 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePower Efficient Video Super-Resolution on Mobile NPUs with Deep Learning, Mobile AI & AIM 2022 challenge: Report
Nov 07, 2022



Video super-resolution is one of the most popular tasks on mobile devices, being widely used for an automatic improvement of low-bitrate and low-resolution video streams. While numerous solutions have been proposed for this problem, they are usually quite computationally demanding, demonstrating low FPS rates and power efficiency on mobile devices. In this Mobile AI challenge, we address this problem and propose the participants to design an end-to-end real-time video super-resolution solution for mobile NPUs optimized for low energy consumption. The participants were provided with the REDS training dataset containing video sequences for a 4X video upscaling task. The runtime and power efficiency of all models was evaluated on the powerful MediaTek Dimensity 9000 platform with a dedicated AI processing unit capable of accelerating floating-point and quantized neural networks. All proposed solutions are fully compatible with the above NPU, demonstrating an up to 500 FPS rate and 0.2 [Watt / 30 FPS] power consumption. A detailed description of all models developed in the challenge is provided in this paper.
Hard Samples Rectification for Unsupervised Cross-domain Person Re-identification
Jun 14, 2021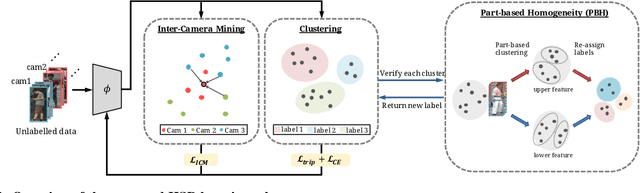
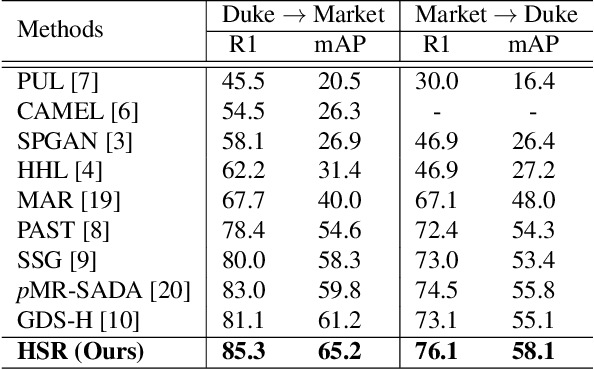
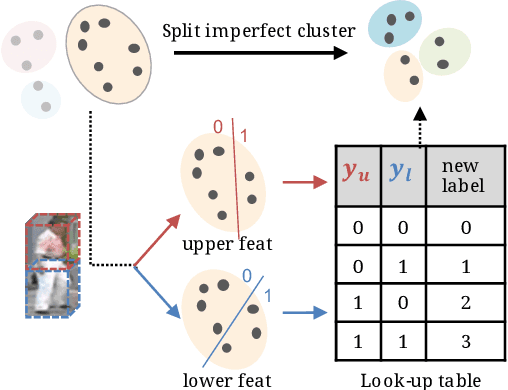
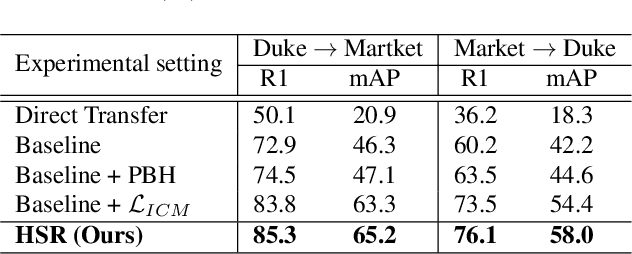
Person re-identification (re-ID) has received great success with the supervised learning methods. However, the task of unsupervised cross-domain re-ID is still challenging. In this paper, we propose a Hard Samples Rectification (HSR) learning scheme which resolves the weakness of original clustering-based methods being vulnerable to the hard positive and negative samples in the target unlabelled dataset. Our HSR contains two parts, an inter-camera mining method that helps recognize a person under different views (hard positive) and a part-based homogeneity technique that makes the model discriminate different persons but with similar appearance (hard negative). By rectifying those two hard cases, the re-ID model can learn effectively and achieve promising results on two large-scale benchmarks.
Learned Smartphone ISP on Mobile NPUs with Deep Learning, Mobile AI 2021 Challenge: Report
May 17, 2021
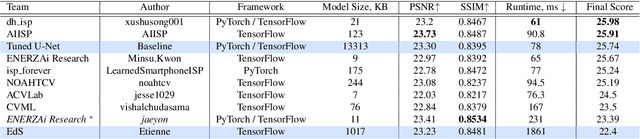
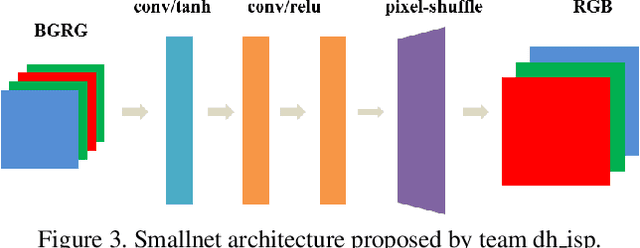
As the quality of mobile cameras starts to play a crucial role in modern smartphones, more and more attention is now being paid to ISP algorithms used to improve various perceptual aspects of mobile photos. In this Mobile AI challenge, the target was to develop an end-to-end deep learning-based image signal processing (ISP) pipeline that can replace classical hand-crafted ISPs and achieve nearly real-time performance on smartphone NPUs. For this, the participants were provided with a novel learned ISP dataset consisting of RAW-RGB image pairs captured with the Sony IMX586 Quad Bayer mobile sensor and a professional 102-megapixel medium format camera. The runtime of all models was evaluated on the MediaTek Dimensity 1000+ platform with a dedicated AI processing unit capable of accelerating both floating-point and quantized neural networks. The proposed solutions are fully compatible with the above NPU and are capable of processing Full HD photos under 60-100 milliseconds while achieving high fidelity results. A detailed description of all models developed in this challenge is provided in this paper.
Viewpoint-Aware Channel-Wise Attentive Network for Vehicle Re-Identification
Oct 12, 2020
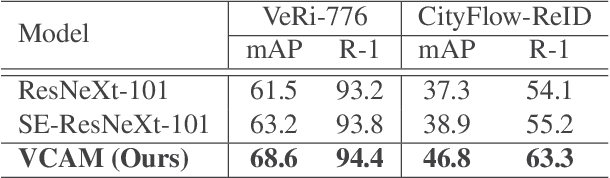
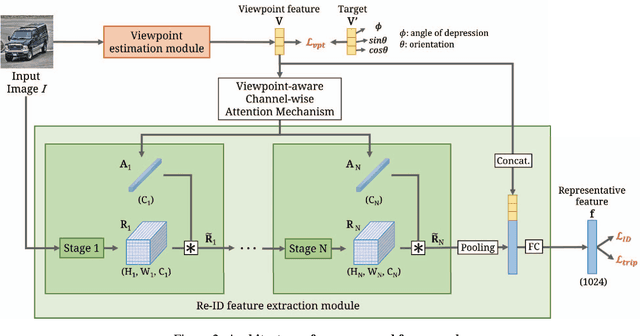
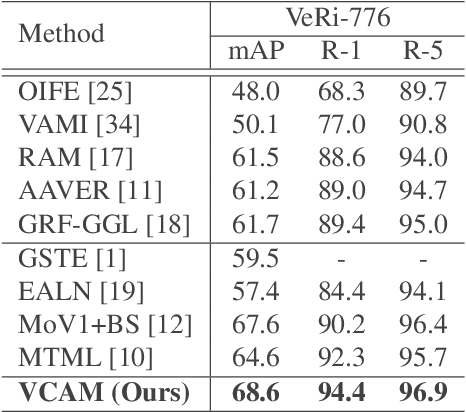
Vehicle re-identification (re-ID) matches images of the same vehicle across different cameras. It is fundamentally challenging because the dramatically different appearance caused by different viewpoints would make the framework fail to match two vehicles of the same identity. Most existing works solved the problem by extracting viewpoint-aware feature via spatial attention mechanism, which, yet, usually suffers from noisy generated attention map or otherwise requires expensive keypoint labels to improve the quality. In this work, we propose Viewpoint-aware Channel-wise Attention Mechanism (VCAM) by observing the attention mechanism from a different aspect. Our VCAM enables the feature learning framework channel-wisely reweighing the importance of each feature maps according to the "viewpoint" of input vehicle. Extensive experiments validate the effectiveness of the proposed method and show that we perform favorably against state-of-the-arts methods on the public VeRi-776 dataset and obtain promising results on the 2020 AI City Challenge. We also conduct other experiments to demonstrate the interpretability of how our VCAM practically assists the learning framework.