 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakMedSAM: Weakly-Supervised Medical Image Segmentation via SAM with Sub-Class Exploration and Prompt Affinity Mining
Mar 06, 2025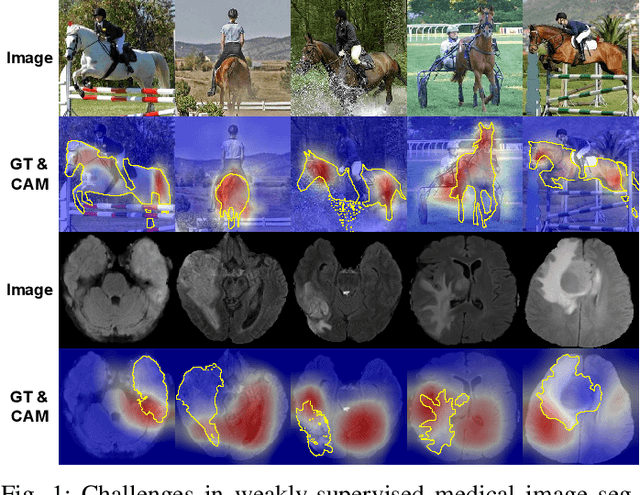
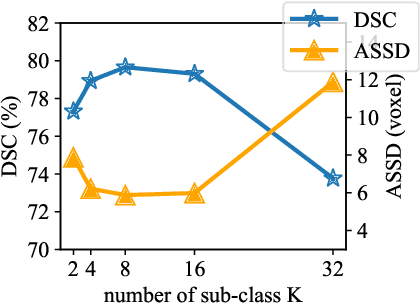
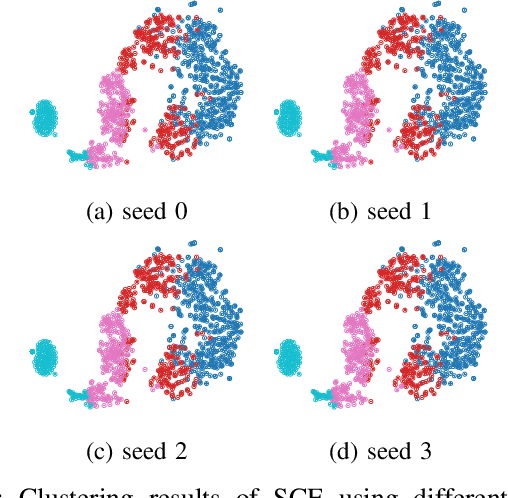
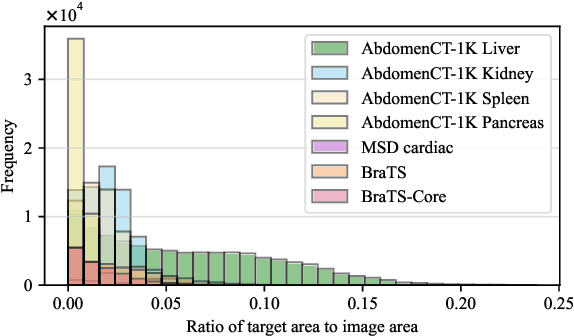
We have witnessed remarkable progress in foundation models in vision tasks. Currently, several recent works have utilized the segmenting anything model (SAM) to boost the segmentation performance in medical images, where most of them focus on training an adaptor for fine-tuning a large amount of pixel-wise annotated medical images following a fully supervised manner. In this paper, to reduce the labeling cost, we investigate a novel weakly-supervised SAM-based segmentation model, namely WeakMedSAM. Specifically, our proposed WeakMedSAM contains two modules: 1) to mitigate severe co-occurrence in medical images, a sub-class exploration module is introduced to learn accurate feature representations. 2) to improve the quality of the class activation maps, our prompt affinity mining module utilizes the prompt capability of SAM to obtain an affinity map for random-walk refinement. Our method can be applied to any SAM-like backbone, and we conduct experiments with SAMUS and EfficientSAM. The experimental results on three popularly-used benchmark datasets, i.e., BraTS 2019, AbdomenCT-1K, and MSD Cardiac dataset, show the promising results of our proposed WeakMedSAM. Our code is available at https://github.com/wanghr64/WeakMedSAM.
CDI: Blind Image Restoration Fidelity Evaluation based on Consistency with Degraded Image
Jan 24, 2025Recent advancements in Blind Image Restoration (BIR) methods, based on Generative Adversarial Networks and Diffusion Models, have significantly improved visual quality. However, they present significant challenges for Image Quality Assessment (IQA), as the existing Full-Reference IQA methods often rate images with high perceptual quality poorly. In this paper, we reassess the Solution Non-Uniqueness and Degradation Indeterminacy issues of BIR, and propose constructing a specific BIR IQA system. In stead of directly comparing a restored image with a reference image, the BIR IQA evaluates fidelity by calculating the Consistency with Degraded Image (CDI). Specifically, we propose a wavelet domain Reference Guided CDI algorithm, which can acquire the consistency with a degraded image for various types without requiring knowledge of degradation parameters. The supported degradation types include down sampling, blur, noise, JPEG and complex combined degradations etc. In addition, we propose a Reference Agnostic CDI, enabling BIR fidelity evaluation without reference images. Finally, in order to validate the rationality of CDI, we create a new Degraded Images Switch Display Comparison Dataset (DISDCD) for subjective evaluation of BIR fidelity. Experiments conducted on DISDCD verify that CDI is markedly superior to common Full Reference IQA methods for BIR fidelity evaluation. The source code and the DISDCD dataset will be publicly available shortly.
Cross-Domain Few-Shot Object Detection via Enhanced Open-Set Object Detector
Feb 05, 2024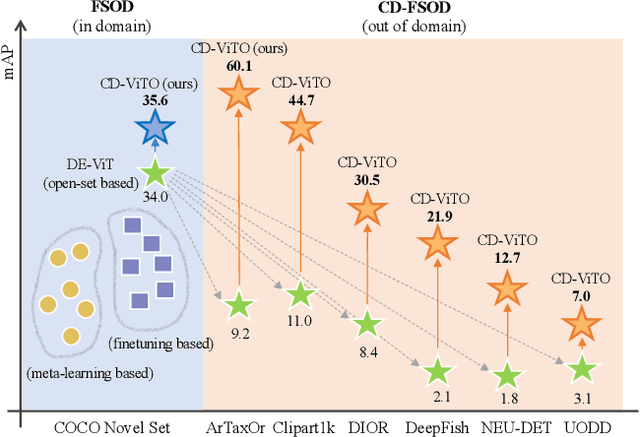

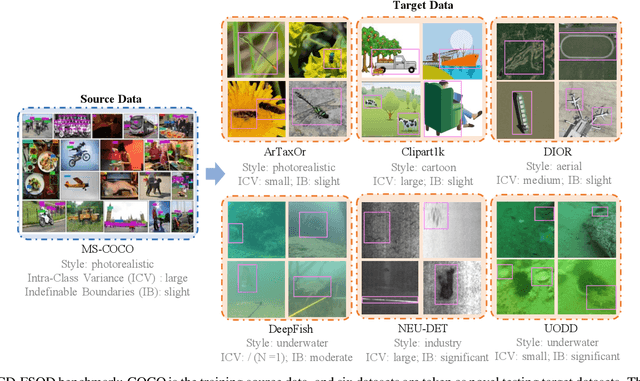

This paper addresses the challenge of cross-domain few-shot object detection (CD-FSOD), aiming to develop an accurate object detector for novel domains with minimal labeled examples. While transformer-based open-set detectors e.g., DE-ViT~\cite{zhang2023detect} have excelled in both open-vocabulary object detection and traditional few-shot object detection, detecting categories beyond those seen during training, we thus naturally raise two key questions: 1) can such open-set detection methods easily generalize to CD-FSOD? 2) If no, how to enhance the results of open-set methods when faced with significant domain gaps? To address the first question, we introduce several metrics to quantify domain variances and establish a new CD-FSOD benchmark with diverse domain metric values. Some State-Of-The-Art (SOTA) open-set object detection methods are evaluated on this benchmark, with evident performance degradation observed across out-of-domain datasets. This indicates the failure of adopting open-set detectors directly for CD-FSOD. Sequentially, to overcome the performance degradation issue and also to answer the second proposed question, we endeavor to enhance the vanilla DE-ViT. With several novel components including finetuning, a learnable prototype module, and a lightweight attention module, we present an improved Cross-Domain Vision Transformer for CD-FSOD (CD-ViTO). Experiments show that our CD-ViTO achieves impressive results on both out-of-domain and in-domain target datasets, establishing new SOTAs for both CD-FSOD and FSOD. All the datasets, codes, and models will be released to the community.
Decoupled DETR For Few-shot Object Detection
Nov 20, 2023Few-shot object detection (FSOD), an efficient method for addressing the severe data-hungry problem, has been extensively discussed. Current works have significantly advanced the problem in terms of model and data. However, the overall performance of most FSOD methods still does not fulfill the desired accuracy. In this paper we improve the FSOD model to address the severe issue of sample imbalance and weak feature propagation. To alleviate modeling bias from data-sufficient base classes, we examine the effect of decoupling the parameters for classes with sufficient data and classes with few samples in various ways. We design a base-novel categories decoupled DETR (DeDETR) for FSOD. We also explore various types of skip connection between the encoder and decoder for DETR. Besides, we notice that the best outputs could come from the intermediate layer of the decoder instead of the last layer; therefore, we build a unified decoder module that could dynamically fuse the decoder layers as the output feature. We evaluate our model on commonly used datasets such as PASCAL VOC and MSCOCO. Our results indicate that our proposed module could achieve stable improvements of 5% to 10% in both fine-tuning and meta-learning paradigms and has outperformed the highest score in recent works.
Few-shot Object Detection with Refined Contrastive Learning
Nov 24, 2022Due to the scarcity of sampling data in reality, few-shot object detection (FSOD) has drawn more and more attention because of its ability to quickly train new detection concepts with less data. However, there are still failure identifications due to the difficulty in distinguishing confusable classes. We also notice that the high standard deviation of average precisions reveals the inconsistent detection performance. To this end, we propose a novel FSOD method with Refined Contrastive Learning (FSRC). A pre-determination component is introduced to find out the Resemblance Group (GR) from novel classes which contains confusable classes. Afterwards, refined contrastive learning (RCL) is pointedly performed on this group of classes in order to increase the inter-class distances among them. In the meantime, the detection results distribute more uniformly which further improve the performance. Experimental results based on PASCAL VOC and COCO datasets demonstrate our proposed method outperforms the current state-of-the-art research. FSRC can not only decouple the relevance of confusable classes to get a better performance, but also makes predictions more consistent by reducing the standard deviation of the AP of classes to be detected.
edge-SR: Super-Resolution For The Masses
Aug 23, 2021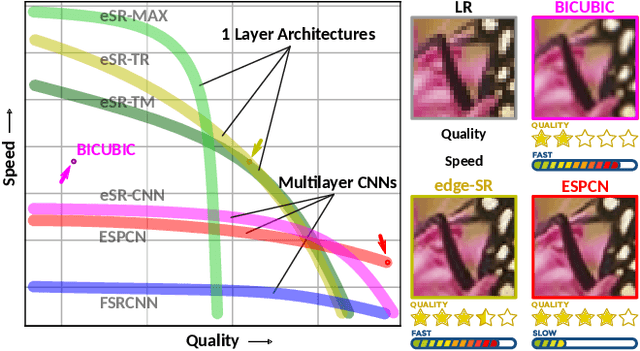

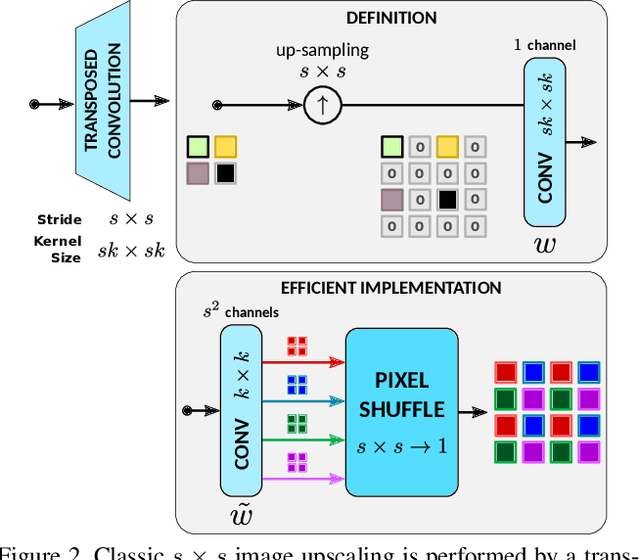
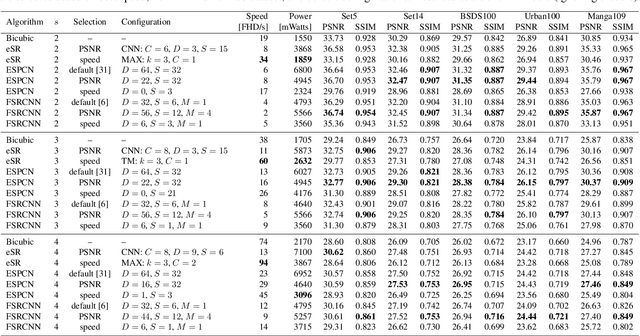
Classic image scaling (e.g. bicubic) can be seen as one convolutional layer and a single upscaling filter. Its implementation is ubiquitous in all display devices and image processing software. In the last decade deep learning systems have been introduced for the task of image super-resolution (SR), using several convolutional layers and numerous filters. These methods have taken over the benchmarks of image quality for upscaling tasks. Would it be possible to replace classic upscalers with deep learning architectures on edge devices such as display panels, tablets, laptop computers, etc.? On one hand, the current trend in Edge-AI chips shows a promising future in this direction, with rapid development of hardware that can run deep-learning tasks efficiently. On the other hand, in image SR only few architectures have pushed the limit to extreme small sizes that can actually run on edge devices at real-time. We explore possible solutions to this problem with the aim to fill the gap between classic upscalers and small deep learning configurations. As a transition from classic to deep-learning upscaling we propose edge-SR (eSR), a set of one-layer architectures that use interpretable mechanisms to upscale images. Certainly, a one-layer architecture cannot reach the quality of deep learning systems. Nevertheless, we find that for high speed requirements, eSR becomes better at trading-off image quality and runtime performance. Filling the gap between classic and deep-learning architectures for image upscaling is critical for massive adoption of this technology. It is equally important to have an interpretable system that can reveal the inner strategies to solve this problem and guide us to future improvements and better understanding of larger networks.
Back-Projection Pipeline
Jan 25, 2021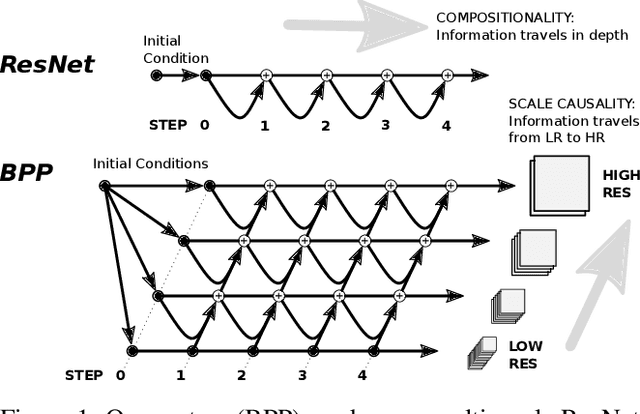
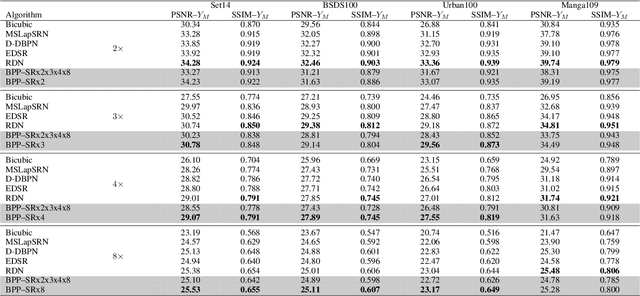
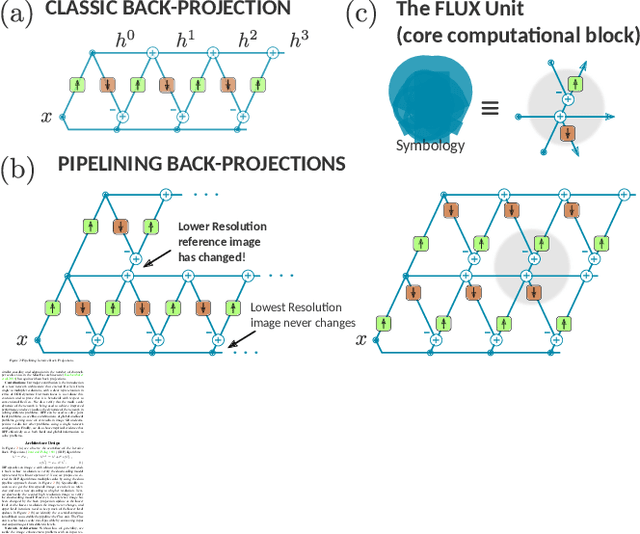
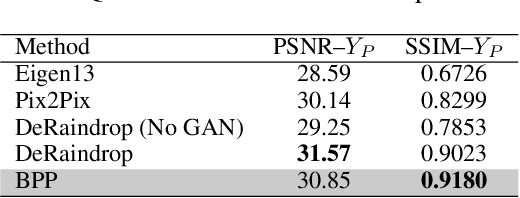
We propose a simple extension of residual networks that works simultaneously in multiple resolutions. Our network design is inspired by the iterative back-projection algorithm but seeks the more difficult task of learning how to enhance images. Compared to similar approaches, we propose a novel solution to make back-projections run in multiple resolutions by using a data pipeline workflow. Features are updated at multiple scales in each layer of the network. The update dynamic through these layers includes interactions between different resolutions in a way that is causal in scale, and it is represented by a system of ODEs, as opposed to a single ODE in the case of ResNets. The system can be used as a generic multi-resolution approach to enhance images. We test it on several challenging tasks with special focus on super-resolution and raindrop removal. Our results are competitive with state-of-the-arts and show a strong ability of our system to learn both global and local image features.
Multi-Grid Back-Projection Networks
Jan 01, 2021

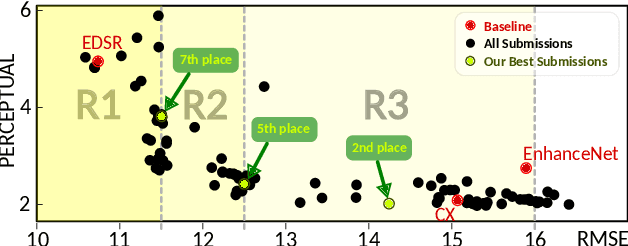

Multi-Grid Back-Projection (MGBP) is a fully-convolutional network architecture that can learn to restore images and videos with upscaling artifacts. Using the same strategy of multi-grid partial differential equation (PDE) solvers this multiscale architecture scales computational complexity efficiently with increasing output resolutions. The basic processing block is inspired in the iterative back-projection (IBP) algorithm and constitutes a type of cross-scale residual block with feedback from low resolution references. The architecture performs in par with state-of-the-arts alternatives for regression targets that aim to recover an exact copy of a high resolution image or video from which only a downscale image is known. A perceptual quality target aims to create more realistic outputs by introducing artificial changes that can be different from a high resolution original content as long as they are consistent with the low resolution input. For this target we propose a strategy using noise inputs in different resolution scales to control the amount of artificial details generated in the output. The noise input controls the amount of innovation that the network uses to create artificial realistic details. The effectiveness of this strategy is shown in benchmarks and it is explained as a particular strategy to traverse the perception-distortion plane.
A Tour of Convolutional Networks Guided by Linear Interpreters
Aug 14, 2019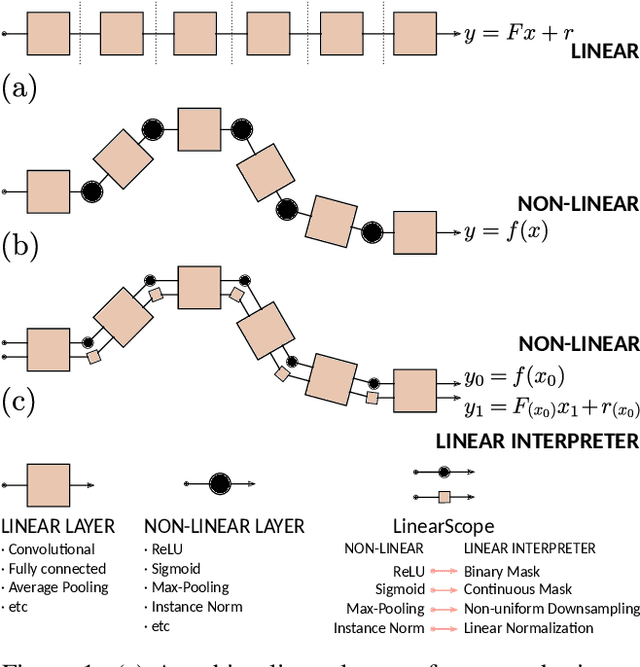

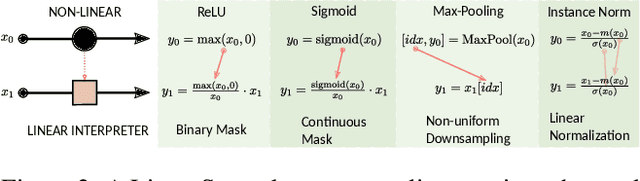

Convolutional networks are large linear systems divided into layers and connected by non-linear units. These units are the "articulations" that allow the network to adapt to the input. To understand how a network manages to solve a problem we must look at the articulated decisions in entirety. If we could capture the actions of non-linear units for a particular input, we would be able to replay the whole system back and forth as if it was always linear. It would also reveal the actions of non-linearities because the resulting linear system, a Linear Interpreter, depends on the input image. We introduce a hooking layer, called a LinearScope, which allows us to run the network and the linear interpreter in parallel. Its implementation is simple, flexible and efficient. From here we can make many curious inquiries: how do these linear systems look like? When the rows and columns of the transformation matrix are images, how do they look like? What type of basis do these linear transformations rely on? The answers depend on the problems presented, through which we take a tour to some popular architectures used for classification, super-resolution (SR) and image-to-image translation (I2I). For classification we observe that popular networks use a pixel-wise vote per class strategy and heavily rely on bias parameters. For SR and I2I we find that CNNs use wavelet-type basis similar to the human visual system. For I2I we reveal copy-move and template-creation strategies to generate outputs.