 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking 3D Shape Generation: Diffusion over Superquadrics
Jun 08, 2026Diffusion models have advanced 3D shape generation, yet most methods still denoise in high-cardinality spaces (e.g., voxel/SDF grids, meshes, or point clouds), which is computationally and memory intensive and makes it difficult to scale in terms of both higher resolution and stronger controllability. We rethink the diffusion representation and propose to move diffusion from dense geometry to compact geometric primitives, representing each shape as a small set of superquadrics. Instead of operating on thousands to millions of geometric representation values, we leverage 7KB superquadric parameters (pose, size, and shape), drastically reducing diffusion-state dimensionality and per-step compute/memory. Our diffusion-over-superquadrics improves scalability by supporting broader capabilities (e.g., resolution-free point-cloud decoding, part-level editing, and constraint-based design) and achieving competitive surface-fidelity and distributional performance on standard benchmarks after point-cloud decoding, while enabling efficient generation within 0.6s per shape for most conditions.
EVPO: Explained Variance Policy Optimization for Adaptive Critic Utilization in LLM Post-Training
Apr 21, 2026Reinforcement learning (RL) for LLM post-training faces a fundamental design choice: whether to use a learned critic as a baseline for policy optimization. Classical theory favors critic-based methods such as PPO for variance reduction, yet critic-free alternatives like GRPO have gained widespread adoption due to their simplicity and competitive performance. We show that in sparse-reward settings, a learned critic can inject estimation noise that exceeds the state signal it captures, increasing rather than reducing advantage variance. By casting baseline selection as a Kalman filtering problem, we unify PPO and GRPO as two extremes of the Kalman gain and prove that explained variance (EV), computable from a single training batch, identifies the exact boundary: positive EV indicates the critic reduces variance, while zero or negative EV signals that it inflates variance. Building on this insight, we propose Explained Variance Policy Optimization (EVPO), which monitors batch-level EV at each training step and adaptively switches between critic-based and batch-mean advantage estimation, provably achieving no greater variance than the better of the two at every step. Across four tasks spanning classical control, agentic interaction, and mathematical reasoning, EVPO consistently outperforms both PPO and GRPO regardless of which fixed baseline is stronger on a given task. Further analysis confirms that the adaptive gating tracks critic maturation over training and that the theoretically derived zero threshold is empirically optimal.
The Eleventh NTIRE 2026 Efficient Super-Resolution Challenge Report
Apr 03, 2026This paper reviews the NTIRE 2026 challenge on efficient single-image super-resolution with a focus on the proposed solutions and results. The aim of this challenge is to devise a network that reduces one or several aspects, such as runtime, parameters, and FLOPs, while maintaining PSNR of around 26.90 dB on the DIV2K_LSDIR_valid dataset, and 26.99 dB on the DIV2K_LSDIR_test dataset. The challenge had 95 registered participants, and 15 teams made valid submissions. They gauge the state-of-the-art results for efficient single-image super-resolution.
Generative Replica-Exchange: A Flow-based Framework for Accelerating Replica Exchange Simulations
Mar 18, 2026Replica exchange (REX) is one of the most widely used enhanced sampling methodologies, yet its efficiency is limited by the requirement for a large number of intermediate temperature replicas. Here we present Generative Replica Exchange (GREX), which integrates deep generative models into the REX framework to eliminate this temperature ladder. Drawing inspiration from reservoir replica exchange (res-REX), GREX utilizes trained normalizing flows to generate high-temperature configurations on demand and map them directly to the target distribution using the potential energy as a constraint, without requiring target-temperature training data. This approach reduces production simulations to a single replica at the target temperature while maintaining thermodynamic rigor through Metropolis exchange acceptance. We validate GREX on three benchmark systems of increasing complexity, highlighting its superior efficiency and practical applicability for molecular simulations.
Steering LLMs via Scalable Interactive Oversight
Feb 04, 2026As Large Language Models increasingly automate complex, long-horizon tasks such as \emph{vibe coding}, a supervision gap has emerged. While models excel at execution, users often struggle to guide them effectively due to insufficient domain expertise, the difficulty of articulating precise intent, and the inability to reliably validate complex outputs. It presents a critical challenge in scalable oversight: enabling humans to responsibly steer AI systems on tasks that surpass their own ability to specify or verify. To tackle this, we propose Scalable Interactive Oversight, a framework that decomposes complex intent into a recursive tree of manageable decisions to amplify human supervision. Rather than relying on open-ended prompting, our system elicits low-burden feedback at each node and recursively aggregates these signals into precise global guidance. Validated in web development task, our framework enables non-experts to produce expert-level Product Requirement Documents, achieving a 54\% improvement in alignment. Crucially, we demonstrate that this framework can be optimized via Reinforcement Learning using only online user feedback, offering a practical pathway for maintaining human control as AI scales.
ABC-Bench: Benchmarking Agentic Backend Coding in Real-World Development
Jan 16, 2026The evolution of Large Language Models (LLMs) into autonomous agents has expanded the scope of AI coding from localized code generation to complex, repository-level, and execution-driven problem solving. However, current benchmarks predominantly evaluate code logic in static contexts, neglecting the dynamic, full-process requirements of real-world engineering, particularly in backend development which demands rigorous environment configuration and service deployment. To address this gap, we introduce ABC-Bench, a benchmark explicitly designed to evaluate agentic backend coding within a realistic, executable workflow. Using a scalable automated pipeline, we curated 224 practical tasks spanning 8 languages and 19 frameworks from open-source repositories. Distinct from previous evaluations, ABC-Bench require the agents to manage the entire development lifecycle from repository exploration to instantiating containerized services and pass the external end-to-end API tests. Our extensive evaluation reveals that even state-of-the-art models struggle to deliver reliable performance on these holistic tasks, highlighting a substantial disparity between current model capabilities and the demands of practical backend engineering. Our code is available at https://github.com/OpenMOSS/ABC-Bench.
SimLLM: Fine-Tuning Code LLMs for SimPy-Based Queueing System Simulation
Jan 10, 2026The Python package SimPy is widely used for modeling queueing systems due to its flexibility, simplicity, and smooth integration with modern data analysis and optimization frameworks. Recent advances in large language models (LLMs) have shown strong ability in generating clear and executable code, making them powerful and suitable tools for writing SimPy queueing simulation code. However, directly employing closed-source models like GPT-4o to generate such code may lead to high computational costs and raise data privacy concerns. To address this, we fine-tune two open-source LLMs, Qwen-Coder-7B and DeepSeek-Coder-6.7B, on curated SimPy queueing data, which enhances their code-generating performance in executability, output-format compliance, and instruction-code consistency. Particularly, we proposed a multi-stage fine-tuning framework comprising two stages of supervised fine-tuning (SFT) and one stage of direct preference optimization (DPO), progressively enhancing the model's ability in SimPy-based queueing simulation code generation. Extensive evaluations demonstrate that both fine-tuned models achieve substantial improvements in executability, output-format compliance, and instruct consistency. These results confirm that domain-specific fine-tuning can effectively transform compact open-source code models into reliable SimPy simulation generators which provide a practical alternative to closed-source LLMs for education, research, and operational decision support.
AgentGym-RL: Training LLM Agents for Long-Horizon Decision Making through Multi-Turn Reinforcement Learning
Sep 10, 2025Developing autonomous LLM agents capable of making a series of intelligent decisions to solve complex, real-world tasks is a fast-evolving frontier. Like human cognitive development, agents are expected to acquire knowledge and skills through exploration and interaction with the environment. Despite advances, the community still lacks a unified, interactive reinforcement learning (RL) framework that can effectively train such agents from scratch -- without relying on supervised fine-tuning (SFT) -- across diverse and realistic environments. To bridge this gap, we introduce AgentGym-RL, a new framework to train LLM agents for multi-turn interactive decision-making through RL. The framework features a modular and decoupled architecture, ensuring high flexibility and extensibility. It encompasses a wide variety of real-world scenarios, and supports mainstream RL algorithms. Furthermore, we propose ScalingInter-RL, a training approach designed for exploration-exploitation balance and stable RL optimization. In early stages, it emphasizes exploitation by restricting the number of interactions, and gradually shifts towards exploration with larger horizons to encourage diverse problem-solving strategies. In this way, the agent develops more diverse behaviors and is less prone to collapse under long horizons. We perform extensive experiments to validate the stability and effectiveness of both the AgentGym-RL framework and the ScalingInter-RL approach. Our agents match or surpass commercial models on 27 tasks across diverse environments. We offer key insights and will open-source the complete AgentGym-RL framework -- including code and datasets -- to empower the research community in developing the next generation of intelligent agents.
Speech-Language Models with Decoupled Tokenizers and Multi-Token Prediction
Jun 14, 2025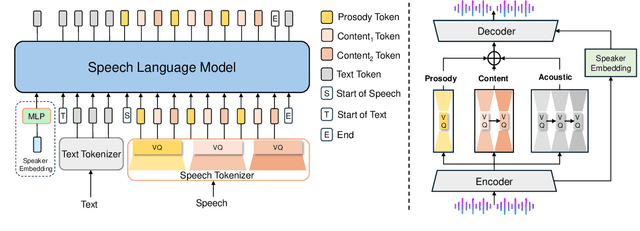
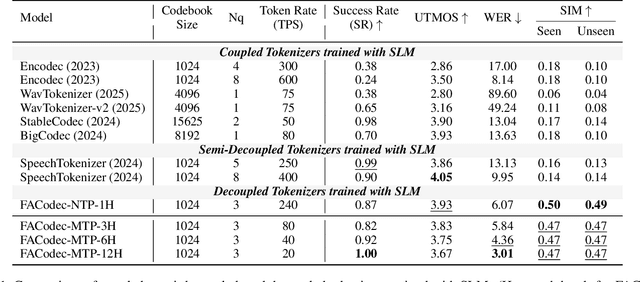
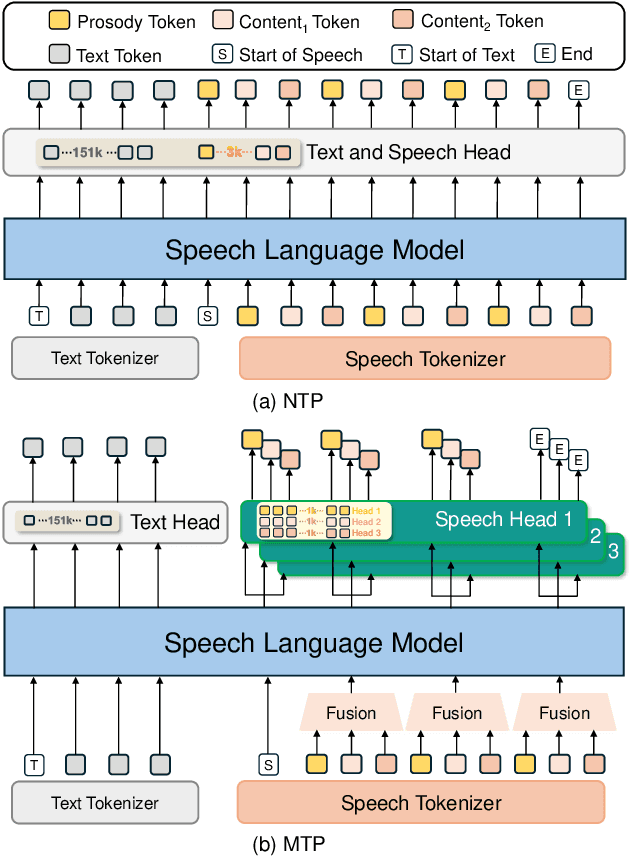
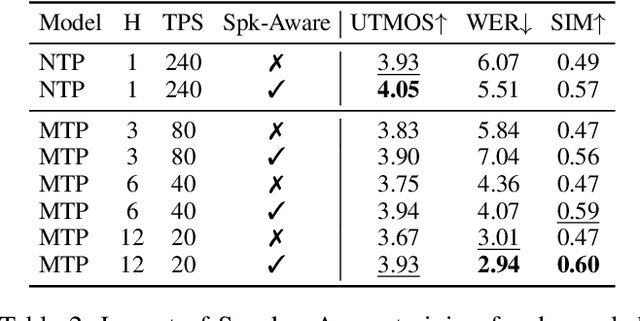
Speech-language models (SLMs) offer a promising path toward unifying speech and text understanding and generation. However, challenges remain in achieving effective cross-modal alignment and high-quality speech generation. In this work, we systematically investigate the impact of key components (i.e., speech tokenizers, speech heads, and speaker modeling) on the performance of LLM-centric SLMs. We compare coupled, semi-decoupled, and fully decoupled speech tokenizers under a fair SLM framework and find that decoupled tokenization significantly improves alignment and synthesis quality. To address the information density mismatch between speech and text, we introduce multi-token prediction (MTP) into SLMs, enabling each hidden state to decode multiple speech tokens. This leads to up to 12$\times$ faster decoding and a substantial drop in word error rate (from 6.07 to 3.01). Furthermore, we propose a speaker-aware generation paradigm and introduce RoleTriviaQA, a large-scale role-playing knowledge QA benchmark with diverse speaker identities. Experiments demonstrate that our methods enhance both knowledge understanding and speaker consistency.
Improving RL Exploration for LLM Reasoning through Retrospective Replay
Apr 19, 2025Reinforcement learning (RL) has increasingly become a pivotal technique in the post-training of large language models (LLMs). The effective exploration of the output space is essential for the success of RL. We observe that for complex problems, during the early stages of training, the model exhibits strong exploratory capabilities and can identify promising solution ideas. However, its limited capability at this stage prevents it from successfully solving these problems. The early suppression of these potentially valuable solution ideas by the policy gradient hinders the model's ability to revisit and re-explore these ideas later. Consequently, although the LLM's capabilities improve in the later stages of training, it still struggles to effectively address these complex problems. To address this exploration issue, we propose a novel algorithm named Retrospective Replay-based Reinforcement Learning (RRL), which introduces a dynamic replay mechanism throughout the training process. RRL enables the model to revisit promising states identified in the early stages, thereby improving its efficiency and effectiveness in exploration. To evaluate the effectiveness of RRL, we conduct extensive experiments on complex reasoning tasks, including mathematical reasoning and code generation, and general dialogue tasks. The results indicate that RRL maintains high exploration efficiency throughout the training period, significantly enhancing the effectiveness of RL in optimizing LLMs for complicated reasoning tasks. Moreover, it also improves the performance of RLHF, making the model both safer and more helpful.