 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscordance Minimization-based Imputation Algorithms for Missing Values in Rating Data
Nov 07, 2023Ratings are frequently used to evaluate and compare subjects in various applications, from education to healthcare, because ratings provide succinct yet credible measures for comparing subjects. However, when multiple rating lists are combined or considered together, subjects often have missing ratings, because most rating lists do not rate every subject in the combined list. In this study, we propose analyses on missing value patterns using six real-world data sets in various applications, as well as the conditions for applicability of imputation algorithms. Based on the special structures and properties derived from the analyses, we propose optimization models and algorithms that minimize the total rating discordance across rating providers to impute missing ratings in the combined rating lists, using only the known rating information. The total rating discordance is defined as the sum of the pairwise discordance metric, which can be written as a quadratic function. Computational experiments based on real-world and synthetic rating data sets show that the proposed methods outperform the state-of-the-art general imputation methods in the literature in terms of imputation accuracy.
Valid Information Guidance Network for Compressed Video Quality Enhancement
Feb 28, 2023

In recent years deep learning methods have shown great superiority in compressed video quality enhancement tasks. Existing methods generally take the raw video as the ground truth and extract practical information from consecutive frames containing various artifacts. However, they do not fully exploit the valid information of compressed and raw videos to guide the quality enhancement for compressed videos. In this paper, we propose a unique Valid Information Guidance scheme (VIG) to enhance the quality of compressed videos by mining valid information from both compressed videos and raw videos. Specifically, we propose an efficient framework, Compressed Redundancy Filtering (CRF) network, to balance speed and enhancement. After removing the redundancy by filtering the information, CRF can use the valid information of the compressed video to reconstruct the texture. Furthermore, we propose a progressive Truth Guidance Distillation (TGD) strategy, which does not need to design additional teacher models and distillation loss functions. By only using the ground truth as input to guide the model to aggregate the correct spatio-temporal correspondence across the raw frames, TGD can significantly improve the enhancement effect without increasing the extra training cost. Extensive experiments show that our method achieves the state-of-the-art performance of compressed video quality enhancement in terms of accuracy and efficiency.
Efficient and Accurate Quantized Image Super-Resolution on Mobile NPUs, Mobile AI & AIM 2022 challenge: Report
Nov 07, 2022
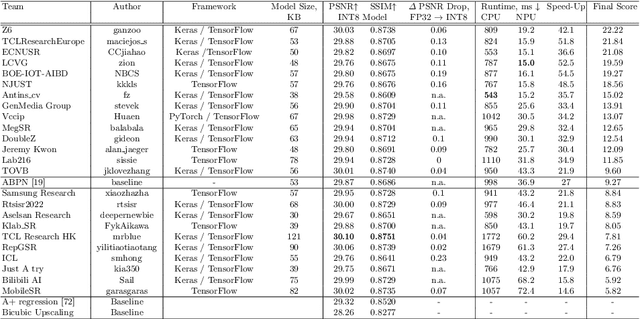
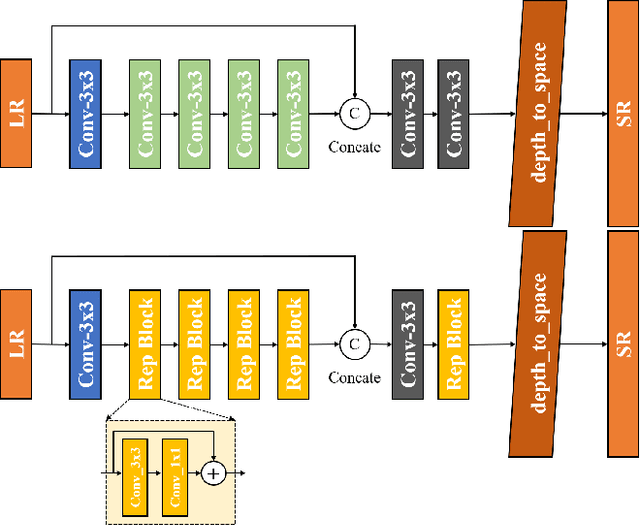
Image super-resolution is a common task on mobile and IoT devices, where one often needs to upscale and enhance low-resolution images and video frames. While numerous solutions have been proposed for this problem in the past, they are usually not compatible with low-power mobile NPUs having many computational and memory constraints. In this Mobile AI challenge, we address this problem and propose the participants to design an efficient quantized image super-resolution solution that can demonstrate a real-time performance on mobile NPUs. The participants were provided with the DIV2K dataset and trained INT8 models to do a high-quality 3X image upscaling. The runtime of all models was evaluated on the Synaptics VS680 Smart Home board with a dedicated edge NPU capable of accelerating quantized neural networks. All proposed solutions are fully compatible with the above NPU, demonstrating an up to 60 FPS rate when reconstructing Full HD resolution images. A detailed description of all models developed in the challenge is provided in this paper.
Power Efficient Video Super-Resolution on Mobile NPUs with Deep Learning, Mobile AI & AIM 2022 challenge: Report
Nov 07, 2022



Video super-resolution is one of the most popular tasks on mobile devices, being widely used for an automatic improvement of low-bitrate and low-resolution video streams. While numerous solutions have been proposed for this problem, they are usually quite computationally demanding, demonstrating low FPS rates and power efficiency on mobile devices. In this Mobile AI challenge, we address this problem and propose the participants to design an end-to-end real-time video super-resolution solution for mobile NPUs optimized for low energy consumption. The participants were provided with the REDS training dataset containing video sequences for a 4X video upscaling task. The runtime and power efficiency of all models was evaluated on the powerful MediaTek Dimensity 9000 platform with a dedicated AI processing unit capable of accelerating floating-point and quantized neural networks. All proposed solutions are fully compatible with the above NPU, demonstrating an up to 500 FPS rate and 0.2 [Watt / 30 FPS] power consumption. A detailed description of all models developed in the challenge is provided in this paper.
NTIRE 2022 Challenge on High Dynamic Range Imaging: Methods and Results
May 25, 2022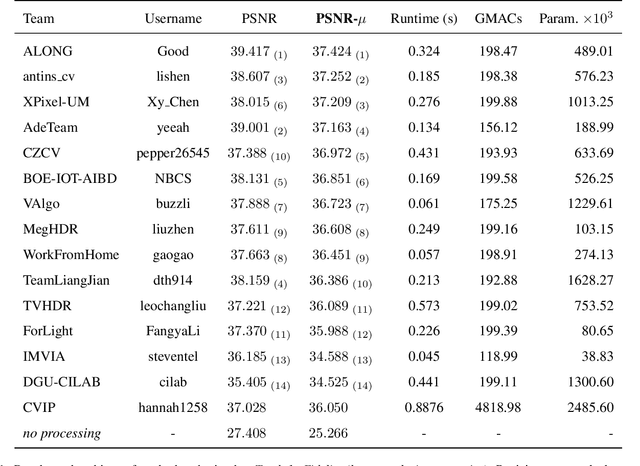
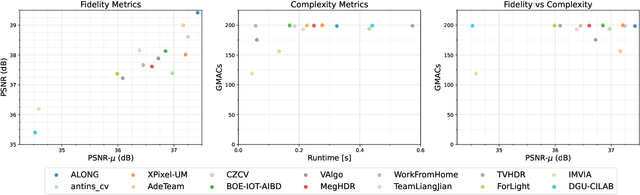
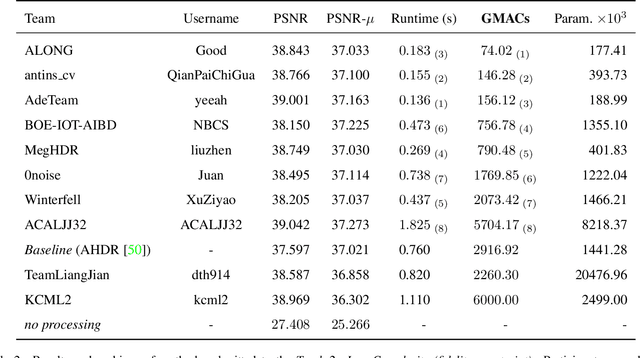
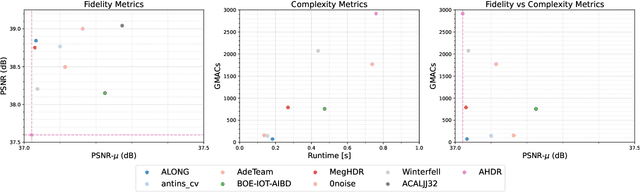
This paper reviews the challenge on constrained high dynamic range (HDR) imaging that was part of the New Trends in Image Restoration and Enhancement (NTIRE) workshop, held in conjunction with CVPR 2022. This manuscript focuses on the competition set-up, datasets, the proposed methods and their results. The challenge aims at estimating an HDR image from multiple respective low dynamic range (LDR) observations, which might suffer from under- or over-exposed regions and different sources of noise. The challenge is composed of two tracks with an emphasis on fidelity and complexity constraints: In Track 1, participants are asked to optimize objective fidelity scores while imposing a low-complexity constraint (i.e. solutions can not exceed a given number of operations). In Track 2, participants are asked to minimize the complexity of their solutions while imposing a constraint on fidelity scores (i.e. solutions are required to obtain a higher fidelity score than the prescribed baseline). Both tracks use the same data and metrics: Fidelity is measured by means of PSNR with respect to a ground-truth HDR image (computed both directly and with a canonical tonemapping operation), while complexity metrics include the number of Multiply-Accumulate (MAC) operations and runtime (in seconds).
* CVPR Workshops 2022. 15 pages, 21 figures, 2 tables
Multi-Grid Back-Projection Networks
Jan 01, 2021


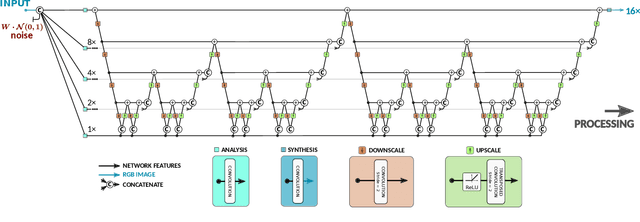
Multi-Grid Back-Projection (MGBP) is a fully-convolutional network architecture that can learn to restore images and videos with upscaling artifacts. Using the same strategy of multi-grid partial differential equation (PDE) solvers this multiscale architecture scales computational complexity efficiently with increasing output resolutions. The basic processing block is inspired in the iterative back-projection (IBP) algorithm and constitutes a type of cross-scale residual block with feedback from low resolution references. The architecture performs in par with state-of-the-arts alternatives for regression targets that aim to recover an exact copy of a high resolution image or video from which only a downscale image is known. A perceptual quality target aims to create more realistic outputs by introducing artificial changes that can be different from a high resolution original content as long as they are consistent with the low resolution input. For this target we propose a strategy using noise inputs in different resolution scales to control the amount of artificial details generated in the output. The noise input controls the amount of innovation that the network uses to create artificial realistic details. The effectiveness of this strategy is shown in benchmarks and it is explained as a particular strategy to traverse the perception-distortion plane.
MGBPv2: Scaling Up Multi-Grid Back-Projection Networks
Sep 27, 2019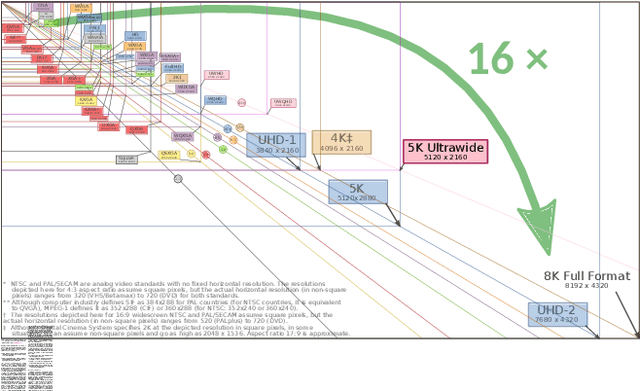
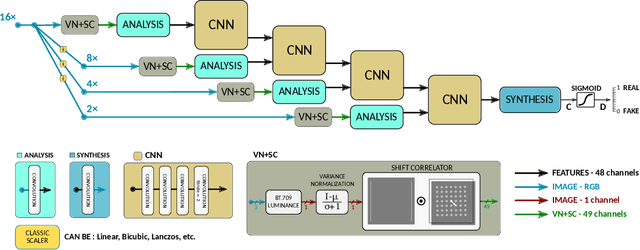

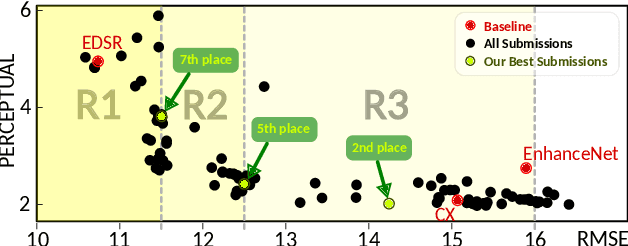
Here, we describe our solution for the AIM-2019 Extreme Super-Resolution Challenge, where we won the 1st place in terms of perceptual quality (MOS) similar to the ground truth and achieved the 5th place in terms of high-fidelity (PSNR). To tackle this challenge, we introduce the second generation of MultiGrid BackProjection networks (MGBPv2) whose major modifications make the system scalable and more general than its predecessor. It combines the scalability of the multigrid algorithm and the performance of iterative backprojections. In its original form, MGBP is limited to a small number of parameters due to a strongly recursive structure. In MGBPv2, we make full use of the multigrid recursion from the beginning of the network; we allow different parameters in every module of the network; we simplify the main modules; and finally, we allow adjustments of the number of network features based on the scale of operation. For inference tasks, we introduce an overlapping patch approach to further allow processing of very large images (e.g. 8K). Our training strategies make use of a multiscale loss, combining distortion and/or perception losses on the output as well as downscaled output images. The final system can balance between high quality and high performance.