 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePomo3D: 3D-Aware Portrait Accessorizing and More
Sep 22, 2024We propose Pomo3D, a 3D portrait manipulation framework that allows free accessorizing by decomposing and recomposing portraits and accessories. It enables the avatars to attain out-of-distribution (OOD) appearances of simultaneously wearing multiple accessories. Existing methods still struggle to offer such explicit and fine-grained editing; they either fail to generate additional objects on given portraits or cause alterations to portraits (e.g., identity shift) when generating accessories. This restriction presents a noteworthy obstacle as people typically seek to create charming appearances with diverse and fashionable accessories in the virtual universe. Our approach provides an effective solution to this less-addressed issue. We further introduce the Scribble2Accessories module, enabling Pomo3D to create 3D accessories from user-drawn accessory scribble maps. Moreover, we design a bias-conscious mapper to mitigate biased associations present in real-world datasets. In addition to object-level manipulation above, Pomo3D also offers extensive editing options on portraits, including global or local editing of geometry and texture and avatar stylization, elevating 3D editing of neural portraits to a more comprehensive level.
FedFR: Joint Optimization Federated Framework for Generic and Personalized Face Recognition
Dec 23, 2021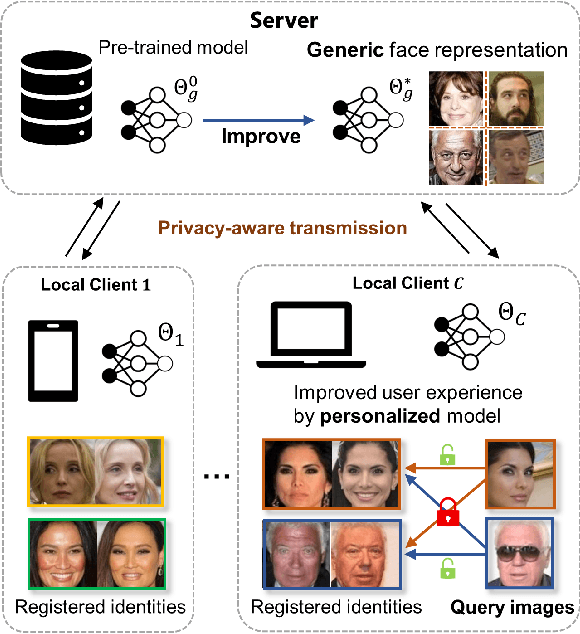
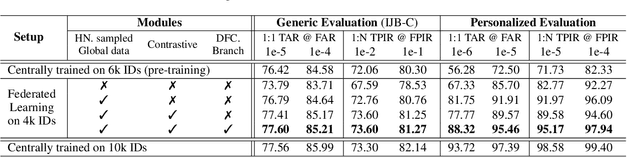
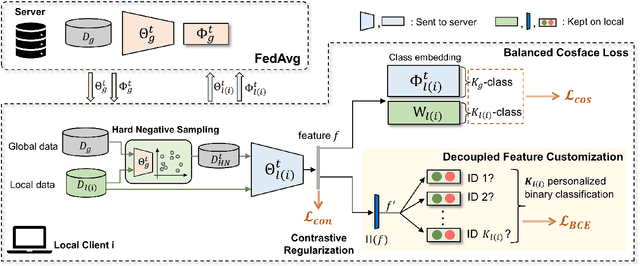
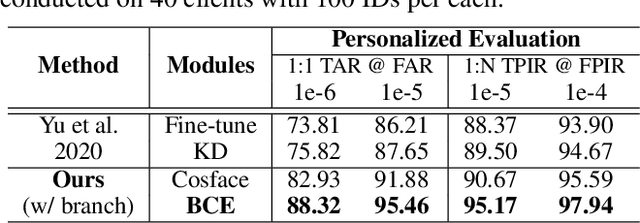
Current state-of-the-art deep learning based face recognition (FR) models require a large number of face identities for central training. However, due to the growing privacy awareness, it is prohibited to access the face images on user devices to continually improve face recognition models. Federated Learning (FL) is a technique to address the privacy issue, which can collaboratively optimize the model without sharing the data between clients. In this work, we propose a FL based framework called FedFR to improve the generic face representation in a privacy-aware manner. Besides, the framework jointly optimizes personalized models for the corresponding clients via the proposed Decoupled Feature Customization module. The client-specific personalized model can serve the need of optimized face recognition experience for registered identities at the local device. To the best of our knowledge, we are the first to explore the personalized face recognition in FL setup. The proposed framework is validated to be superior to previous approaches on several generic and personalized face recognition benchmarks with diverse FL scenarios. The source codes and our proposed personalized FR benchmark under FL setup are available at https://github.com/jackie840129/FedFR.
Interactive Object Segmentation with Dynamic Click Transform
Jun 19, 2021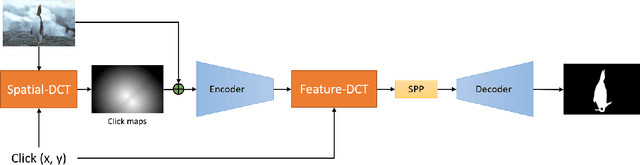


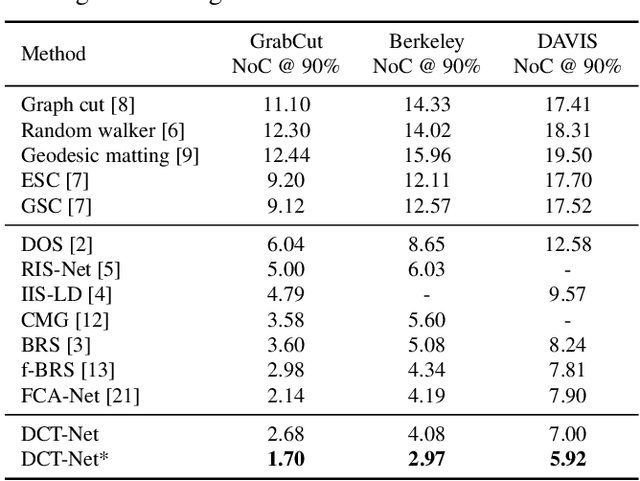
In the interactive segmentation, users initially click on the target object to segment the main body and then provide corrections on mislabeled regions to iteratively refine the segmentation masks. Most existing methods transform these user-provided clicks into interaction maps and concatenate them with image as the input tensor. Typically, the interaction maps are determined by measuring the distance of each pixel to the clicked points, ignoring the relation between clicks and mislabeled regions. We propose a Dynamic Click Transform Network~(DCT-Net), consisting of Spatial-DCT and Feature-DCT, to better represent user interactions. Spatial-DCT transforms each user-provided click with individual diffusion distance according to the target scale, and Feature-DCT normalizes the extracted feature map to a specific distribution predicted from the clicked points. We demonstrate the effectiveness of our proposed method and achieve favorable performance compared to the state-of-the-art on three standard benchmark datasets.
Hard Samples Rectification for Unsupervised Cross-domain Person Re-identification
Jun 14, 2021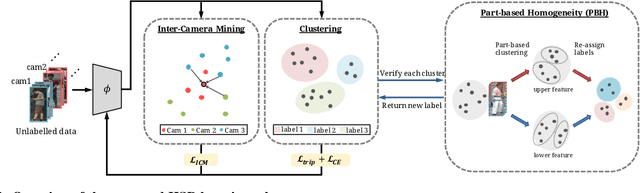
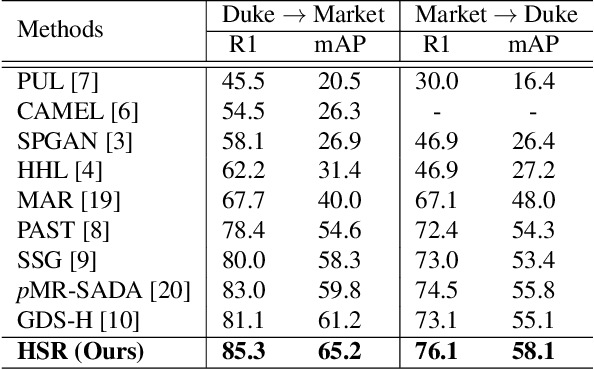
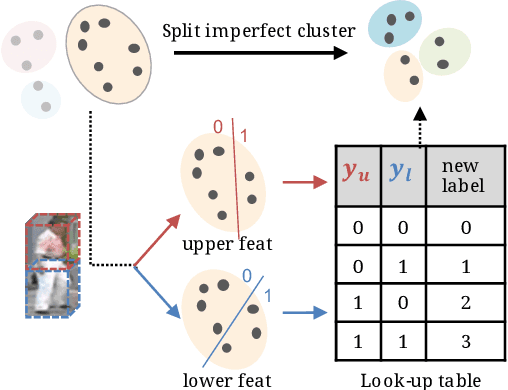
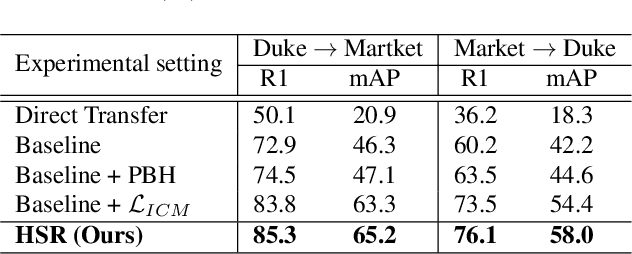
Person re-identification (re-ID) has received great success with the supervised learning methods. However, the task of unsupervised cross-domain re-ID is still challenging. In this paper, we propose a Hard Samples Rectification (HSR) learning scheme which resolves the weakness of original clustering-based methods being vulnerable to the hard positive and negative samples in the target unlabelled dataset. Our HSR contains two parts, an inter-camera mining method that helps recognize a person under different views (hard positive) and a part-based homogeneity technique that makes the model discriminate different persons but with similar appearance (hard negative). By rectifying those two hard cases, the re-ID model can learn effectively and achieve promising results on two large-scale benchmarks.
Video-based Person Re-identification without Bells and Whistles
May 22, 2021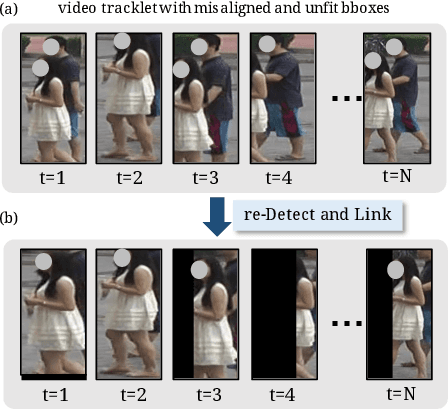
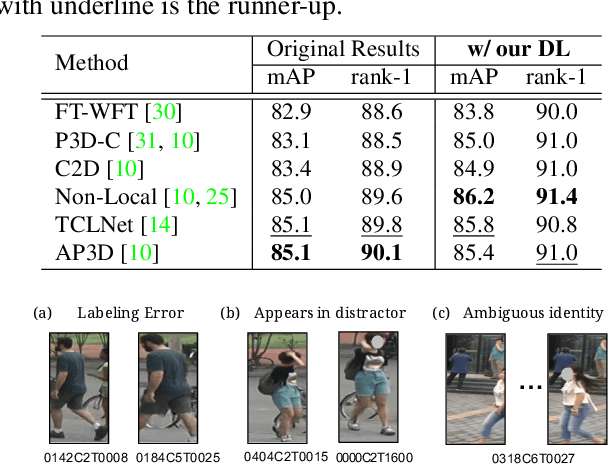
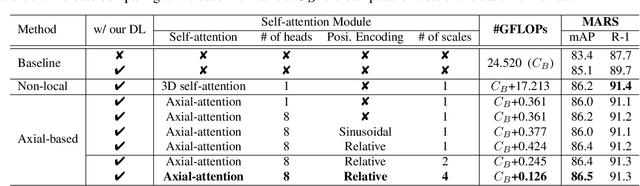
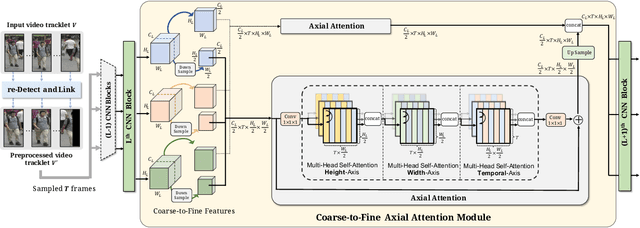
Video-based person re-identification (Re-ID) aims at matching the video tracklets with cropped video frames for identifying the pedestrians under different cameras. However, there exists severe spatial and temporal misalignment for those cropped tracklets due to the imperfect detection and tracking results generated with obsolete methods. To address this issue, we present a simple re-Detect and Link (DL) module which can effectively reduce those unexpected noise through applying the deep learning-based detection and tracking on the cropped tracklets. Furthermore, we introduce an improved model called Coarse-to-Fine Axial-Attention Network (CF-AAN). Based on the typical Non-local Network, we replace the non-local module with three 1-D position-sensitive axial attentions, in addition to our proposed coarse-to-fine structure. With the developed CF-AAN, compared to the original non-local operation, we can not only significantly reduce the computation cost but also obtain the state-of-the-art performance (91.3% in rank-1 and 86.5% in mAP) on the large-scale MARS dataset. Meanwhile, by simply adopting our DL module for data alignment, to our surprise, several baseline models can achieve better or comparable results with the current state-of-the-arts. Besides, we discover the errors not only for the identity labels of tracklets but also for the evaluation protocol for the test data of MARS. We hope that our work can help the community for the further development of invariant representation without the hassle of the spatial and temporal alignment and dataset noise. The code, corrected labels, evaluation protocol, and the aligned data will be available at https://github.com/jackie840129/CF-AAN.
Viewpoint-Aware Channel-Wise Attentive Network for Vehicle Re-Identification
Oct 12, 2020
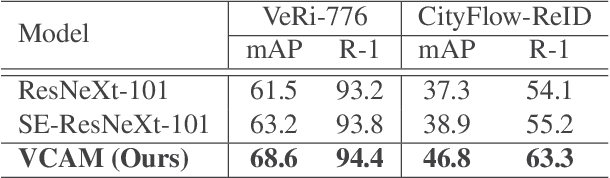
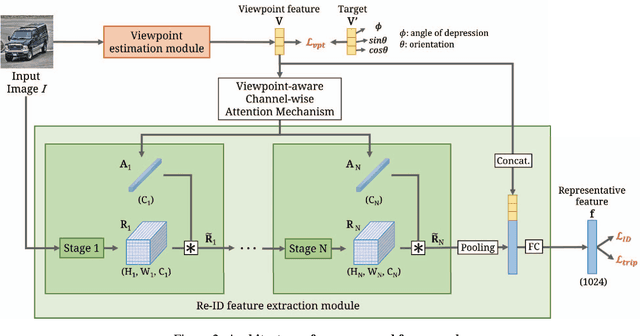
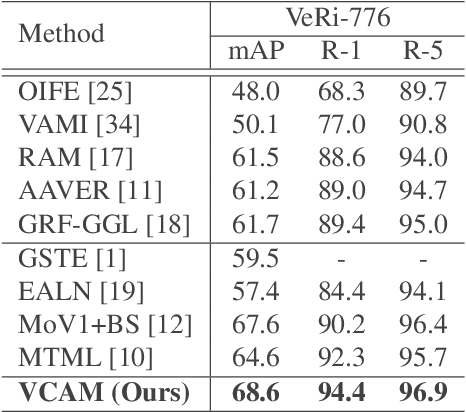
Vehicle re-identification (re-ID) matches images of the same vehicle across different cameras. It is fundamentally challenging because the dramatically different appearance caused by different viewpoints would make the framework fail to match two vehicles of the same identity. Most existing works solved the problem by extracting viewpoint-aware feature via spatial attention mechanism, which, yet, usually suffers from noisy generated attention map or otherwise requires expensive keypoint labels to improve the quality. In this work, we propose Viewpoint-aware Channel-wise Attention Mechanism (VCAM) by observing the attention mechanism from a different aspect. Our VCAM enables the feature learning framework channel-wisely reweighing the importance of each feature maps according to the "viewpoint" of input vehicle. Extensive experiments validate the effectiveness of the proposed method and show that we perform favorably against state-of-the-arts methods on the public VeRi-776 dataset and obtain promising results on the 2020 AI City Challenge. We also conduct other experiments to demonstrate the interpretability of how our VCAM practically assists the learning framework.
Semantics-Guided Clustering with Deep Progressive Learning for Semi-Supervised Person Re-identification
Oct 02, 2020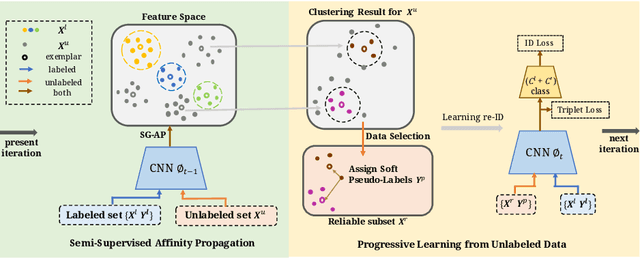
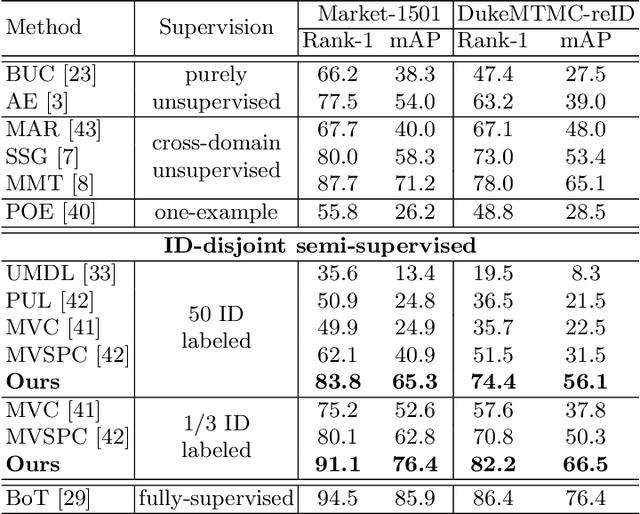
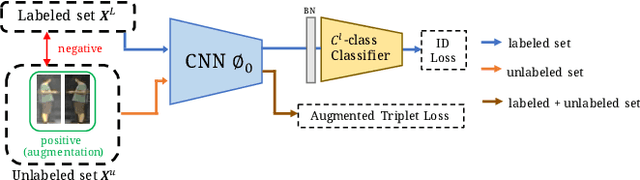
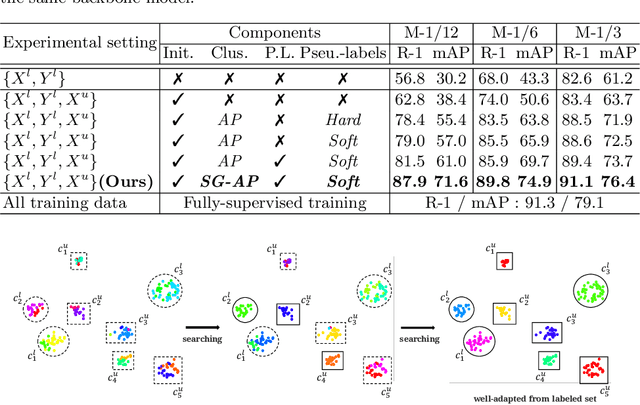
Person re-identification (re-ID) requires one to match images of the same person across camera views. As a more challenging task, semi-supervised re-ID tackles the problem that only a number of identities in training data are fully labeled, while the remaining are unlabeled. Assuming that such labeled and unlabeled training data share disjoint identity labels, we propose a novel framework of Semantics-Guided Clustering with Deep Progressive Learning (SGC-DPL) to jointly exploit the above data. By advancing the proposed Semantics-Guided Affinity Propagation (SG-AP), we are able to assign pseudo-labels to selected unlabeled data in a progressive fashion, under the semantics guidance from the labeled ones. As a result, our approach is able to augment the labeled training data in the semi-supervised setting. Our experiments on two large-scale person re-ID benchmarks demonstrate the superiority of our SGC-DPL over state-of-the-art methods across different degrees of supervision. In extension, the generalization ability of our SGC-DPL is also verified in other tasks like vehicle re-ID or image retrieval with the semi-supervised setting.
Orientation-aware Vehicle Re-identification with Semantics-guided Part Attention Network
Aug 26, 2020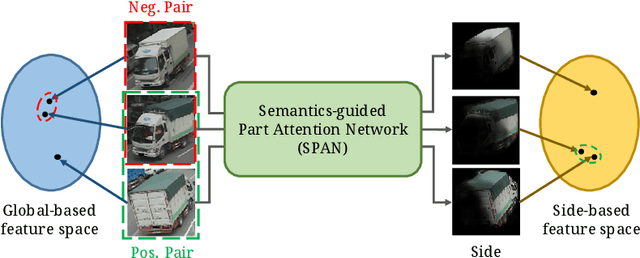


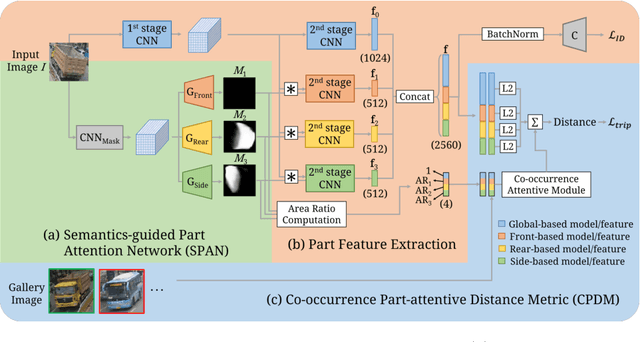
Vehicle re-identification (re-ID) focuses on matching images of the same vehicle across different cameras. It is fundamentally challenging because differences between vehicles are sometimes subtle. While several studies incorporate spatial-attention mechanisms to help vehicle re-ID, they often require expensive keypoint labels or suffer from noisy attention mask if not trained with expensive labels. In this work, we propose a dedicated Semantics-guided Part Attention Network (SPAN) to robustly predict part attention masks for different views of vehicles given only image-level semantic labels during training. With the help of part attention masks, we can extract discriminative features in each part separately. Then we introduce Co-occurrence Part-attentive Distance Metric (CPDM) which places greater emphasis on co-occurrence vehicle parts when evaluating the feature distance of two images. Extensive experiments validate the effectiveness of the proposed method and show that our framework outperforms the state-of-the-art approaches.
Spatially and Temporally Efficient Non-local Attention Network for Video-based Person Re-Identification
Aug 05, 2019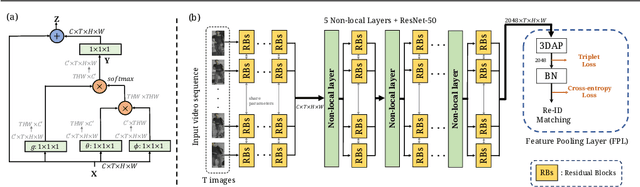
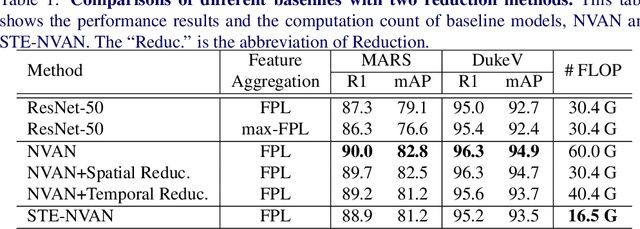
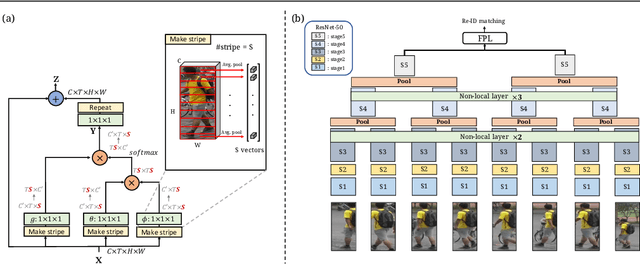
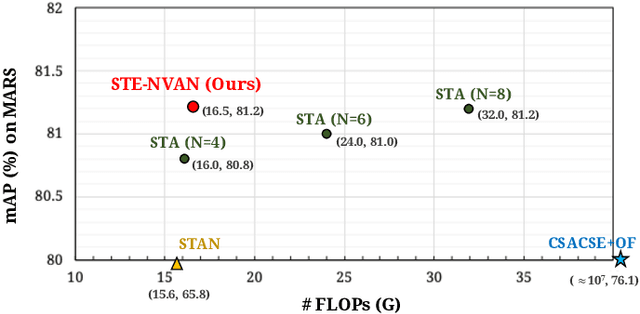
Video-based person re-identification (Re-ID) aims at matching video sequences of pedestrians across non-overlapping cameras. It is a practical yet challenging task of how to embed spatial and temporal information of a video into its feature representation. While most existing methods learn the video characteristics by aggregating image-wise features and designing attention mechanisms in Neural Networks, they only explore the correlation between frames at high-level features. In this work, we target at refining the intermediate features as well as high-level features with non-local attention operations and make two contributions. (i) We propose a Non-local Video Attention Network (NVAN) to incorporate video characteristics into the representation at multiple feature levels. (ii) We further introduce a Spatially and Temporally Efficient Non-local Video Attention Network (STE-NVAN) to reduce the computation complexity by exploring spatial and temporal redundancy presented in pedestrian videos. Extensive experiments show that our NVAN outperforms state-of-the-arts by 3.8% in rank-1 accuracy on MARS dataset and confirms our STE-NVAN displays a much superior computation footprint compared to existing methods.
* This paper was accepted by 2019 British Machine Vision Conference (BMVC)
Increasing Compactness Of Deep Learning Based Speech Enhancement Models With Parameter Pruning And Quantization Techniques
May 31, 2019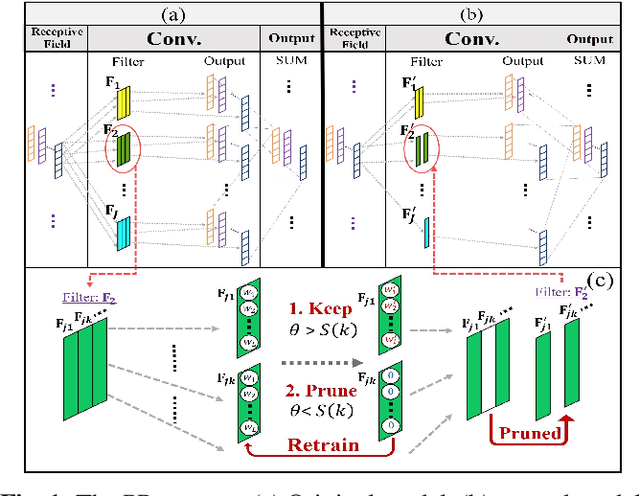
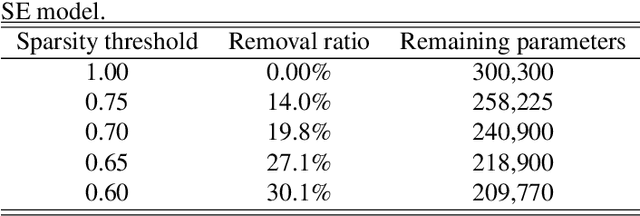

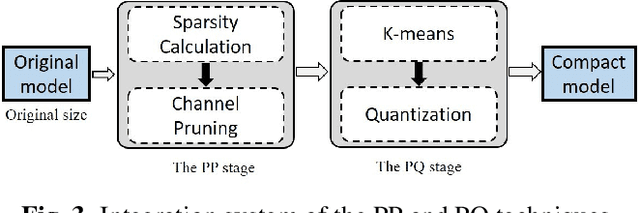
Most recent studies on deep learning based speech enhancement (SE) focused on improving denoising performance. However, successful SE applications require striking a desirable balance between denoising performance and computational cost in real scenarios. In this study, we propose a novel parameter pruning (PP) technique, which removes redundant channels in a neural network. In addition, a parameter quantization (PQ) technique was applied to reduce the size of a neural network by representing weights with fewer cluster centroids. Because the techniques are derived based on different concepts, the PP and PQ can be integrated to provide even more compact SE models. The experimental results show that the PP and PQ techniques produce a compacted SE model with a size of only 10.03% compared to that of the original model, resulting in minor performance losses of 1.43% (from 0.70 to 0.69) for STOI and 3.24% (from 1.85 to 1.79) for PESQ. The promising results suggest that the PP and PQ techniques can be used in a SE system in devices with limited storage and computation resources.