 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Prompting Matters: Rethinking Referring Video Object Segmentation
Oct 08, 2025Referring Video Object Segmentation (RVOS) aims to segment the object referred to by the query sentence in the video. Most existing methods require end-to-end training with dense mask annotations, which could be computation-consuming and less scalable. In this work, we rethink the RVOS problem and aim to investigate the key to this task. Based on existing foundation segmentation models, we decompose the RVOS task into referring, video, and segmentation factors, and propose a Temporal Prompt Generation and Selection (Tenet) framework to address the referring and video factors while leaving the segmentation problem to foundation models. To efficiently adapt image-based foundation segmentation models to referring video object segmentation, we leverage off-the-shelf object detectors and trackers to produce temporal prompts associated with the referring sentence. While high-quality temporal prompts could be produced, they can not be easily identified from confidence scores. To tackle this issue, we propose Prompt Preference Learning to evaluate the quality of the produced temporal prompts. By taking such prompts to instruct image-based foundation segmentation models, we would be able to produce high-quality masks for the referred object, enabling efficient model adaptation to referring video object segmentation. Experiments on RVOS benchmarks demonstrate the effectiveness of the Tenet framework.
Continual Personalization for Diffusion Models
Oct 02, 2025



Updating diffusion models in an incremental setting would be practical in real-world applications yet computationally challenging. We present a novel learning strategy of Concept Neuron Selection (CNS), a simple yet effective approach to perform personalization in a continual learning scheme. CNS uniquely identifies neurons in diffusion models that are closely related to the target concepts. In order to mitigate catastrophic forgetting problems while preserving zero-shot text-to-image generation ability, CNS finetunes concept neurons in an incremental manner and jointly preserves knowledge learned of previous concepts. Evaluation of real-world datasets demonstrates that CNS achieves state-of-the-art performance with minimal parameter adjustments, outperforming previous methods in both single and multi-concept personalization works. CNS also achieves fusion-free operation, reducing memory storage and processing time for continual personalization.
GroPrompt: Efficient Grounded Prompting and Adaptation for Referring Video Object Segmentation
Jun 18, 2024

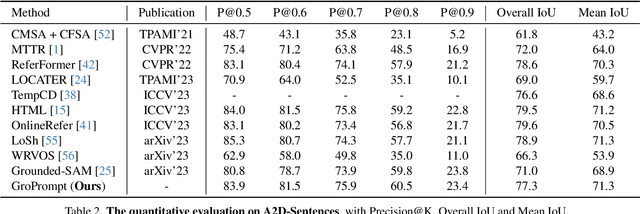

Referring Video Object Segmentation (RVOS) aims to segment the object referred to by the query sentence throughout the entire video. Most existing methods require end-to-end training with dense mask annotations, which could be computation-consuming and less scalable. In this work, we aim to efficiently adapt foundation segmentation models for addressing RVOS from weak supervision with the proposed Grounded Prompting (GroPrompt) framework. More specifically, we propose Text-Aware Prompt Contrastive Learning (TAP-CL) to enhance the association between the position prompts and the referring sentences with only box supervisions, including Text-Contrastive Prompt Learning (TextCon) and Modality-Contrastive Prompt Learning (ModalCon) at frame level and video level, respectively. With the proposed TAP-CL, our GroPrompt framework can generate temporal-consistent yet text-aware position prompts describing locations and movements for the referred object from the video. The experimental results in the standard RVOS benchmarks (Ref-YouTube-VOS, Ref-DAVIS17, A2D-Sentences, and JHMDB-Sentences) demonstrate the competitive performance of our proposed GroPrompt framework given only bounding box weak supervisions.
SemPLeS: Semantic Prompt Learning for Weakly-Supervised Semantic Segmentation
Jan 22, 2024Weakly-Supervised Semantic Segmentation (WSSS) aims to train segmentation models using training image data with only image-level supervision. Since precise pixel-level annotations are not accessible, existing methods typically focus on producing pseudo masks for training segmentation models by refining CAM-like heatmaps. However, the produced heatmaps may only capture discriminative image regions of target object categories or the associated co-occurring backgrounds. To address the issues, we propose a Semantic Prompt Learning for WSSS (SemPLeS) framework, which learns to effectively prompt the CLIP space to enhance the semantic alignment between the segmented regions and the target object categories. More specifically, we propose Contrastive Prompt Learning and Class-associated Semantic Refinement to learn the prompts that adequately describe and suppress the image backgrounds associated with each target object category. In this way, our proposed framework is able to perform better semantic matching between object regions and the associated text labels, resulting in desired pseudo masks for training the segmentation model. The proposed SemPLeS framework achieves SOTA performance on the standard WSSS benchmarks, PASCAL VOC and MS COCO, and demonstrated interpretability with the semantic visualization of our learned prompts. The codes will be released.
Language-Guided Transformer for Federated Multi-Label Classification
Dec 12, 2023Federated Learning (FL) is an emerging paradigm that enables multiple users to collaboratively train a robust model in a privacy-preserving manner without sharing their private data. Most existing approaches of FL only consider traditional single-label image classification, ignoring the impact when transferring the task to multi-label image classification. Nevertheless, it is still challenging for FL to deal with user heterogeneity in their local data distribution in the real-world FL scenario, and this issue becomes even more severe in multi-label image classification. Inspired by the recent success of Transformers in centralized settings, we propose a novel FL framework for multi-label classification. Since partial label correlation may be observed by local clients during training, direct aggregation of locally updated models would not produce satisfactory performances. Thus, we propose a novel FL framework of Language-Guided Transformer (FedLGT) to tackle this challenging task, which aims to exploit and transfer knowledge across different clients for learning a robust global model. Through extensive experiments on various multi-label datasets (e.g., FLAIR, MS-COCO, etc.), we show that our FedLGT is able to achieve satisfactory performance and outperforms standard FL techniques under multi-label FL scenarios. Code is available at https://github.com/Jack24658735/FedLGT.
Frequency-Aware Self-Supervised Long-Tailed Learning
Sep 15, 2023Data collected from the real world typically exhibit long-tailed distributions, where frequent classes contain abundant data while rare ones have only a limited number of samples. While existing supervised learning approaches have been proposed to tackle such data imbalance, the requirement of label supervision would limit their applicability to real-world scenarios in which label annotation might not be available. Without the access to class labels nor the associated class frequencies, we propose Frequency-Aware Self-Supervised Learning (FASSL) in this paper. Targeting at learning from unlabeled data with inherent long-tailed distributions, the goal of FASSL is to produce discriminative feature representations for downstream classification tasks. In FASSL, we first learn frequency-aware prototypes, reflecting the associated long-tailed distribution. Particularly focusing on rare-class samples, the relationships between image data and the derived prototypes are further exploited with the introduced self-supervised learning scheme. Experiments on long-tailed image datasets quantitatively and qualitatively verify the effectiveness of our learning scheme.
Few-Shot Classification in Unseen Domains by Episodic Meta-Learning Across Visual Domains
Dec 27, 2021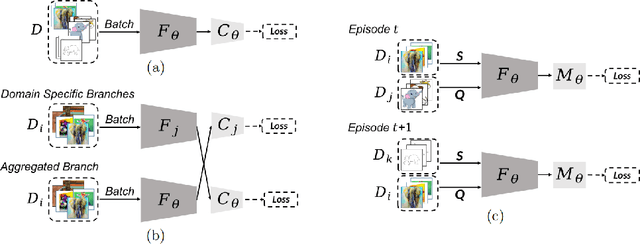


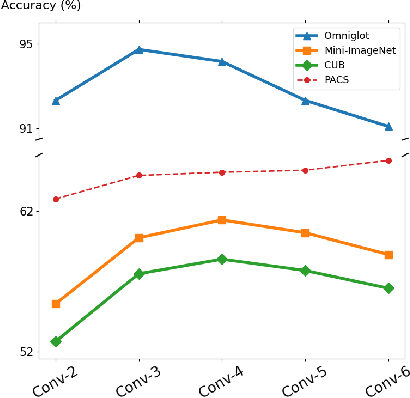
Few-shot classification aims to carry out classification given only few labeled examples for the categories of interest. Though several approaches have been proposed, most existing few-shot learning (FSL) models assume that base and novel classes are drawn from the same data domain. When it comes to recognizing novel-class data in an unseen domain, this becomes an even more challenging task of domain generalized few-shot classification. In this paper, we present a unique learning framework for domain-generalized few-shot classification, where base classes are from homogeneous multiple source domains, while novel classes to be recognized are from target domains which are not seen during training. By advancing meta-learning strategies, our learning framework exploits data across multiple source domains to capture domain-invariant features, with FSL ability introduced by metric-learning based mechanisms across support and query data. We conduct extensive experiments to verify the effectiveness of our proposed learning framework and show learning from small yet homogeneous source data is able to perform preferably against learning from large-scale one. Moreover, we provide insights into choices of backbone models for domain-generalized few-shot classification.
Meta-Learned Feature Critics for Domain Generalized Semantic Segmentation
Dec 27, 2021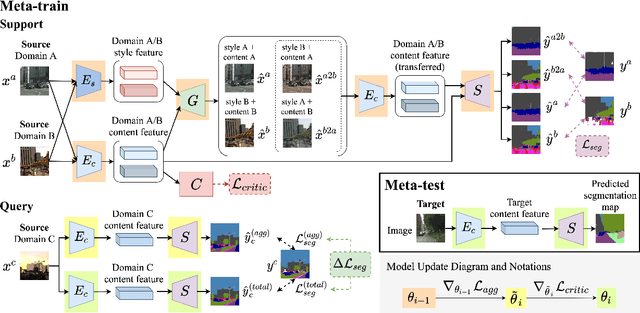



How to handle domain shifts when recognizing or segmenting visual data across domains has been studied by learning and vision communities. In this paper, we address domain generalized semantic segmentation, in which the segmentation model is trained on multiple source domains and is expected to generalize to unseen data domains. We propose a novel meta-learning scheme with feature disentanglement ability, which derives domain-invariant features for semantic segmentation with domain generalization guarantees. In particular, we introduce a class-specific feature critic module in our framework, enforcing the disentangled visual features with domain generalization guarantees. Finally, our quantitative results on benchmark datasets confirm the effectiveness and robustness of our proposed model, performing favorably against state-of-the-art domain adaptation and generalization methods in segmentation.
Semantics-Guided Representation Learning with Applications to Visual Synthesis
Oct 21, 2020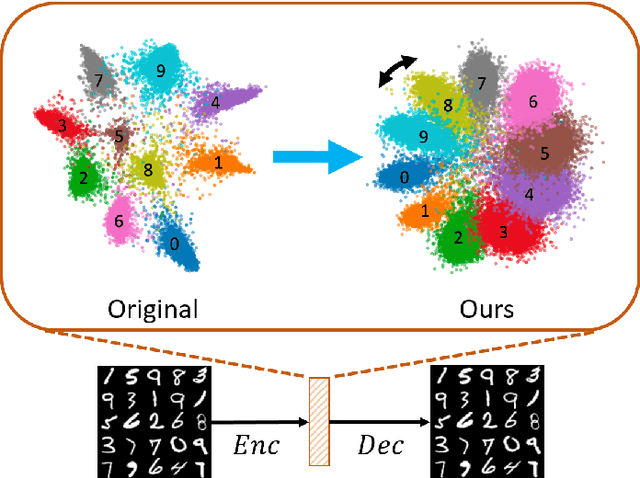

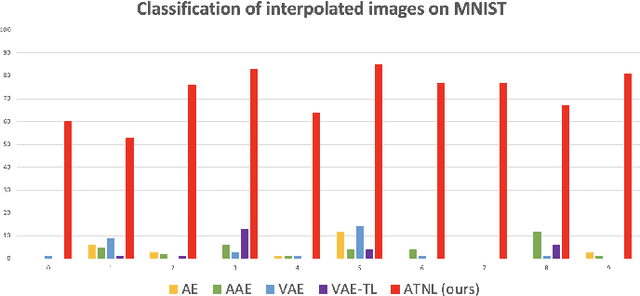
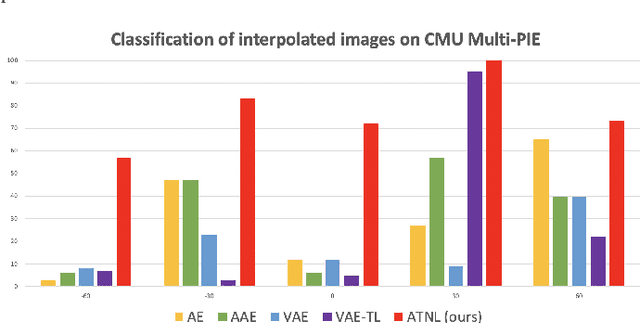
Learning interpretable and interpolatable latent representations has been an emerging research direction, allowing researchers to understand and utilize the derived latent space for further applications such as visual synthesis or recognition. While most existing approaches derive an interpolatable latent space and induces smooth transition in image appearance, it is still not clear how to observe desirable representations which would contain semantic information of interest. In this paper, we aim to learn meaningful representations and simultaneously perform semantic-oriented and visually-smooth interpolation. To this end, we propose an angular triplet-neighbor loss (ATNL) that enables learning a latent representation whose distribution matches the semantic information of interest. With the latent space guided by ATNL, we further utilize spherical semantic interpolation for generating semantic warping of images, allowing synthesis of desirable visual data. Experiments on MNIST and CMU Multi-PIE datasets qualitatively and quantitatively verify the effectiveness of our method.
Domain Generalized Person Re-Identification via Cross-Domain Episodic Learning
Oct 19, 2020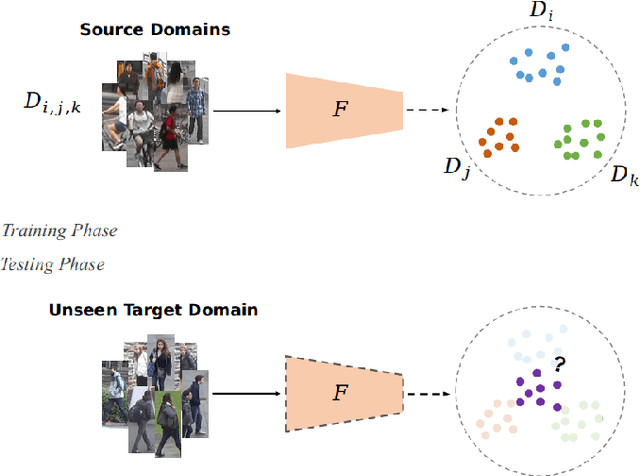
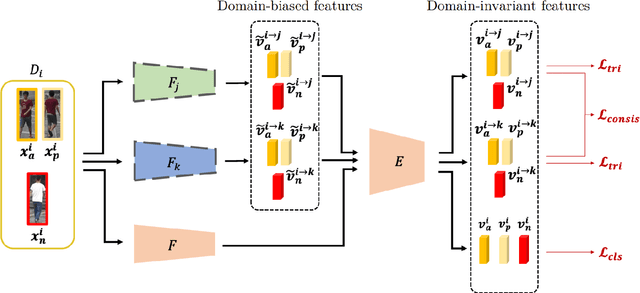
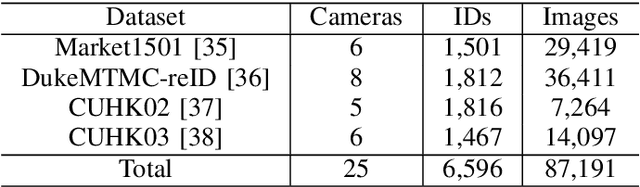

Aiming at recognizing images of the same person across distinct camera views, person re-identification (re-ID) has been among active research topics in computer vision. Most existing re-ID works require collection of a large amount of labeled image data from the scenes of interest. When the data to be recognized are different from the source-domain training ones, a number of domain adaptation approaches have been proposed. Nevertheless, one still needs to collect labeled or unlabelled target-domain data during training. In this paper, we tackle an even more challenging and practical setting, domain generalized (DG) person re-ID. That is, while a number of labeled source-domain datasets are available, we do not have access to any target-domain training data. In order to learn domain-invariant features without knowing the target domain of interest, we present an episodic learning scheme which advances meta learning strategies to exploit the observed source-domain labeled data. The learned features would exhibit sufficient domain-invariant properties while not overfitting the source-domain data or ID labels. Our experiments on four benchmark datasets confirm the superiority of our method over the state-of-the-arts.