 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Deepfake Detection, NTIRE 2026 Challenge: Report
Apr 27, 2026Robustness is a long-overlooked problem in deepfake detection. However, detection performance is nearly worthless in the real world if it suffers under exposure to even slight image degradation. In addition to weaker degradations that can accidentally occur in the image processing pipeline, there is another risk of malicious deepfakes that specifically introduce degradations, purposefully exploiting the detector's weaknesses in that regard. Here, we present an overview of the NTIRE 2026 Robust Deepfake Detection Challenge, which specifically addresses that problem. Participants were tasked with building a detector that would later be tested on an unknown test-set, which included both common and uncommon degradations of various strengths. With a total number of 337 participants and 57 submissions to the final leaderboard, the first edition of the challenge was well received. To ensure the reliability of the results, participants were given only 24h to complete the test run with no labels provided, limiting the possibility of training on the test data. Furthermore, the top solutions were scored on a private test-set to detect any such overfitting. This report presents the competition setting, dataset preparation, as well as details and performance of methods. Top methods rely on large foundation models, ensembles, and degradation training to combine generality and robustness.
NTIRE 2026 Challenge on Single Image Reflection Removal in the Wild: Datasets, Results, and Methods
Apr 11, 2026In this paper, we review the NTIRE 2026 challenge on single-image reflection removal (SIRR) in the Wild. SIRR is a fundamental task in image restoration. Despite progress in academic research, most methods are tested on synthetic images or limited real-world images, creating a gap in real-world applications. In this challenge, we provide participants with the OpenRR-5k dataset, which requires them to process real-world images that cover a range of reflection scenarios and intensities, with the goal of generating clean images without reflections. The challenge attracted more than 100 registrations, with 11 of them participating in the final testing phase. The top-ranked methods advanced the state-of-the-art reflection removal performance and earned unanimous recognition from the five experts in the field. The proposed OpenRR-5k dataset is available at https://huggingface.co/datasets/qiuzhangTiTi/OpenRR-5k, and the homepage of this challenge is at https://github.com/caijie0620/OpenRR-5k. Due to page limitations, this article only presents partial content; the full report and detailed analyses are available in the extended arXiv version.
CANDLE: Illumination-Invariant Semantic Priors for Color Ambient Lighting Normalization
Apr 03, 2026Color ambient lighting normalization under multi-colored illumination is challenging due to severe chromatic shifts, highlight saturation, and material-dependent reflectance. Existing geometric and low-level priors are insufficient for recovering object-intrinsic color when illumination-induced chromatic bias dominates. We observe that DINOv3's self-supervised features remain highly consistent between colored-light inputs and ambient-lit ground truth, motivating their use as illumination-robust semantic priors. We propose CANDLE (Color Ambient Normalization with DINO Layer Enhancement), which introduces DINO Omni-layer Guidance (D.O.G.) to adaptively inject multi-layer DINOv3 features into successive encoder stages, and a color-frequency refinement design (BFACG + SFFB) to suppress decoder-side chromatic collapse and detail contamination. Experiments on CL3AN show a +1.22 dB PSNR gain over the strongest prior method. CANDLE achieves 3rd place on the NTIRE 2026 ALN Color Lighting Challenge and 2nd place in fidelity on the White Lighting track with the lowest FID, confirming strong generalization across both chromatic and luminance-dominant illumination conditions. Code is available at https://github.com/ron941/CANDLE.
Frequency Switching Mechanism for Parameter-E!cient Multi-Task Learning
Mar 22, 2026Multi-task learning (MTL) aims to enable a single model to solve multiple tasks efficiently; however, current parameter-efficient fine-tuning (PEFT) methods remain largely limited to single-task adaptation. We introduce \textbf{Free Sinewich}, a parameter-efficient multi-task learning framework that enables near-zero-cost weight modulation via frequency switching (\textbf{Free}). Specifically, a \textbf{Sine-AWB (Sinewich)} layer combines low-rank factors and convolutional priors into a single kernel, which is then modulated elementwise by a sinusoidal transformation to produce task-specialized weights. A lightweight Clock Net is introduced to produce bounded frequencies that stabilize this modulation during training. Theoretically, sine modulation enhances the rank of low-rank adapters, while frequency separation decorrelates the weights of different tasks. On dense prediction benchmarks, Free Sinewich achieves state-of-the-art performance-efficiency trade-offs (e.g., up to +5.39\% improvement over single-task fine-tuning with only 6.53M trainable parameters), offering a compact and scalable paradigm based on frequency-based parameter sharing. Project page: \href{https://casperliuliuliu.github.io/projects/Free-Sinewich/}{https://casperliuliuliu.github.io/projects/Free-Sinewich}.
VISTA: Validation-Guided Integration of Spatial and Temporal Foundation Models with Anatomical Decoding for Rare-Pathology VCE Event Detection
Mar 18, 2026Capsule endoscopy event detection is challenging because diagnostically relevant findings are sparse, visually heterogeneous, and embedded in long, noisy video streams, while evaluation is performed at the event level rather than by frame accuracy alone. We therefore formulate the RARE-VISION task as a metric-aligned event detection problem instead of a purely frame-wise classification task. Our framework combines two complementary backbones, EndoFM-LV for local temporal context and DINOv3 ViT-L/16 for strong frame-level visual semantics, followed by a Diverse Head Ensemble, Validation-Guided Hierarchical Fusion, and Anatomy-Aware Temporal Event Decoding. The fusion stage uses validation-derived class-wise model weighting, backbone weighting, and probability calibration, while the decoding stage applies temporal smoothing, anatomical constraints, threshold refinement, and per-label event generation to produce stable event predictions. Validation ablations indicate that complementary backbones, validation-guided fusion, and anatomy-aware temporal decoding all contribute to event-level performance. On the official hidden test set, the proposed method achieved an overall temporal mAP@0.5 of 0.3530 and temporal mAP@0.95 of 0.3235.
3AM: 3egment Anything with Geometric Consistency in Videos
Jan 18, 2026Video object segmentation methods like SAM2 achieve strong performance through memory-based architectures but struggle under large viewpoint changes due to reliance on appearance features. Traditional 3D instance segmentation methods address viewpoint consistency but require camera poses, depth maps, and expensive preprocessing. We introduce 3AM, a training-time enhancement that integrates 3D-aware features from MUSt3R into SAM2. Our lightweight Feature Merger fuses multi-level MUSt3R features that encode implicit geometric correspondence. Combined with SAM2's appearance features, the model achieves geometry-consistent recognition grounded in both spatial position and visual similarity. We propose a field-of-view aware sampling strategy ensuring frames observe spatially consistent object regions for reliable 3D correspondence learning. Critically, our method requires only RGB input at inference, with no camera poses or preprocessing. On challenging datasets with wide-baseline motion (ScanNet++, Replica), 3AM substantially outperforms SAM2 and extensions, achieving 90.6% IoU and 71.7% Positive IoU on ScanNet++'s Selected Subset, improving over state-of-the-art VOS methods by +15.9 and +30.4 points. Project page: https://jayisaking.github.io/3AM-Page/
Fast-ThinkAct: Efficient Vision-Language-Action Reasoning via Verbalizable Latent Planning
Jan 14, 2026Vision-Language-Action (VLA) tasks require reasoning over complex visual scenes and executing adaptive actions in dynamic environments. While recent studies on reasoning VLAs show that explicit chain-of-thought (CoT) can improve generalization, they suffer from high inference latency due to lengthy reasoning traces. We propose Fast-ThinkAct, an efficient reasoning framework that achieves compact yet performant planning through verbalizable latent reasoning. Fast-ThinkAct learns to reason efficiently with latent CoTs by distilling from a teacher, driven by a preference-guided objective to align manipulation trajectories that transfers both linguistic and visual planning capabilities for embodied control. This enables reasoning-enhanced policy learning that effectively connects compact reasoning to action execution. Extensive experiments across diverse embodied manipulation and reasoning benchmarks demonstrate that Fast-ThinkAct achieves strong performance with up to 89.3\% reduced inference latency over state-of-the-art reasoning VLAs, while maintaining effective long-horizon planning, few-shot adaptation, and failure recovery.
3AM: Segment Anything with Geometric Consistency in Videos
Jan 13, 2026Video object segmentation methods like SAM2 achieve strong performance through memory-based architectures but struggle under large viewpoint changes due to reliance on appearance features. Traditional 3D instance segmentation methods address viewpoint consistency but require camera poses, depth maps, and expensive preprocessing. We introduce 3AM, a training-time enhancement that integrates 3D-aware features from MUSt3R into SAM2. Our lightweight Feature Merger fuses multi-level MUSt3R features that encode implicit geometric correspondence. Combined with SAM2's appearance features, the model achieves geometry-consistent recognition grounded in both spatial position and visual similarity. We propose a field-of-view aware sampling strategy ensuring frames observe spatially consistent object regions for reliable 3D correspondence learning. Critically, our method requires only RGB input at inference, with no camera poses or preprocessing. On challenging datasets with wide-baseline motion (ScanNet++, Replica), 3AM substantially outperforms SAM2 and extensions, achieving 90.6% IoU and 71.7% Positive IoU on ScanNet++'s Selected Subset, improving over state-of-the-art VOS methods by +15.9 and +30.4 points. Project page: https://jayisaking.github.io/3AM-Page/
TA-Prompting: Enhancing Video Large Language Models for Dense Video Captioning via Temporal Anchors
Jan 06, 2026Dense video captioning aims to interpret and describe all temporally localized events throughout an input video. Recent state-of-the-art methods leverage large language models (LLMs) to provide detailed moment descriptions for video data. However, existing VideoLLMs remain challenging in identifying precise event boundaries in untrimmed videos, causing the generated captions to be not properly grounded. In this paper, we propose TA-Prompting, which enhances VideoLLMs via Temporal Anchors that learn to precisely localize events and prompt the VideoLLMs to perform temporal-aware video event understanding. During inference, in order to properly determine the output caption sequence from an arbitrary number of events presented within a video, we introduce an event coherent sampling strategy to select event captions with sufficient coherence across temporal events and cross-modal similarity with the given video. Through extensive experiments on benchmark datasets, we show that our TA-Prompting is favorable against state-of-the-art VideoLLMs, yielding superior performance on dense video captioning and temporal understanding tasks including moment retrieval and temporalQA.
* 8 pages for main paper (exclude citation pages), 6 pages for appendix, totally 10 figures 7 tables and 2 algorithms. The paper is accepted by WACV 2026
VADER: Towards Causal Video Anomaly Understanding with Relation-Aware Large Language Models
Nov 10, 2025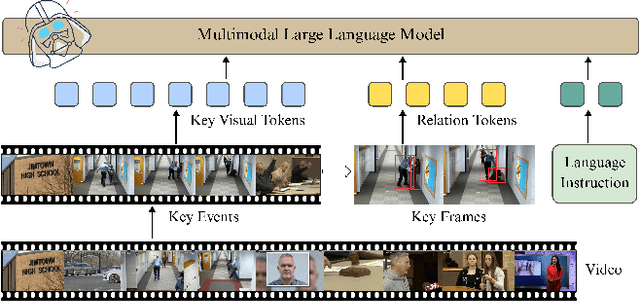
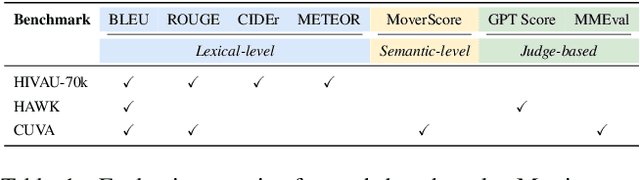
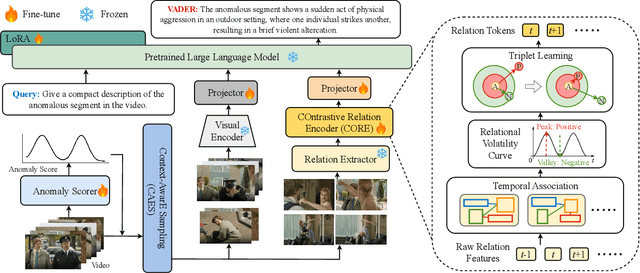
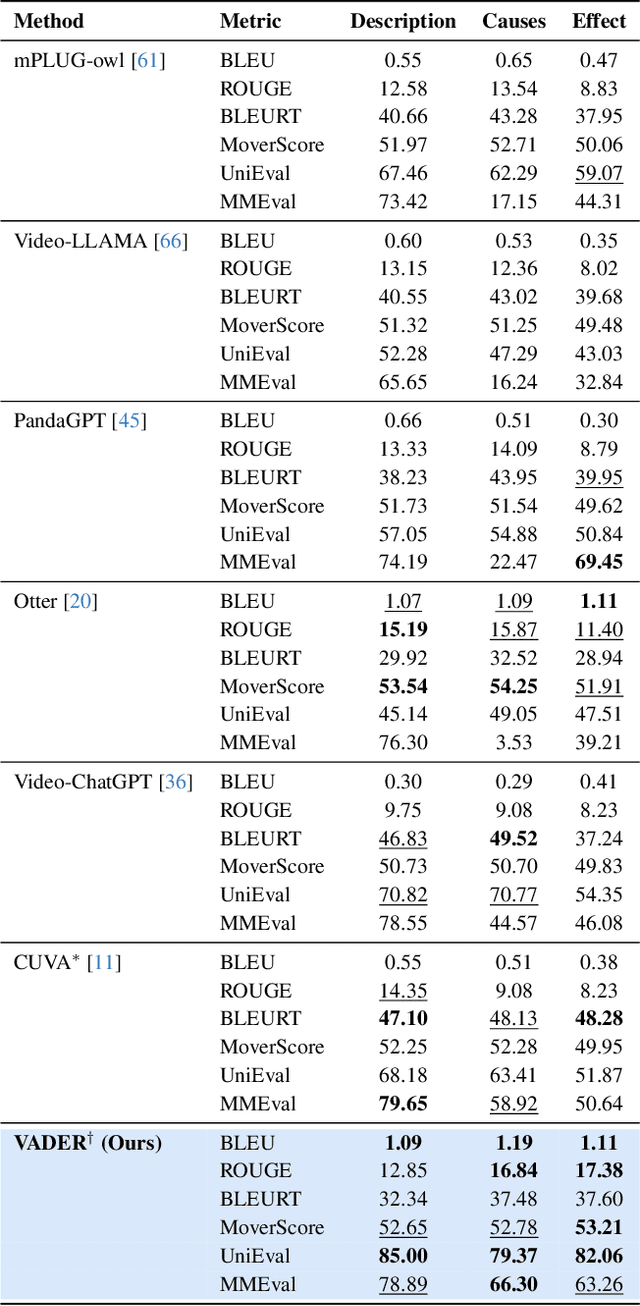
Video anomaly understanding (VAU) aims to provide detailed interpretation and semantic comprehension of anomalous events within videos, addressing limitations of traditional methods that focus solely on detecting and localizing anomalies. However, existing approaches often neglect the deeper causal relationships and interactions between objects, which are critical for understanding anomalous behaviors. In this paper, we propose VADER, an LLM-driven framework for Video Anomaly unDErstanding, which integrates keyframe object Relation features with visual cues to enhance anomaly comprehension from video. Specifically, VADER first applies an Anomaly Scorer to assign per-frame anomaly scores, followed by a Context-AwarE Sampling (CAES) strategy to capture the causal context of each anomalous event. A Relation Feature Extractor and a COntrastive Relation Encoder (CORE) jointly model dynamic object interactions, producing compact relational representations for downstream reasoning. These visual and relational cues are integrated with LLMs to generate detailed, causally grounded descriptions and support robust anomaly-related question answering. Experiments on multiple real-world VAU benchmarks demonstrate that VADER achieves strong results across anomaly description, explanation, and causal reasoning tasks, advancing the frontier of explainable video anomaly analysis.