pixel-wise supervision for authenticity and consistency in training period, ensuring more complete field-of-view while minimizing jitter artifacts and enhancing visual fidelity. Extensive experiments on NUS, DeepStab, and Selfie benchmarks demonstrate state-of-the-art performance.
Mutual Information as Intrinsic Reward of Reinforcement Learning Agents for On-demand Ride Pooling
Jan 07, 2024
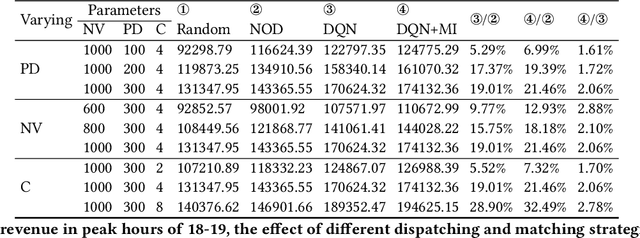
The emergence of on-demand ride pooling services allows each vehicle to serve multiple passengers at a time, thus increasing drivers' income and enabling passengers to travel at lower prices than taxi/car on-demand services (only one passenger can be assigned to a car at a time like UberX and Lyft). Although on-demand ride pooling services can bring so many benefits, ride pooling services need a well-defined matching strategy to maximize the benefits for all parties (passengers, drivers, aggregation companies and environment), in which the regional dispatching of vehicles has a significant impact on the matching and revenue. Existing algorithms often only consider revenue maximization, which makes it difficult for requests with unusual distribution to get a ride. How to increase revenue while ensuring a reasonable assignment of requests brings a challenge to ride pooling service companies (aggregation companies). In this paper, we propose a framework for vehicle dispatching for ride pooling tasks, which splits the city into discrete dispatching regions and uses the reinforcement learning (RL) algorithm to dispatch vehicles in these regions. We also consider the mutual information (MI) between vehicle and order distribution as the intrinsic reward of the RL algorithm to improve the correlation between their distributions, thus ensuring the possibility of getting a ride for unusually distributed requests. In experimental results on a real-world taxi dataset, we demonstrate that our framework can significantly increase revenue up to an average of 3\% over the existing best on-demand ride pooling method.