 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTA-Prompting: Enhancing Video Large Language Models for Dense Video Captioning via Temporal Anchors
Jan 06, 2026Dense video captioning aims to interpret and describe all temporally localized events throughout an input video. Recent state-of-the-art methods leverage large language models (LLMs) to provide detailed moment descriptions for video data. However, existing VideoLLMs remain challenging in identifying precise event boundaries in untrimmed videos, causing the generated captions to be not properly grounded. In this paper, we propose TA-Prompting, which enhances VideoLLMs via Temporal Anchors that learn to precisely localize events and prompt the VideoLLMs to perform temporal-aware video event understanding. During inference, in order to properly determine the output caption sequence from an arbitrary number of events presented within a video, we introduce an event coherent sampling strategy to select event captions with sufficient coherence across temporal events and cross-modal similarity with the given video. Through extensive experiments on benchmark datasets, we show that our TA-Prompting is favorable against state-of-the-art VideoLLMs, yielding superior performance on dense video captioning and temporal understanding tasks including moment retrieval and temporalQA.
* 8 pages for main paper (exclude citation pages), 6 pages for appendix, totally 10 figures 7 tables and 2 algorithms. The paper is accepted by WACV 2026
EMLoC: Emulator-based Memory-efficient Fine-tuning with LoRA Correction
Jun 13, 2025Open-source foundation models have seen rapid adoption and development, enabling powerful general-purpose capabilities across diverse domains. However, fine-tuning large foundation models for domain-specific or personalized tasks remains prohibitively expensive for most users due to the significant memory overhead beyond that of inference. We introduce EMLoC, an Emulator-based Memory-efficient fine-tuning framework with LoRA Correction, which enables model fine-tuning within the same memory budget required for inference. EMLoC constructs a task-specific light-weight emulator using activation-aware singular value decomposition (SVD) on a small downstream calibration set. Fine-tuning then is performed on this lightweight emulator via LoRA. To tackle the misalignment between the original model and the compressed emulator, we propose a novel compensation algorithm to correct the fine-tuned LoRA module, which thus can be merged into the original model for inference. EMLoC supports flexible compression ratios and standard training pipelines, making it adaptable to a wide range of applications. Extensive experiments demonstrate that EMLoC outperforms other baselines across multiple datasets and modalities. Moreover, without quantization, EMLoC enables fine-tuning of a 38B model on a single 24GB consumer GPU-bringing efficient and practical model adaptation to individual users.
VideoMage: Multi-Subject and Motion Customization of Text-to-Video Diffusion Models
Mar 27, 2025


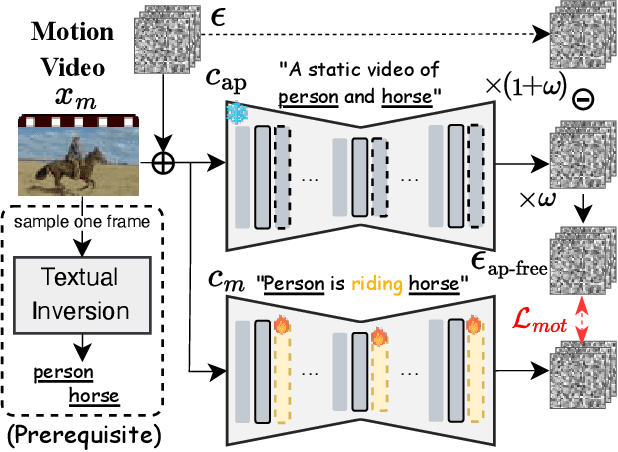
Customized text-to-video generation aims to produce high-quality videos that incorporate user-specified subject identities or motion patterns. However, existing methods mainly focus on personalizing a single concept, either subject identity or motion pattern, limiting their effectiveness for multiple subjects with the desired motion patterns. To tackle this challenge, we propose a unified framework VideoMage for video customization over both multiple subjects and their interactive motions. VideoMage employs subject and motion LoRAs to capture personalized content from user-provided images and videos, along with an appearance-agnostic motion learning approach to disentangle motion patterns from visual appearance. Furthermore, we develop a spatial-temporal composition scheme to guide interactions among subjects within the desired motion patterns. Extensive experiments demonstrate that VideoMage outperforms existing methods, generating coherent, user-controlled videos with consistent subject identities and interactions.
Select and Distill: Selective Dual-Teacher Knowledge Transfer for Continual Learning on Vision-Language Models
Mar 14, 2024Large-scale vision-language models (VLMs) have shown a strong zero-shot generalization capability on unseen-domain data. However, when adapting pre-trained VLMs to a sequence of downstream tasks, they are prone to forgetting previously learned knowledge and degrade their zero-shot classification capability. To tackle this problem, we propose a unique Selective Dual-Teacher Knowledge Transfer framework that leverages the most recent fine-tuned and the original pre-trained VLMs as dual teachers to preserve the previously learned knowledge and zero-shot capabilities, respectively. With only access to an unlabeled reference dataset, our proposed framework performs a selective knowledge distillation mechanism by measuring the feature discrepancy from the dual teacher VLMs. Consequently, our selective dual-teacher knowledge distillation would mitigate catastrophic forgetting of previously learned knowledge while preserving the zero-shot capabilities from pre-trained VLMs. Through extensive experiments on benchmark datasets, we show that our proposed framework is favorable against state-of-the-art continual learning approaches for preventing catastrophic forgetting and zero-shot degradation.
Receler: Reliable Concept Erasing of Text-to-Image Diffusion Models via Lightweight Erasers
Nov 29, 2023Concept erasure in text-to-image diffusion models aims to disable pre-trained diffusion models from generating images related to a target concept. To perform reliable concept erasure, the properties of robustness and locality are desirable. The former refrains the model from producing images associated with the target concept for any paraphrased or learned prompts, while the latter preserves the model ability in generating images for non-target concepts. In this paper, we propose Reliable Concept Erasing via Lightweight Erasers (Receler), which learns a lightweight Eraser to perform concept erasing and enhances locality and robustness with the proposed concept-localized regularization and adversarial prompt learning, respectively. Comprehensive quantitative and qualitative experiments with various concept prompts verify the superiority of Receler over the previous erasing methods on the above two desirable properties.
DCT: Dynamic Compressive Transformer for Modeling Unbounded Sequence
Oct 10, 2021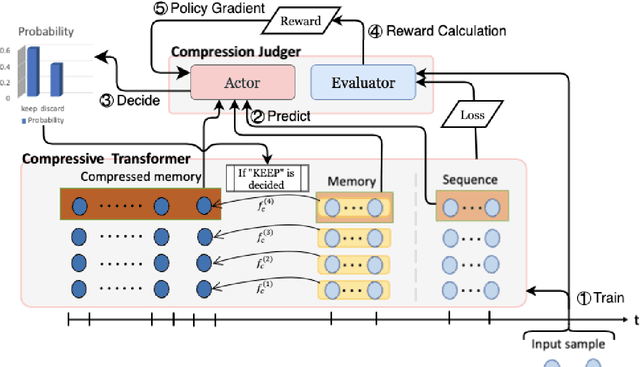

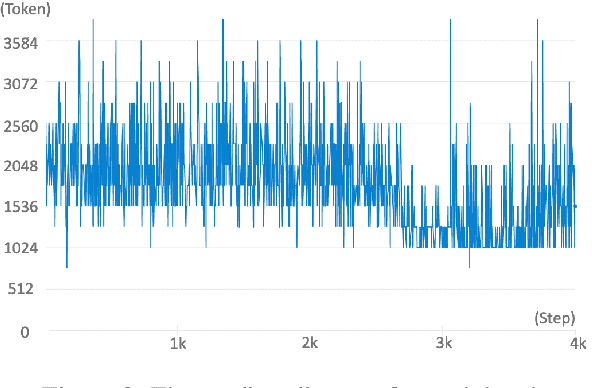
In this paper, we propose Dynamic Compressive Transformer (DCT), a transformer-based framework for modeling the unbounded sequence. In contrast to the previous baselines which append every sentence representation to memory, conditionally selecting and appending them is a more reasonable solution to deal with unlimited long sequences. Our model uses a policy that determines whether the sequence should be kept in memory with a compressed state or discarded during the training process. With the benefits of retaining semantically meaningful sentence information in the memory system, our experiment results on Enwik8 benchmark show that DCT outperforms the previous state-of-the-art (SOTA) model.