 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChartE$^{3}$: A Comprehensive Benchmark for End-to-End Chart Editing
Jan 29, 2026Charts are a fundamental visualization format for structured data analysis. Enabling end-to-end chart editing according to user intent is of great practical value, yet remains challenging due to the need for both fine-grained control and global structural consistency. Most existing approaches adopt pipeline-based designs, where natural language or code serves as an intermediate representation, limiting their ability to faithfully execute complex edits. We introduce ChartE$^{3}$, an End-to-End Chart Editing benchmark that directly evaluates models without relying on intermediate natural language programs or code-level supervision. ChartE$^{3}$ focuses on two complementary editing dimensions: local editing, which involves fine-grained appearance changes such as font or color adjustments, and global editing, which requires holistic, data-centric transformations including data filtering and trend line addition. ChartE$^{3}$ contains over 1,200 high-quality samples constructed via a well-designed data pipeline with human curation. Each sample is provided as a triplet of a chart image, its underlying code, and a multimodal editing instruction, enabling evaluation from both objective and subjective perspectives. Extensive benchmarking of state-of-the-art multimodal large language models reveals substantial performance gaps, particularly on global editing tasks, highlighting critical limitations in current end-to-end chart editing capabilities.
LifeAgentBench: A Multi-dimensional Benchmark and Agent for Personal Health Assistants in Digital Health
Jan 20, 2026Personalized digital health support requires long-horizon, cross-dimensional reasoning over heterogeneous lifestyle signals, and recent advances in mobile sensing and large language models (LLMs) make such support increasingly feasible. However, the capabilities of current LLMs in this setting remain unclear due to the lack of systematic benchmarks. In this paper, we introduce LifeAgentBench, a large-scale QA benchmark for long-horizon, cross-dimensional, and multi-user lifestyle health reasoning, containing 22,573 questions spanning from basic retrieval to complex reasoning. We release an extensible benchmark construction pipeline and a standardized evaluation protocol to enable reliable and scalable assessment of LLM-based health assistants. We then systematically evaluate 11 leading LLMs on LifeAgentBench and identify key bottlenecks in long-horizon aggregation and cross-dimensional reasoning. Motivated by these findings, we propose LifeAgent as a strong baseline agent for health assistant that integrates multi-step evidence retrieval with deterministic aggregation, achieving significant improvements compared with two widely used baselines. Case studies further demonstrate its potential in realistic daily-life scenarios. The benchmark is publicly available at https://anonymous.4open.science/r/LifeAgentBench-CE7B.
Which Reasoning Trajectories Teach Students to Reason Better? A Simple Metric of Informative Alignment
Jan 20, 2026Long chain-of-thought (CoT) trajectories provide rich supervision signals for distilling reasoning from teacher to student LLMs. However, both prior work and our experiments show that trajectories from stronger teachers do not necessarily yield better students, highlighting the importance of data-student suitability in distillation. Existing methods assess suitability primarily through student likelihood, favoring trajectories that closely align with the model's current behavior but overlooking more informative ones. Addressing this, we propose Rank-Surprisal Ratio (RSR), a simple metric that captures both alignment and informativeness to assess the suitability of a reasoning trajectory. RSR is motivated by the observation that effective trajectories typically combine low absolute probability with relatively high-ranked tokens under the student model, balancing learning signal strength and behavioral alignment. Concretely, RSR is defined as the ratio of a trajectory's average token-wise rank to its average negative log-likelihood, and is straightforward to compute and interpret. Across five student models and reasoning trajectories from 11 diverse teachers, RSR strongly correlates with post-training performance (average Spearman 0.86), outperforming existing metrics. We further demonstrate its practical utility in both trajectory selection and teacher selection.
MHA2MLA-VLM: Enabling DeepSeek's Economical Multi-Head Latent Attention across Vision-Language Models
Jan 16, 2026As vision-language models (VLMs) tackle increasingly complex and multimodal tasks, the rapid growth of Key-Value (KV) cache imposes significant memory and computational bottlenecks during inference. While Multi-Head Latent Attention (MLA) offers an effective means to compress the KV cache and accelerate inference, adapting existing VLMs to the MLA architecture without costly pretraining remains largely unexplored. In this work, we present MHA2MLA-VLM, a parameter-efficient and multimodal-aware framework for converting off-the-shelf VLMs to MLA. Our approach features two core techniques: (1) a modality-adaptive partial-RoPE strategy that supports both traditional and multimodal settings by selectively masking nonessential dimensions, and (2) a modality-decoupled low-rank approximation method that independently compresses the visual and textual KV spaces. Furthermore, we introduce parameter-efficient fine-tuning to minimize adaptation cost and demonstrate that minimizing output activation error, rather than parameter distance, substantially reduces performance loss. Extensive experiments on three representative VLMs show that MHA2MLA-VLM restores original model performance with minimal supervised data, significantly reduces KV cache footprint, and integrates seamlessly with KV quantization.
MDAR: A Multi-scene Dynamic Audio Reasoning Benchmark
Sep 26, 2025The ability to reason from audio, including speech, paralinguistic cues, environmental sounds, and music, is essential for AI agents to interact effectively in real-world scenarios. Existing benchmarks mainly focus on static or single-scene settings and do not fully capture scenarios where multiple speakers, unfolding events, and heterogeneous audio sources interact. To address these challenges, we introduce MDAR, a benchmark for evaluating models on complex, multi-scene, and dynamically evolving audio reasoning tasks. MDAR comprises 3,000 carefully curated question-answer pairs linked to diverse audio clips, covering five categories of complex reasoning and spanning three question types. We benchmark 26 state-of-the-art audio language models on MDAR and observe that they exhibit limitations in complex reasoning tasks. On single-choice questions, Qwen2.5-Omni (open-source) achieves 76.67% accuracy, whereas GPT-4o Audio (closed-source) reaches 68.47%; however, GPT-4o Audio substantially outperforms Qwen2.5-Omni on the more challenging multiple-choice and open-ended tasks. Across all three question types, no model achieves 80% performance. These findings underscore the unique challenges posed by MDAR and its value as a benchmark for advancing audio reasoning research.Code and benchmark can be found at https://github.com/luckyerr/MDAR.
Feedback-Driven Tool-Use Improvements in Large Language Models via Automated Build Environments
Aug 12, 2025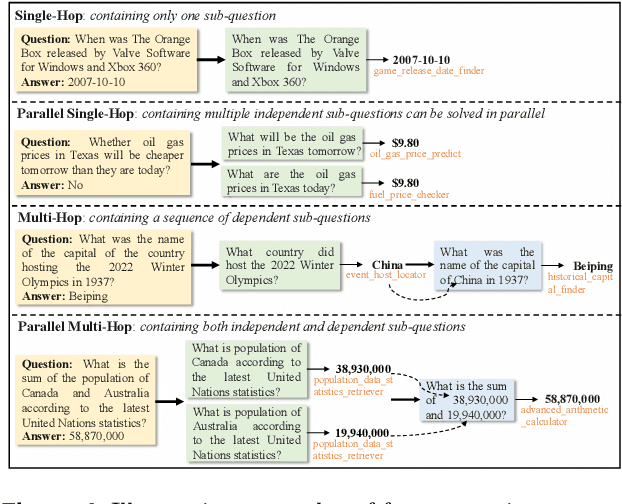

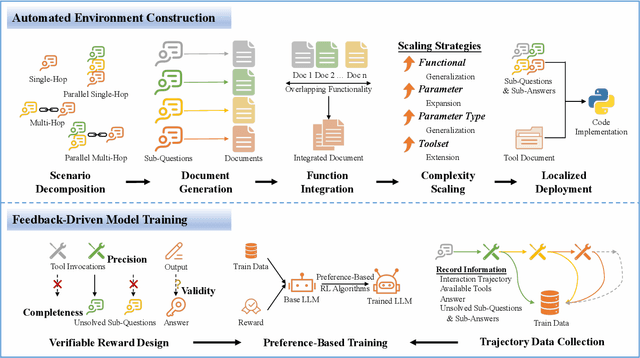
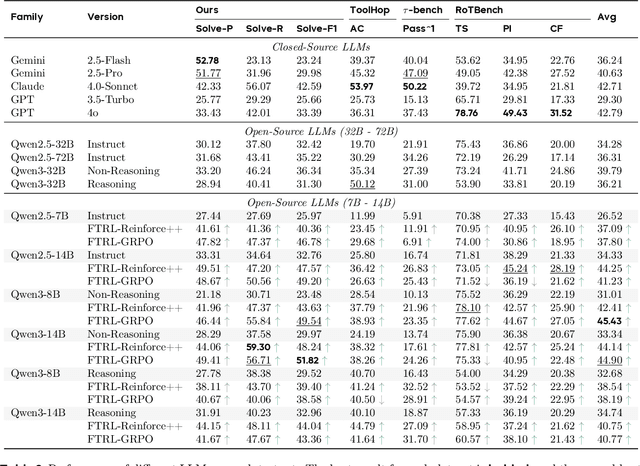
Effective tool use is essential for large language models (LLMs) to interact meaningfully with their environment. However, progress is limited by the lack of efficient reinforcement learning (RL) frameworks specifically designed for tool use, due to challenges in constructing stable training environments and designing verifiable reward mechanisms. To address this, we propose an automated environment construction pipeline, incorporating scenario decomposition, document generation, function integration, complexity scaling, and localized deployment. This enables the creation of high-quality training environments that provide detailed and measurable feedback without relying on external tools. Additionally, we introduce a verifiable reward mechanism that evaluates both the precision of tool use and the completeness of task execution. When combined with trajectory data collected from the constructed environments, this mechanism integrates seamlessly with standard RL algorithms to facilitate feedback-driven model training. Experiments on LLMs of varying scales demonstrate that our approach significantly enhances the models' tool-use performance without degrading their general capabilities, regardless of inference modes or training algorithms. Our analysis suggests that these gains result from improved context understanding and reasoning, driven by updates to the lower-layer MLP parameters in models.
Speech-Language Models with Decoupled Tokenizers and Multi-Token Prediction
Jun 14, 2025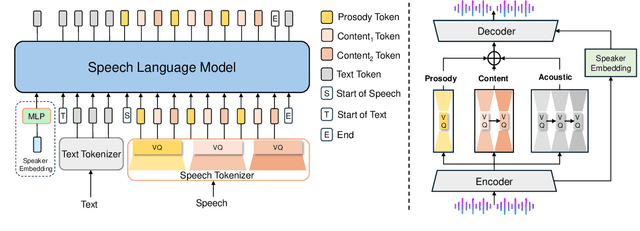
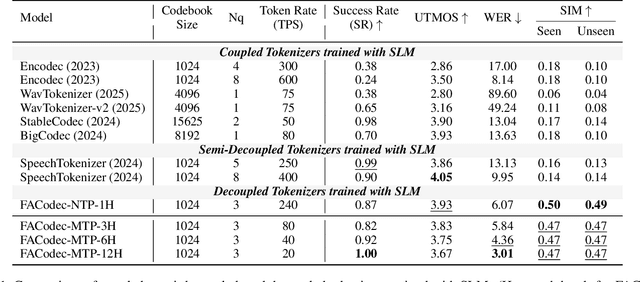
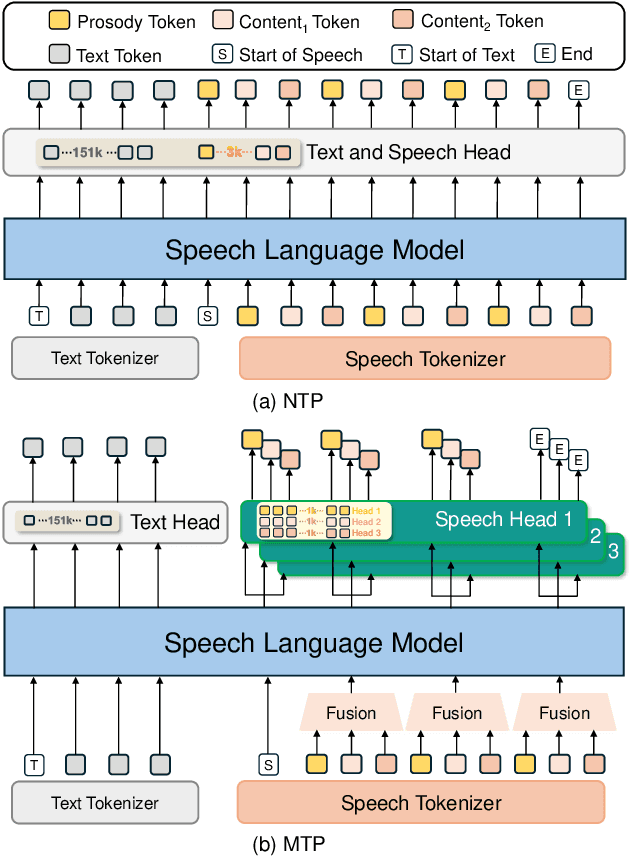
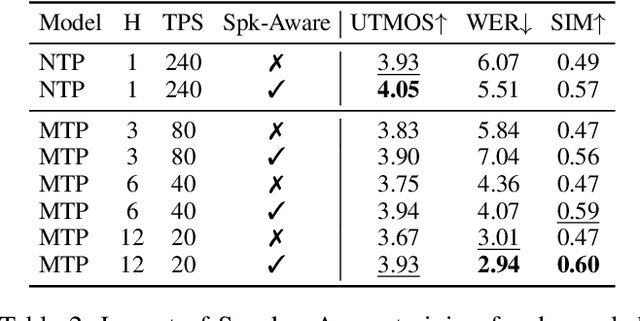
Speech-language models (SLMs) offer a promising path toward unifying speech and text understanding and generation. However, challenges remain in achieving effective cross-modal alignment and high-quality speech generation. In this work, we systematically investigate the impact of key components (i.e., speech tokenizers, speech heads, and speaker modeling) on the performance of LLM-centric SLMs. We compare coupled, semi-decoupled, and fully decoupled speech tokenizers under a fair SLM framework and find that decoupled tokenization significantly improves alignment and synthesis quality. To address the information density mismatch between speech and text, we introduce multi-token prediction (MTP) into SLMs, enabling each hidden state to decode multiple speech tokens. This leads to up to 12$\times$ faster decoding and a substantial drop in word error rate (from 6.07 to 3.01). Furthermore, we propose a speaker-aware generation paradigm and introduce RoleTriviaQA, a large-scale role-playing knowledge QA benchmark with diverse speaker identities. Experiments demonstrate that our methods enhance both knowledge understanding and speaker consistency.
Mitigating Object Hallucinations in MLLMs via Multi-Frequency Perturbations
Mar 19, 2025Recently, multimodal large language models (MLLMs) have demonstrated remarkable performance in visual-language tasks. However, the authenticity of the responses generated by MLLMs is often compromised by object hallucinations. We identify that a key cause of these hallucinations is the model's over-susceptibility to specific image frequency features in detecting objects. In this paper, we introduce Multi-Frequency Perturbations (MFP), a simple, cost-effective, and pluggable method that leverages both low-frequency and high-frequency features of images to perturb visual feature representations and explicitly suppress redundant frequency-domain features during inference, thereby mitigating hallucinations. Experimental results demonstrate that our method significantly mitigates object hallucinations across various model architectures. Furthermore, as a training-time method, MFP can be combined with inference-time methods to achieve state-of-the-art performance on the CHAIR benchmark.
EliteKV: Scalable KV Cache Compression via RoPE Frequency Selection and Joint Low-Rank Projection
Mar 03, 2025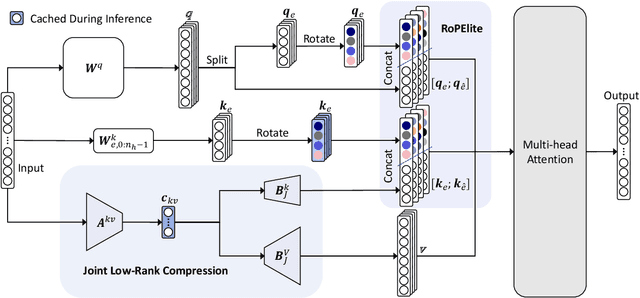
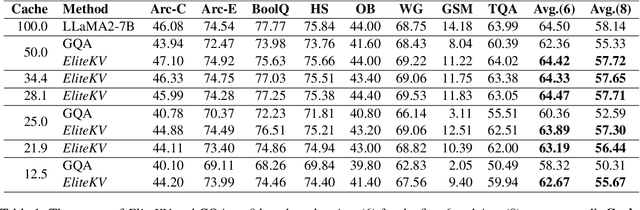


Rotary Position Embedding (RoPE) enables each attention head to capture multi-frequency information along the sequence dimension and is widely applied in foundation models. However, the nonlinearity introduced by RoPE complicates optimization of the key state in the Key-Value (KV) cache for RoPE-based attention. Existing KV cache compression methods typically store key state before rotation and apply the transformation during decoding, introducing additional computational overhead. This paper introduces EliteKV, a flexible modification framework for RoPE-based models supporting variable KV cache compression ratios. EliteKV first identifies the intrinsic frequency preference of each head using RoPElite, selectively restoring linearity to certain dimensions of key within attention computation. Building on this, joint low-rank compression of key and value enables partial cache sharing. Experimental results show that with minimal uptraining on only $0.6\%$ of the original training data, RoPE-based models achieve a $75\%$ reduction in KV cache size while preserving performance within a negligible margin. Furthermore, EliteKV consistently performs well across models of different scales within the same family.
Predicting Large Language Model Capabilities on Closed-Book QA Tasks Using Only Information Available Prior to Training
Feb 06, 2025The GPT-4 technical report from OpenAI suggests that model performance on specific tasks can be predicted prior to training, though methodologies remain unspecified. This approach is crucial for optimizing resource allocation and ensuring data alignment with target tasks. To achieve this vision, we focus on predicting performance on Closed-book Question Answering (CBQA) tasks, which are closely tied to pre-training data and knowledge retention. We address three major challenges: 1) mastering the entire pre-training process, especially data construction; 2) evaluating a model's knowledge retention; and 3) predicting task-specific knowledge retention using only information available prior to training. To tackle these challenges, we pre-train three large language models (i.e., 1.6B, 7B, and 13B) using 560k dollars and 520k GPU hours. We analyze the pre-training data with knowledge triples and assess knowledge retention using established methods. Additionally, we introduce the SMI metric, an information-theoretic measure that quantifies the relationship between pre-training data, model size, and task-specific knowledge retention. Our experiments reveal a strong linear correlation ($\text{R}^2 > 0.84$) between the SMI metric and the model's accuracy on CBQA tasks across models of varying sizes (i.e., 1.1B, 1.6B, 7B, and 13B). The dataset, model, and code are available at https://github.com/yuhui1038/SMI.