 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive Object Segmentation with Dynamic Click Transform
Jun 19, 2021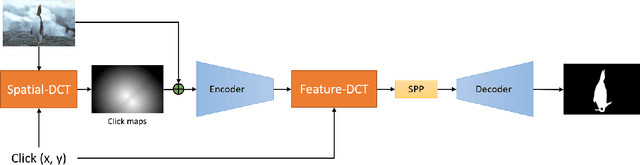


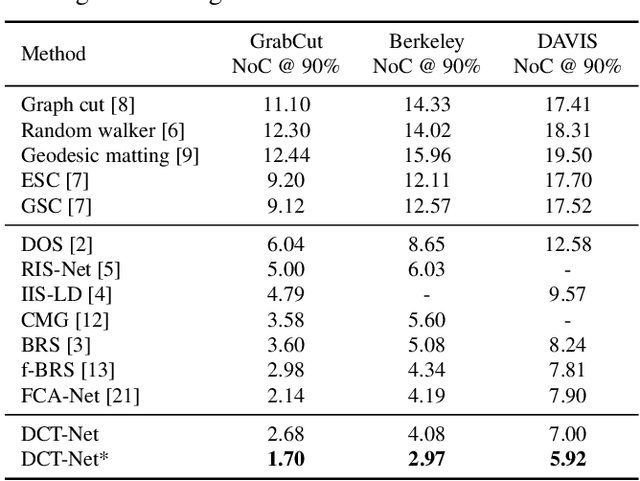
In the interactive segmentation, users initially click on the target object to segment the main body and then provide corrections on mislabeled regions to iteratively refine the segmentation masks. Most existing methods transform these user-provided clicks into interaction maps and concatenate them with image as the input tensor. Typically, the interaction maps are determined by measuring the distance of each pixel to the clicked points, ignoring the relation between clicks and mislabeled regions. We propose a Dynamic Click Transform Network~(DCT-Net), consisting of Spatial-DCT and Feature-DCT, to better represent user interactions. Spatial-DCT transforms each user-provided click with individual diffusion distance according to the target scale, and Feature-DCT normalizes the extracted feature map to a specific distribution predicted from the clicked points. We demonstrate the effectiveness of our proposed method and achieve favorable performance compared to the state-of-the-art on three standard benchmark datasets.