 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncreasing Compactness Of Deep Learning Based Speech Enhancement Models With Parameter Pruning And Quantization Techniques
May 31, 2019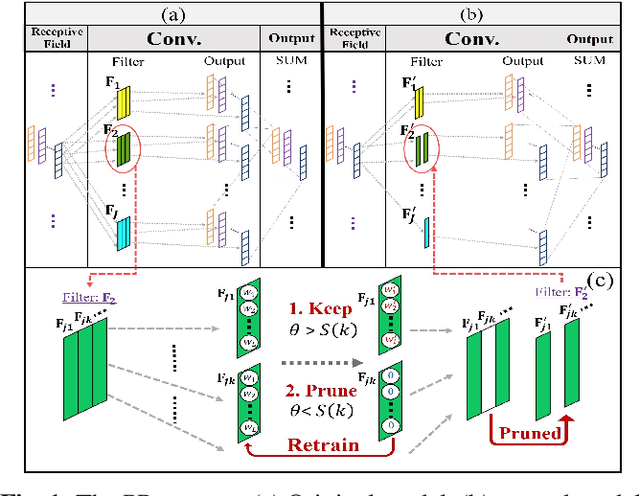
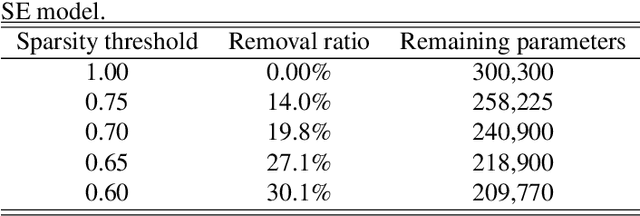

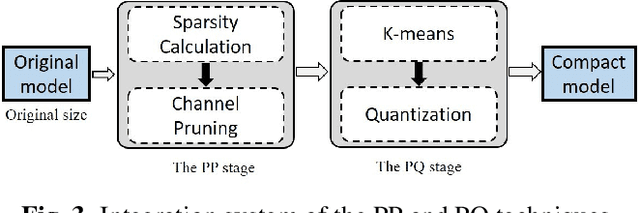
Most recent studies on deep learning based speech enhancement (SE) focused on improving denoising performance. However, successful SE applications require striking a desirable balance between denoising performance and computational cost in real scenarios. In this study, we propose a novel parameter pruning (PP) technique, which removes redundant channels in a neural network. In addition, a parameter quantization (PQ) technique was applied to reduce the size of a neural network by representing weights with fewer cluster centroids. Because the techniques are derived based on different concepts, the PP and PQ can be integrated to provide even more compact SE models. The experimental results show that the PP and PQ techniques produce a compacted SE model with a size of only 10.03% compared to that of the original model, resulting in minor performance losses of 1.43% (from 0.70 to 0.69) for STOI and 3.24% (from 1.85 to 1.79) for PESQ. The promising results suggest that the PP and PQ techniques can be used in a SE system in devices with limited storage and computation resources.