 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHT-GNN: Hyper-Temporal Graph Neural Network for Customer Lifetime Value Prediction in Baidu Ads
Jan 19, 2026Lifetime value (LTV) prediction is crucial for news feed advertising, enabling platforms to optimize bidding and budget allocation for long-term revenue growth. However, it faces two major challenges: (1) demographic-based targeting creates segment-specific LTV distributions with large value variations across user groups; and (2) dynamic marketing strategies generate irregular behavioral sequences where engagement patterns evolve rapidly. We propose a Hyper-Temporal Graph Neural Network (HT-GNN), which jointly models demographic heterogeneity and temporal dynamics through three key components: (i) a hypergraph-supervised module capturing inter-segment relationships; (ii) a transformer-based temporal encoder with adaptive weighting; and (iii) a task-adaptive mixture-of-experts with dynamic prediction towers for multi-horizon LTV forecasting. Experiments on \textit{Baidu Ads} with 15 million users demonstrate that HT-GNN consistently outperforms state-of-the-art methods across all metrics and prediction horizons.
DP2FL: Dual Prompt Personalized Federated Learning in Foundation Models
Apr 23, 2025



Personalized federated learning (PFL) has garnered significant attention for its ability to address heterogeneous client data distributions while preserving data privacy. However, when local client data is limited, deep learning models often suffer from insufficient training, leading to suboptimal performance. Foundation models, such as CLIP (Contrastive Language-Image Pretraining), exhibit strong feature extraction capabilities and can alleviate this issue by fine-tuning on limited local data. Despite their potential, foundation models are rarely utilized in federated learning scenarios, and challenges related to integrating new clients remain largely unresolved. To address these challenges, we propose the Dual Prompt Personalized Federated Learning (DP2FL) framework, which introduces dual prompts and an adaptive aggregation strategy. DP2FL combines global task awareness with local data-driven insights, enabling local models to achieve effective generalization while remaining adaptable to specific data distributions. Moreover, DP2FL introduces a global model that enables prediction on new data sources and seamlessly integrates newly added clients without requiring retraining. Experimental results in highly heterogeneous environments validate the effectiveness of DP2FL's prompt design and aggregation strategy, underscoring the advantages of prediction on novel data sources and demonstrating the seamless integration of new clients into the federated learning framework.
Have the VLMs Lost Confidence? A Study of Sycophancy in VLMs
Oct 15, 2024



In the study of LLMs, sycophancy represents a prevalent hallucination that poses significant challenges to these models. Specifically, LLMs often fail to adhere to original correct responses, instead blindly agreeing with users' opinions, even when those opinions are incorrect or malicious. However, research on sycophancy in visual language models (VLMs) has been scarce. In this work, we extend the exploration of sycophancy from LLMs to VLMs, introducing the MM-SY benchmark to evaluate this phenomenon. We present evaluation results from multiple representative models, addressing the gap in sycophancy research for VLMs. To mitigate sycophancy, we propose a synthetic dataset for training and employ methods based on prompts, supervised fine-tuning, and DPO. Our experiments demonstrate that these methods effectively alleviate sycophancy in VLMs. Additionally, we probe VLMs to assess the semantic impact of sycophancy and analyze the attention distribution of visual tokens. Our findings indicate that the ability to prevent sycophancy is predominantly observed in higher layers of the model. The lack of attention to image knowledge in these higher layers may contribute to sycophancy, and enhancing image attention at high layers proves beneficial in mitigating this issue.
Etalumis: Bringing Probabilistic Programming to Scientific Simulators at Scale
Jul 08, 2019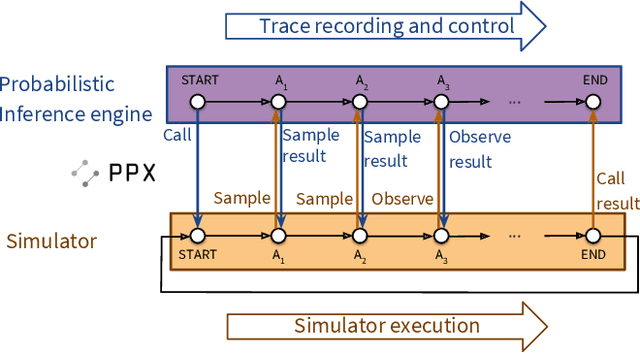

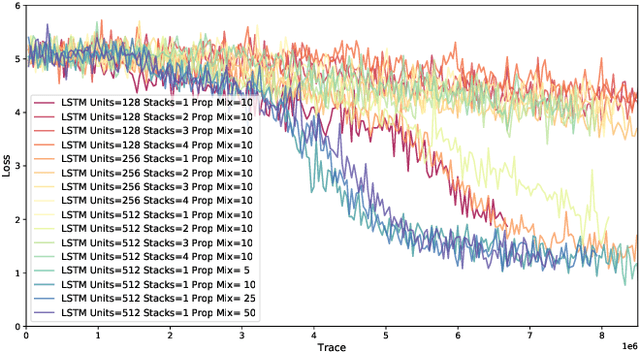
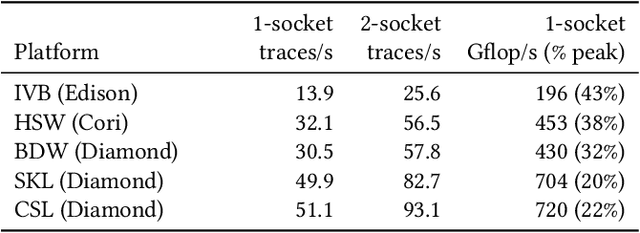
Probabilistic programming languages (PPLs) are receiving widespread attention for performing Bayesian inference in complex generative models. However, applications to science remain limited because of the impracticability of rewriting complex scientific simulators in a PPL, the computational cost of inference, and the lack of scalable implementations. To address these, we present a novel PPL framework that couples directly to existing scientific simulators through a cross-platform probabilistic execution protocol and provides Markov chain Monte Carlo (MCMC) and deep-learning-based inference compilation (IC) engines for tractable inference. To guide IC inference, we perform distributed training of a dynamic 3DCNN--LSTM architecture with a PyTorch-MPI-based framework on 1,024 32-core CPU nodes of the Cori supercomputer with a global minibatch size of 128k: achieving a performance of 450 Tflop/s through enhancements to PyTorch. We demonstrate a Large Hadron Collider (LHC) use-case with the C++ Sherpa simulator and achieve the largest-scale posterior inference in a Turing-complete PPL.
CUTIE: Learning to Understand Documents with Convolutional Universal Text Information Extractor
Apr 04, 2019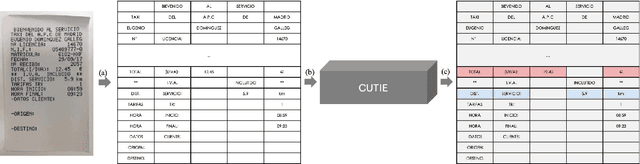
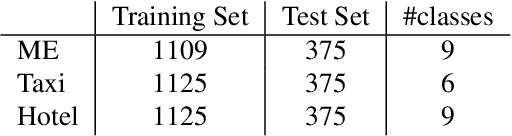
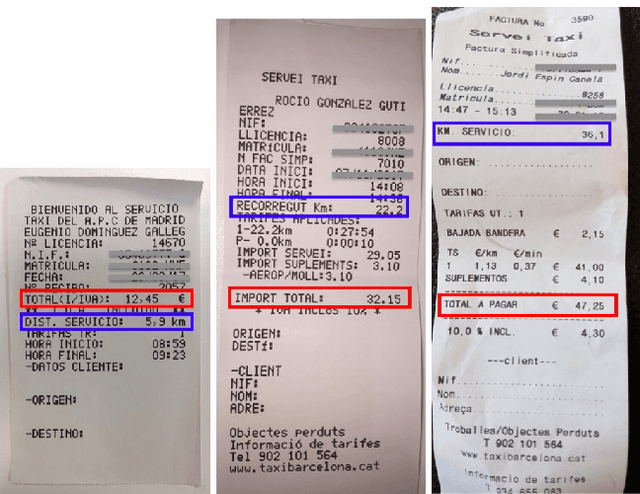

Extracting key information from documents, such as receipts or invoices, and preserving the interested texts to structured data is crucial in the document-intensive streamline processes of office automation in areas that includes but not limited to accounting, financial, and taxation areas. To avoid designing expert rules for each specific type of document, some published works attempt to tackle the problem by learning a model to explore the semantic context in text sequences based on the Named Entity Recognition (NER) method in the NLP field. In this paper, we propose to harness the effective information from both semantic meaning and spatial distribution of texts in documents. Specifically, our proposed model, Convolutional Universal Text Information Extractor (CUTIE), applies convolutional neural networks on gridded texts where texts are embedded as features with semantical connotations. We further explore the effect of employing different structures of convolutional neural network and propose a fast and portable structure. We demonstrate the effectiveness of the proposed method on a dataset with up to $4,484$ labelled receipts, without any pre-training or post-processing, achieving state of the art performance that is much higher than BERT but with only $1/10$ parameters and without requiring the $3,300$M word dataset for pre-training. Experimental results also demonstrate that the CUTIE being able to achieve state of the art performance with much smaller amount of training data.