 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEMLoC: Emulator-based Memory-efficient Fine-tuning with LoRA Correction
Jun 13, 2025Open-source foundation models have seen rapid adoption and development, enabling powerful general-purpose capabilities across diverse domains. However, fine-tuning large foundation models for domain-specific or personalized tasks remains prohibitively expensive for most users due to the significant memory overhead beyond that of inference. We introduce EMLoC, an Emulator-based Memory-efficient fine-tuning framework with LoRA Correction, which enables model fine-tuning within the same memory budget required for inference. EMLoC constructs a task-specific light-weight emulator using activation-aware singular value decomposition (SVD) on a small downstream calibration set. Fine-tuning then is performed on this lightweight emulator via LoRA. To tackle the misalignment between the original model and the compressed emulator, we propose a novel compensation algorithm to correct the fine-tuned LoRA module, which thus can be merged into the original model for inference. EMLoC supports flexible compression ratios and standard training pipelines, making it adaptable to a wide range of applications. Extensive experiments demonstrate that EMLoC outperforms other baselines across multiple datasets and modalities. Moreover, without quantization, EMLoC enables fine-tuning of a 38B model on a single 24GB consumer GPU-bringing efficient and practical model adaptation to individual users.
Dynamic-SUPERB Phase-2: A Collaboratively Expanding Benchmark for Measuring the Capabilities of Spoken Language Models with 180 Tasks
Nov 08, 2024



Multimodal foundation models, such as Gemini and ChatGPT, have revolutionized human-machine interactions by seamlessly integrating various forms of data. Developing a universal spoken language model that comprehends a wide range of natural language instructions is critical for bridging communication gaps and facilitating more intuitive interactions. However, the absence of a comprehensive evaluation benchmark poses a significant challenge. We present Dynamic-SUPERB Phase-2, an open and evolving benchmark for the comprehensive evaluation of instruction-based universal speech models. Building upon the first generation, this second version incorporates 125 new tasks contributed collaboratively by the global research community, expanding the benchmark to a total of 180 tasks, making it the largest benchmark for speech and audio evaluation. While the first generation of Dynamic-SUPERB was limited to classification tasks, Dynamic-SUPERB Phase-2 broadens its evaluation capabilities by introducing a wide array of novel and diverse tasks, including regression and sequence generation, across speech, music, and environmental audio. Evaluation results indicate that none of the models performed well universally. SALMONN-13B excelled in English ASR, while WavLLM demonstrated high accuracy in emotion recognition, but current models still require further innovations to handle a broader range of tasks. We will soon open-source all task data and the evaluation pipeline.
Improving Speech Emotion Recognition in Under-Resourced Languages via Speech-to-Speech Translation with Bootstrapping Data Selection
Sep 17, 2024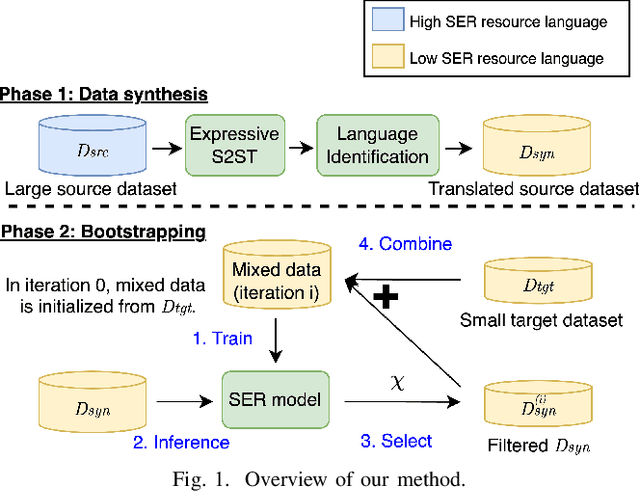
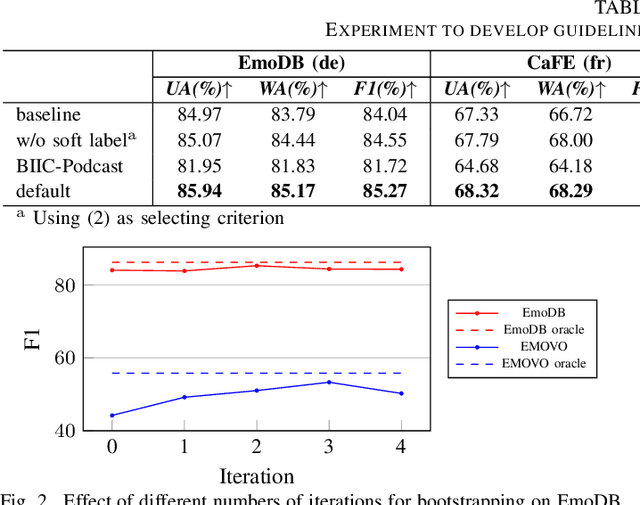


Speech Emotion Recognition (SER) is a crucial component in developing general-purpose AI agents capable of natural human-computer interaction. However, building robust multilingual SER systems remains challenging due to the scarcity of labeled data in languages other than English and Chinese. In this paper, we propose an approach to enhance SER performance in low SER resource languages by leveraging data from high-resource languages. Specifically, we employ expressive Speech-to-Speech translation (S2ST) combined with a novel bootstrapping data selection pipeline to generate labeled data in the target language. Extensive experiments demonstrate that our method is both effective and generalizable across different upstream models and languages. Our results suggest that this approach can facilitate the development of more scalable and robust multilingual SER systems.
ReXTime: A Benchmark Suite for Reasoning-Across-Time in Videos
Jun 27, 2024We introduce ReXTime, a benchmark designed to rigorously test AI models' ability to perform temporal reasoning within video events. Specifically, ReXTime focuses on reasoning across time, i.e. human-like understanding when the question and its corresponding answer occur in different video segments. This form of reasoning, requiring advanced understanding of cause-and-effect relationships across video segments, poses significant challenges to even the frontier multimodal large language models. To facilitate this evaluation, we develop an automated pipeline for generating temporal reasoning question-answer pairs, significantly reducing the need for labor-intensive manual annotations. Our benchmark includes 921 carefully vetted validation samples and 2,143 test samples, each manually curated for accuracy and relevance. Evaluation results show that while frontier large language models outperform academic models, they still lag behind human performance by a significant 14.3% accuracy gap. Additionally, our pipeline creates a training dataset of 9,695 machine generated samples without manual effort, which empirical studies suggest can enhance the across-time reasoning via fine-tuning.
On the social bias of speech self-supervised models
Jun 07, 2024
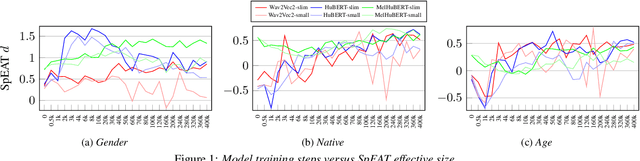

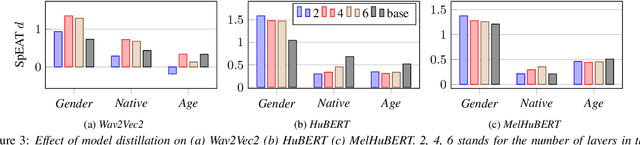
Self-supervised learning (SSL) speech models have achieved remarkable performance in various tasks, yet the biased outcomes, especially affecting marginalized groups, raise significant concerns. Social bias refers to the phenomenon where algorithms potentially amplify disparate properties between social groups present in the data used for training. Bias in SSL models can perpetuate injustice by automating discriminatory patterns and reinforcing inequitable systems. This work reveals that prevalent SSL models inadvertently acquire biased associations. We probe how various factors, such as model architecture, size, and training methodologies, influence the propagation of social bias within these models. Finally, we explore the efficacy of debiasing SSL models through regularization techniques, specifically via model compression. Our findings reveal that employing techniques such as row-pruning and training wider, shallower models can effectively mitigate social bias within SSL model.
QuAVF: Quality-aware Audio-Visual Fusion for Ego4D Talking to Me Challenge
Jun 30, 2023This technical report describes our QuAVF@NTU-NVIDIA submission to the Ego4D Talking to Me (TTM) Challenge 2023. Based on the observation from the TTM task and the provided dataset, we propose to use two separate models to process the input videos and audio. By doing so, we can utilize all the labeled training data, including those without bounding box labels. Furthermore, we leverage the face quality score from a facial landmark prediction model for filtering noisy face input data. The face quality score is also employed in our proposed quality-aware fusion for integrating the results from two branches. With the simple architecture design, our model achieves 67.4% mean average precision (mAP) on the test set, which ranks first on the leaderboard and outperforms the baseline method by a large margin. Code is available at: https://github.com/hsi-che-lin/Ego4D-QuAVF-TTM-CVPR23