 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast-ThinkAct: Efficient Vision-Language-Action Reasoning via Verbalizable Latent Planning
Jan 14, 2026Vision-Language-Action (VLA) tasks require reasoning over complex visual scenes and executing adaptive actions in dynamic environments. While recent studies on reasoning VLAs show that explicit chain-of-thought (CoT) can improve generalization, they suffer from high inference latency due to lengthy reasoning traces. We propose Fast-ThinkAct, an efficient reasoning framework that achieves compact yet performant planning through verbalizable latent reasoning. Fast-ThinkAct learns to reason efficiently with latent CoTs by distilling from a teacher, driven by a preference-guided objective to align manipulation trajectories that transfers both linguistic and visual planning capabilities for embodied control. This enables reasoning-enhanced policy learning that effectively connects compact reasoning to action execution. Extensive experiments across diverse embodied manipulation and reasoning benchmarks demonstrate that Fast-ThinkAct achieves strong performance with up to 89.3\% reduced inference latency over state-of-the-art reasoning VLAs, while maintaining effective long-horizon planning, few-shot adaptation, and failure recovery.
TA-Prompting: Enhancing Video Large Language Models for Dense Video Captioning via Temporal Anchors
Jan 06, 2026Dense video captioning aims to interpret and describe all temporally localized events throughout an input video. Recent state-of-the-art methods leverage large language models (LLMs) to provide detailed moment descriptions for video data. However, existing VideoLLMs remain challenging in identifying precise event boundaries in untrimmed videos, causing the generated captions to be not properly grounded. In this paper, we propose TA-Prompting, which enhances VideoLLMs via Temporal Anchors that learn to precisely localize events and prompt the VideoLLMs to perform temporal-aware video event understanding. During inference, in order to properly determine the output caption sequence from an arbitrary number of events presented within a video, we introduce an event coherent sampling strategy to select event captions with sufficient coherence across temporal events and cross-modal similarity with the given video. Through extensive experiments on benchmark datasets, we show that our TA-Prompting is favorable against state-of-the-art VideoLLMs, yielding superior performance on dense video captioning and temporal understanding tasks including moment retrieval and temporalQA.
* 8 pages for main paper (exclude citation pages), 6 pages for appendix, totally 10 figures 7 tables and 2 algorithms. The paper is accepted by WACV 2026
Continual Personalization for Diffusion Models
Oct 02, 2025



Updating diffusion models in an incremental setting would be practical in real-world applications yet computationally challenging. We present a novel learning strategy of Concept Neuron Selection (CNS), a simple yet effective approach to perform personalization in a continual learning scheme. CNS uniquely identifies neurons in diffusion models that are closely related to the target concepts. In order to mitigate catastrophic forgetting problems while preserving zero-shot text-to-image generation ability, CNS finetunes concept neurons in an incremental manner and jointly preserves knowledge learned of previous concepts. Evaluation of real-world datasets demonstrates that CNS achieves state-of-the-art performance with minimal parameter adjustments, outperforming previous methods in both single and multi-concept personalization works. CNS also achieves fusion-free operation, reducing memory storage and processing time for continual personalization.
ThinkAct: Vision-Language-Action Reasoning via Reinforced Visual Latent Planning
Jul 22, 2025



Vision-language-action (VLA) reasoning tasks require agents to interpret multimodal instructions, perform long-horizon planning, and act adaptively in dynamic environments. Existing approaches typically train VLA models in an end-to-end fashion, directly mapping inputs to actions without explicit reasoning, which hinders their ability to plan over multiple steps or adapt to complex task variations. In this paper, we propose ThinkAct, a dual-system framework that bridges high-level reasoning with low-level action execution via reinforced visual latent planning. ThinkAct trains a multimodal LLM to generate embodied reasoning plans guided by reinforcing action-aligned visual rewards based on goal completion and trajectory consistency. These reasoning plans are compressed into a visual plan latent that conditions a downstream action model for robust action execution on target environments. Extensive experiments on embodied reasoning and robot manipulation benchmarks demonstrate that ThinkAct enables few-shot adaptation, long-horizon planning, and self-correction behaviors in complex embodied AI tasks.
VideoMage: Multi-Subject and Motion Customization of Text-to-Video Diffusion Models
Mar 27, 2025


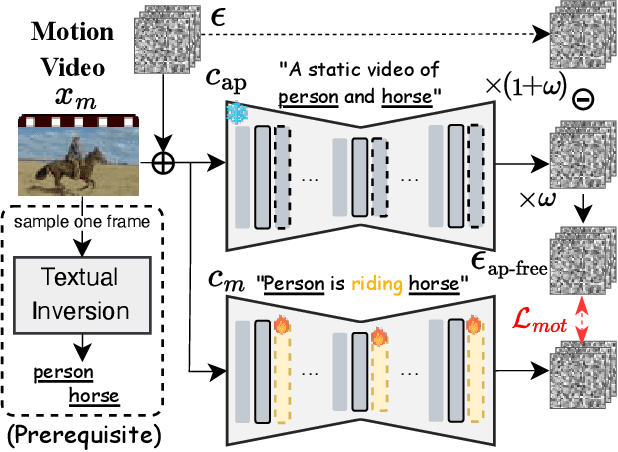
Customized text-to-video generation aims to produce high-quality videos that incorporate user-specified subject identities or motion patterns. However, existing methods mainly focus on personalizing a single concept, either subject identity or motion pattern, limiting their effectiveness for multiple subjects with the desired motion patterns. To tackle this challenge, we propose a unified framework VideoMage for video customization over both multiple subjects and their interactive motions. VideoMage employs subject and motion LoRAs to capture personalized content from user-provided images and videos, along with an appearance-agnostic motion learning approach to disentangle motion patterns from visual appearance. Furthermore, we develop a spatial-temporal composition scheme to guide interactions among subjects within the desired motion patterns. Extensive experiments demonstrate that VideoMage outperforms existing methods, generating coherent, user-controlled videos with consistent subject identities and interactions.
MotionMatcher: Motion Customization of Text-to-Video Diffusion Models via Motion Feature Matching
Feb 18, 2025



Text-to-video (T2V) diffusion models have shown promising capabilities in synthesizing realistic videos from input text prompts. However, the input text description alone provides limited control over the precise objects movements and camera framing. In this work, we tackle the motion customization problem, where a reference video is provided as motion guidance. While most existing methods choose to fine-tune pre-trained diffusion models to reconstruct the frame differences of the reference video, we observe that such strategy suffer from content leakage from the reference video, and they cannot capture complex motion accurately. To address this issue, we propose MotionMatcher, a motion customization framework that fine-tunes the pre-trained T2V diffusion model at the feature level. Instead of using pixel-level objectives, MotionMatcher compares high-level, spatio-temporal motion features to fine-tune diffusion models, ensuring precise motion learning. For the sake of memory efficiency and accessibility, we utilize a pre-trained T2V diffusion model, which contains considerable prior knowledge about video motion, to compute these motion features. In our experiments, we demonstrate state-of-the-art motion customization performances, validating the design of our framework.
Select and Distill: Selective Dual-Teacher Knowledge Transfer for Continual Learning on Vision-Language Models
Mar 14, 2024Large-scale vision-language models (VLMs) have shown a strong zero-shot generalization capability on unseen-domain data. However, when adapting pre-trained VLMs to a sequence of downstream tasks, they are prone to forgetting previously learned knowledge and degrade their zero-shot classification capability. To tackle this problem, we propose a unique Selective Dual-Teacher Knowledge Transfer framework that leverages the most recent fine-tuned and the original pre-trained VLMs as dual teachers to preserve the previously learned knowledge and zero-shot capabilities, respectively. With only access to an unlabeled reference dataset, our proposed framework performs a selective knowledge distillation mechanism by measuring the feature discrepancy from the dual teacher VLMs. Consequently, our selective dual-teacher knowledge distillation would mitigate catastrophic forgetting of previously learned knowledge while preserving the zero-shot capabilities from pre-trained VLMs. Through extensive experiments on benchmark datasets, we show that our proposed framework is favorable against state-of-the-art continual learning approaches for preventing catastrophic forgetting and zero-shot degradation.
Receler: Reliable Concept Erasing of Text-to-Image Diffusion Models via Lightweight Erasers
Nov 29, 2023Concept erasure in text-to-image diffusion models aims to disable pre-trained diffusion models from generating images related to a target concept. To perform reliable concept erasure, the properties of robustness and locality are desirable. The former refrains the model from producing images associated with the target concept for any paraphrased or learned prompts, while the latter preserves the model ability in generating images for non-target concepts. In this paper, we propose Reliable Concept Erasing via Lightweight Erasers (Receler), which learns a lightweight Eraser to perform concept erasing and enhances locality and robustness with the proposed concept-localized regularization and adversarial prompt learning, respectively. Comprehensive quantitative and qualitative experiments with various concept prompts verify the superiority of Receler over the previous erasing methods on the above two desirable properties.