 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAX: Tendency-and-Assignment Explainer for Semantic Segmentation with Multi-Annotators
Feb 19, 2023



To understand how deep neural networks perform classification predictions, recent research attention has been focusing on developing techniques to offer desirable explanations. However, most existing methods cannot be easily applied for semantic segmentation; moreover, they are not designed to offer interpretability under the multi-annotator setting. Instead of viewing ground-truth pixel-level labels annotated by a single annotator with consistent labeling tendency, we aim at providing interpretable semantic segmentation and answer two critical yet practical questions: "who" contributes to the resulting segmentation, and "why" such an assignment is determined. In this paper, we present a learning framework of Tendency-and-Assignment Explainer (TAX), designed to offer interpretability at the annotator and assignment levels. More specifically, we learn convolution kernel subsets for modeling labeling tendencies of each type of annotation, while a prototype bank is jointly observed to offer visual guidance for learning the above kernels. For evaluation, we consider both synthetic and real-world datasets with multi-annotators. We show that our TAX can be applied to state-of-the-art network architectures with comparable performances, while segmentation interpretability at both levels can be offered accordingly.
Few-Shot Classification in Unseen Domains by Episodic Meta-Learning Across Visual Domains
Dec 27, 2021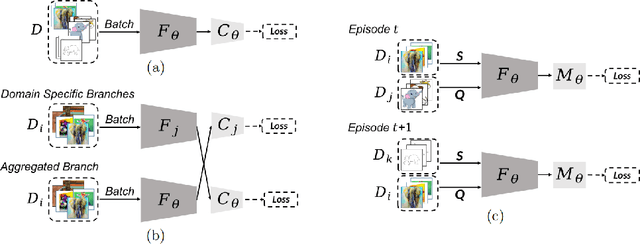


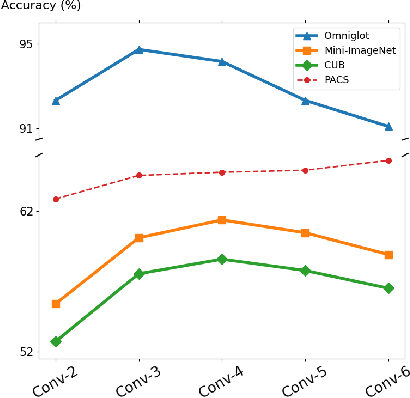
Few-shot classification aims to carry out classification given only few labeled examples for the categories of interest. Though several approaches have been proposed, most existing few-shot learning (FSL) models assume that base and novel classes are drawn from the same data domain. When it comes to recognizing novel-class data in an unseen domain, this becomes an even more challenging task of domain generalized few-shot classification. In this paper, we present a unique learning framework for domain-generalized few-shot classification, where base classes are from homogeneous multiple source domains, while novel classes to be recognized are from target domains which are not seen during training. By advancing meta-learning strategies, our learning framework exploits data across multiple source domains to capture domain-invariant features, with FSL ability introduced by metric-learning based mechanisms across support and query data. We conduct extensive experiments to verify the effectiveness of our proposed learning framework and show learning from small yet homogeneous source data is able to perform preferably against learning from large-scale one. Moreover, we provide insights into choices of backbone models for domain-generalized few-shot classification.
Domain Generalized Person Re-Identification via Cross-Domain Episodic Learning
Oct 19, 2020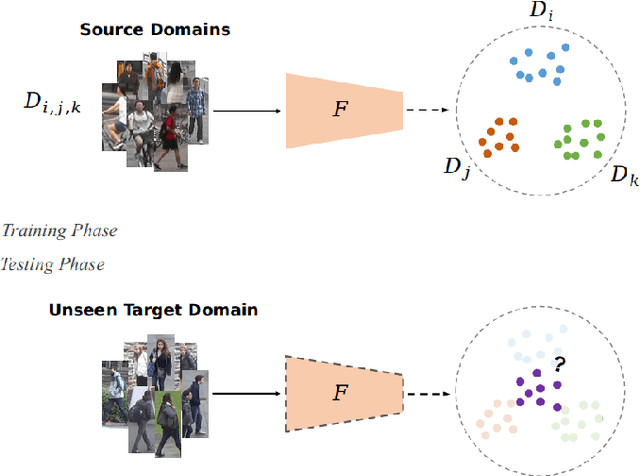
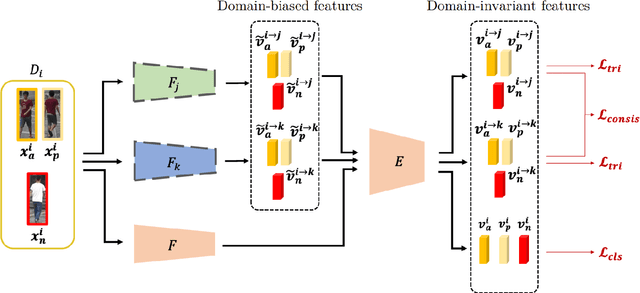
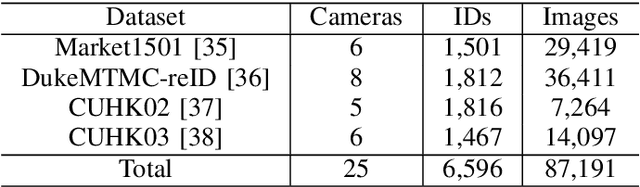

Aiming at recognizing images of the same person across distinct camera views, person re-identification (re-ID) has been among active research topics in computer vision. Most existing re-ID works require collection of a large amount of labeled image data from the scenes of interest. When the data to be recognized are different from the source-domain training ones, a number of domain adaptation approaches have been proposed. Nevertheless, one still needs to collect labeled or unlabelled target-domain data during training. In this paper, we tackle an even more challenging and practical setting, domain generalized (DG) person re-ID. That is, while a number of labeled source-domain datasets are available, we do not have access to any target-domain training data. In order to learn domain-invariant features without knowing the target domain of interest, we present an episodic learning scheme which advances meta learning strategies to exploit the observed source-domain labeled data. The learned features would exhibit sufficient domain-invariant properties while not overfitting the source-domain data or ID labels. Our experiments on four benchmark datasets confirm the superiority of our method over the state-of-the-arts.