 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$Δ$ynamics: Language-Based Representation for Inferring Rigid-Body Dynamics From Videos
May 20, 2026Inferring rigid-body physical states and properties from monocular videos is a fundamental step toward physics-based perception and simulation. Existing approaches assume specific underlying physical systems, object types, and camera poses, making them unable to generalize to complex real-world settings. We introduce $Δ$YNAMICS, a vision-language framework that uses language as a unified representation of rigid-body dynamics. Instead of directly predicting parameters, $Δ$YNAMICS generates scene configurations in a structured text format for physics simulation. We enhance the model's generalization by integrating natural language motion reasoning and leveraging optical flow as a semantic-agnostic input. On the CLEVRER dataset, $Δ$YNAMICS achieves a segmentation IoU of 0.30, a 7x improvement over leading VLMs (InternVL3-8B, Qwen2.5-VL-7B and Claude-4-Sonnet). Additionally, test-time sampling and evolutionary search further boost performance by 27% and 120% in segmentation IoU, respectively. Finally, we demonstrate strong transfer to a new dataset of 235 real-world rigid-body videos, highlighting the potential of language-driven physics inference for bridging perception and simulation.
Temporal Prompting Matters: Rethinking Referring Video Object Segmentation
Oct 08, 2025Referring Video Object Segmentation (RVOS) aims to segment the object referred to by the query sentence in the video. Most existing methods require end-to-end training with dense mask annotations, which could be computation-consuming and less scalable. In this work, we rethink the RVOS problem and aim to investigate the key to this task. Based on existing foundation segmentation models, we decompose the RVOS task into referring, video, and segmentation factors, and propose a Temporal Prompt Generation and Selection (Tenet) framework to address the referring and video factors while leaving the segmentation problem to foundation models. To efficiently adapt image-based foundation segmentation models to referring video object segmentation, we leverage off-the-shelf object detectors and trackers to produce temporal prompts associated with the referring sentence. While high-quality temporal prompts could be produced, they can not be easily identified from confidence scores. To tackle this issue, we propose Prompt Preference Learning to evaluate the quality of the produced temporal prompts. By taking such prompts to instruct image-based foundation segmentation models, we would be able to produce high-quality masks for the referred object, enabling efficient model adaptation to referring video object segmentation. Experiments on RVOS benchmarks demonstrate the effectiveness of the Tenet framework.
BOFormer: Learning to Solve Multi-Objective Bayesian Optimization via Non-Markovian RL
May 29, 2025Bayesian optimization (BO) offers an efficient pipeline for optimizing black-box functions with the help of a Gaussian process prior and an acquisition function (AF). Recently, in the context of single-objective BO, learning-based AFs witnessed promising empirical results given its favorable non-myopic nature. Despite this, the direct extension of these approaches to multi-objective Bayesian optimization (MOBO) suffer from the \textit{hypervolume identifiability issue}, which results from the non-Markovian nature of MOBO problems. To tackle this, inspired by the non-Markovian RL literature and the success of Transformers in language modeling, we present a generalized deep Q-learning framework and propose \textit{BOFormer}, which substantiates this framework for MOBO via sequence modeling. Through extensive evaluation, we demonstrate that BOFormer constantly outperforms the benchmark rule-based and learning-based algorithms in various synthetic MOBO and real-world multi-objective hyperparameter optimization problems. We have made the source code publicly available to encourage further research in this direction.
Towards a Foundation Model for Communication Systems
May 20, 2025
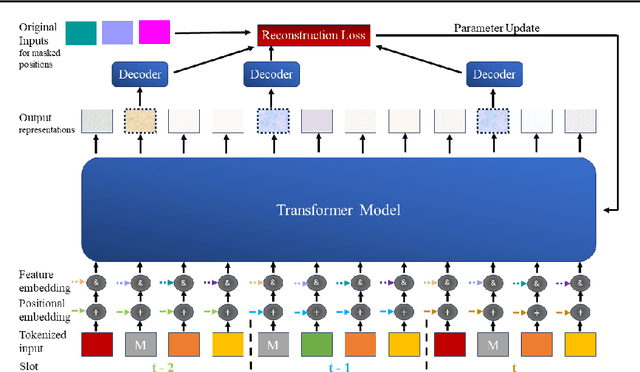
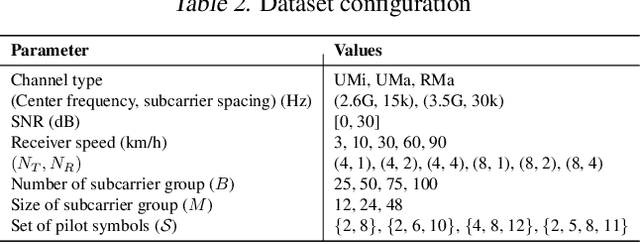
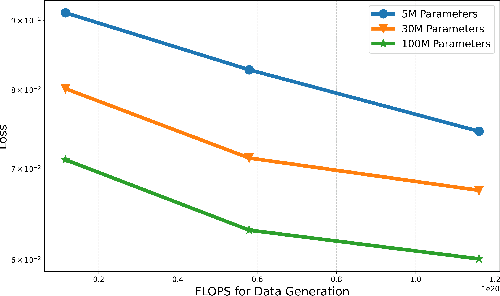
Artificial Intelligence (AI) has demonstrated unprecedented performance across various domains, and its application to communication systems is an active area of research. While current methods focus on task-specific solutions, the broader trend in AI is shifting toward large general models capable of supporting multiple applications. In this work, we take a step toward a foundation model for communication data--a transformer-based, multi-modal model designed to operate directly on communication data. We propose methodologies to address key challenges, including tokenization, positional embedding, multimodality, variable feature sizes, and normalization. Furthermore, we empirically demonstrate that such a model can successfully estimate multiple features, including transmission rank, selected precoder, Doppler spread, and delay profile.
SANER: Annotation-free Societal Attribute Neutralizer for Debiasing CLIP
Aug 19, 2024Large-scale vision-language models, such as CLIP, are known to contain harmful societal bias regarding protected attributes (e.g., gender and age). In this paper, we aim to address the problems of societal bias in CLIP. Although previous studies have proposed to debias societal bias through adversarial learning or test-time projecting, our comprehensive study of these works identifies two critical limitations: 1) loss of attribute information when it is explicitly disclosed in the input and 2) use of the attribute annotations during debiasing process. To mitigate societal bias in CLIP and overcome these limitations simultaneously, we introduce a simple-yet-effective debiasing method called SANER (societal attribute neutralizer) that eliminates attribute information from CLIP text features only of attribute-neutral descriptions. Experimental results show that SANER, which does not require attribute annotations and preserves original information for attribute-specific descriptions, demonstrates superior debiasing ability than the existing methods.
GroPrompt: Efficient Grounded Prompting and Adaptation for Referring Video Object Segmentation
Jun 18, 2024

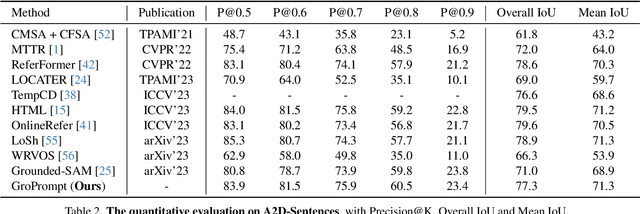

Referring Video Object Segmentation (RVOS) aims to segment the object referred to by the query sentence throughout the entire video. Most existing methods require end-to-end training with dense mask annotations, which could be computation-consuming and less scalable. In this work, we aim to efficiently adapt foundation segmentation models for addressing RVOS from weak supervision with the proposed Grounded Prompting (GroPrompt) framework. More specifically, we propose Text-Aware Prompt Contrastive Learning (TAP-CL) to enhance the association between the position prompts and the referring sentences with only box supervisions, including Text-Contrastive Prompt Learning (TextCon) and Modality-Contrastive Prompt Learning (ModalCon) at frame level and video level, respectively. With the proposed TAP-CL, our GroPrompt framework can generate temporal-consistent yet text-aware position prompts describing locations and movements for the referred object from the video. The experimental results in the standard RVOS benchmarks (Ref-YouTube-VOS, Ref-DAVIS17, A2D-Sentences, and JHMDB-Sentences) demonstrate the competitive performance of our proposed GroPrompt framework given only bounding box weak supervisions.
MCPNet: An Interpretable Classifier via Multi-Level Concept Prototypes
Apr 13, 2024Recent advancements in post-hoc and inherently interpretable methods have markedly enhanced the explanations of black box classifier models. These methods operate either through post-analysis or by integrating concept learning during model training. Although being effective in bridging the semantic gap between a model's latent space and human interpretation, these explanation methods only partially reveal the model's decision-making process. The outcome is typically limited to high-level semantics derived from the last feature map. We argue that the explanations lacking insights into the decision processes at low and mid-level features are neither fully faithful nor useful. Addressing this gap, we introduce the Multi-Level Concept Prototypes Classifier (MCPNet), an inherently interpretable model. MCPNet autonomously learns meaningful concept prototypes across multiple feature map levels using Centered Kernel Alignment (CKA) loss and an energy-based weighted PCA mechanism, and it does so without reliance on predefined concept labels. Further, we propose a novel classifier paradigm that learns and aligns multi-level concept prototype distributions for classification purposes via Class-aware Concept Distribution (CCD) loss. Our experiments reveal that our proposed MCPNet while being adaptable to various model architectures, offers comprehensive multi-level explanations while maintaining classification accuracy. Additionally, its concept distribution-based classification approach shows improved generalization capabilities in few-shot classification scenarios.
DoRA: Weight-Decomposed Low-Rank Adaptation
Feb 14, 2024Among the widely used parameter-efficient finetuning (PEFT) methods, LoRA and its variants have gained considerable popularity because of avoiding additional inference costs. However, there still often exists an accuracy gap between these methods and full fine-tuning (FT). In this work, we first introduce a novel weight decomposition analysis to investigate the inherent differences between FT and LoRA. Aiming to resemble the learning capacity of FT from the findings, we propose Weight-Decomposed LowRank Adaptation (DoRA). DoRA decomposes the pre-trained weight into two components, magnitude and direction, for fine-tuning, specifically employing LoRA for directional updates to efficiently minimize the number of trainable parameters. By employing DoRA, we enhance both the learning capacity and training stability of LoRA while avoiding any additional inference overhead. DoRA consistently outperforms LoRA on fine-tuning LLaMA, LLaVA, and VL-BART on various downstream tasks, such as commonsense reasoning, visual instruction tuning, and image/video-text understanding.
SemPLeS: Semantic Prompt Learning for Weakly-Supervised Semantic Segmentation
Jan 22, 2024Weakly-Supervised Semantic Segmentation (WSSS) aims to train segmentation models using training image data with only image-level supervision. Since precise pixel-level annotations are not accessible, existing methods typically focus on producing pseudo masks for training segmentation models by refining CAM-like heatmaps. However, the produced heatmaps may only capture discriminative image regions of target object categories or the associated co-occurring backgrounds. To address the issues, we propose a Semantic Prompt Learning for WSSS (SemPLeS) framework, which learns to effectively prompt the CLIP space to enhance the semantic alignment between the segmented regions and the target object categories. More specifically, we propose Contrastive Prompt Learning and Class-associated Semantic Refinement to learn the prompts that adequately describe and suppress the image backgrounds associated with each target object category. In this way, our proposed framework is able to perform better semantic matching between object regions and the associated text labels, resulting in desired pseudo masks for training the segmentation model. The proposed SemPLeS framework achieves SOTA performance on the standard WSSS benchmarks, PASCAL VOC and MS COCO, and demonstrated interpretability with the semantic visualization of our learned prompts. The codes will be released.
Probabilistic 3D Multi-Object Cooperative Tracking for Autonomous Driving via Differentiable Multi-Sensor Kalman Filter
Sep 26, 2023Current state-of-the-art autonomous driving vehicles mainly rely on each individual sensor system to perform perception tasks. Such a framework's reliability could be limited by occlusion or sensor failure. To address this issue, more recent research proposes using vehicle-to-vehicle (V2V) communication to share perception information with others. However, most relevant works focus only on cooperative detection and leave cooperative tracking an underexplored research field. A few recent datasets, such as V2V4Real, provide 3D multi-object cooperative tracking benchmarks. However, their proposed methods mainly use cooperative detection results as input to a standard single-sensor Kalman Filter-based tracking algorithm. In their approach, the measurement uncertainty of different sensors from different connected autonomous vehicles (CAVs) may not be properly estimated to utilize the theoretical optimality property of Kalman Filter-based tracking algorithms. In this paper, we propose a novel 3D multi-object cooperative tracking algorithm for autonomous driving via a differentiable multi-sensor Kalman Filter. Our algorithm learns to estimate measurement uncertainty for each detection that can better utilize the theoretical property of Kalman Filter-based tracking methods. The experiment results show that our algorithm improves the tracking accuracy by 17% with only 0.037x communication costs compared with the state-of-the-art method in V2V4Real.