 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaLTM: Adaptive Layer-wise Task Vector Merging for Categorical Speech Emotion Recognition with ASR Knowledge Integration
Mar 26, 2026Integrating Automatic Speech Recognition (ASR) into Speech Emotion Recognition (SER) enhances modeling by providing linguistic context. However, conventional feature fusion faces performance bottlenecks, and multi-task learning often suffers from optimization conflicts. While task vectors and model merging have addressed such conflicts in NLP and CV, their potential in speech tasks remains largely unexplored. In this work, we propose an Adaptive Layer-wise Task Vector Merging (AdaLTM) framework based on WavLM-Large. Instead of joint optimization, we extract task vectors from in-domain ASR and SER models fine-tuned on emotion datasets. These vectors are integrated into a frozen base model using layer-wise learnable coefficients. This strategy enables depth-aware balancing of linguistic and paralinguistic knowledge across transformer layers without gradient interference. Experiments on the MSP-Podcast demonstrate that the proposed approach effectively mitigates conflicts between ASR and SER.
TaigiSpeech: A Low-Resource Real-World Speech Intent Dataset and Preliminary Results with Scalable Data Mining In-the-Wild
Mar 23, 2026Speech technologies have advanced rapidly and serve diverse populations worldwide. However, many languages remain underrepresented due to limited resources. In this paper, we introduce \textbf{TaigiSpeech}, a real-world speech intent dataset in Taiwanese Taigi (aka Taiwanese Hokkien/Southern Min), which is a low-resource and primarily spoken language. The dataset is collected from older adults, comprising 21 speakers with a total of 3k utterances. It is designed for practical intent detection scenarios, including healthcare and home assistant applications. To address the scarcity of labeled data, we explore two data mining strategies with two levels of supervision: keyword match data mining with LLM pseudo labeling via an intermediate language and an audio-visual framework that leverages multimodal cues with minimal textual supervision. This design enables scalable dataset construction for low-resource and unwritten spoken languages. TaigiSpeech will be released under the CC BY 4.0 license to facilitate broad adoption and research on low-resource and unwritten languages. The project website and the dataset can be found on https://kwchang.org/taigispeech.
The Binding Effect: Analyzing How Multi-Dimensional Cues Form Gender Bias in Instruction TTS
Mar 21, 2026Current bias evaluations in Instruction Text-to-Speech (ITTS) often rely on univariate testing, overlooking the compositional structure of social cues. In this work, we investigate gender bias by modeling prompts as combinations of Social Status, Career stereotypes, and Persona descriptors. Analyzing open-source ITTS models, we uncover systematic interaction effects where social dimensions modulate one another, creating complex bias patterns missed by univariate baselines. Crucially, our findings indicate that these biases extend beyond surface-level artifacts, demonstrating strong associations with the semantic priors of pre-trained text encoders and the skewed distributions inherent in training data. We further demonstrate that generic diversity prompting is insufficient to override these entrenched patterns, underscoring the need for compositional analysis to diagnose latent risks in generative speech.
VoxEmo: Benchmarking Speech Emotion Recognition with Speech LLMs
Mar 09, 2026Speech Large Language Models (LLMs) show great promise for speech emotion recognition (SER) via generative interfaces. However, shifting from closed-set classification to open text generation introduces zero-shot stochasticity, making evaluation highly sensitive to prompts. Additionally, conventional speech LLMs benchmarks overlook the inherent ambiguity of human emotion. Hence, we present VoxEmo, a comprehensive SER benchmark encompassing 35 emotion corpora across 15 languages for Speech LLMs. VoxEmo provides a standardized toolkit featuring varying prompt complexities, from direct classification to paralinguistic reasoning. To reflect real-world perception/application, we introduce a distribution-aware soft-label protocol and a prompt-ensemble strategy that emulates annotator disagreement. Experiments reveal that while zero-shot speech LLMs trail supervised baselines in hard-label accuracy, they uniquely align with human subjective distributions.
Do You Hear What I Mean? Quantifying the Instruction-Perception Gap in Instruction-Guided Expressive Text-To-Speech Systems
Sep 18, 2025Instruction-guided text-to-speech (ITTS) enables users to control speech generation through natural language prompts, offering a more intuitive interface than traditional TTS. However, the alignment between user style instructions and listener perception remains largely unexplored. This work first presents a perceptual analysis of ITTS controllability across two expressive dimensions (adverbs of degree and graded emotion intensity) and collects human ratings on speaker age and word-level emphasis attributes. To comprehensively reveal the instruction-perception gap, we provide a data collection with large-scale human evaluations, named Expressive VOice Control (E-VOC) corpus. Furthermore, we reveal that (1) gpt-4o-mini-tts is the most reliable ITTS model with great alignment between instruction and generated utterances across acoustic dimensions. (2) The 5 analyzed ITTS systems tend to generate Adult voices even when the instructions ask to use child or Elderly voices. (3) Fine-grained control remains a major challenge, indicating that most ITTS systems have substantial room for improvement in interpreting slightly different attribute instructions.
EMO-Reasoning: Benchmarking Emotional Reasoning Capabilities in Spoken Dialogue Systems
Aug 25, 2025Speech emotions play a crucial role in human-computer interaction, shaping engagement and context-aware communication. Despite recent advances in spoken dialogue systems, a holistic system for evaluating emotional reasoning is still lacking. To address this, we introduce EMO-Reasoning, a benchmark for assessing emotional coherence in dialogue systems. It leverages a curated dataset generated via text-to-speech to simulate diverse emotional states, overcoming the scarcity of emotional speech data. We further propose the Cross-turn Emotion Reasoning Score to assess the emotion transitions in multi-turn dialogues. Evaluating seven dialogue systems through continuous, categorical, and perceptual metrics, we show that our framework effectively detects emotional inconsistencies, providing insights for improving current dialogue systems. By releasing a systematic evaluation benchmark, we aim to advance emotion-aware spoken dialogue modeling toward more natural and adaptive interactions.
DeSTA2.5-Audio: Toward General-Purpose Large Audio Language Model with Self-Generated Cross-Modal Alignment
Jul 03, 2025
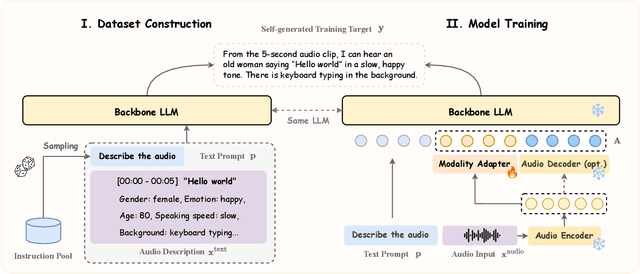


We introduce DeSTA2.5-Audio, a general-purpose Large Audio Language Model (LALM) designed for robust auditory perception and instruction-following, without requiring task-specific audio instruction-tuning. Recent LALMs typically augment Large Language Models (LLMs) with auditory capabilities by training on large-scale, manually curated or LLM-synthesized audio-instruction datasets. However, these approaches have often suffered from the catastrophic forgetting of the LLM's original language abilities. To address this, we revisit the data construction pipeline and propose DeSTA, a self-generated cross-modal alignment strategy in which the backbone LLM generates its own training targets. This approach preserves the LLM's native language proficiency while establishing effective audio-text alignment, thereby enabling zero-shot generalization without task-specific tuning. Using DeSTA, we construct DeSTA-AQA5M, a large-scale, task-agnostic dataset containing 5 million training samples derived from 7,000 hours of audio spanning 50 diverse datasets, including speech, environmental sounds, and music. DeSTA2.5-Audio achieves state-of-the-art or competitive performance across a wide range of audio-language benchmarks, including Dynamic-SUPERB, MMAU, SAKURA, Speech-IFEval, and VoiceBench. Comprehensive comparative studies demonstrate that our self-generated strategy outperforms widely adopted data construction and training strategies in both auditory perception and instruction-following capabilities. Our findings underscore the importance of carefully designed data construction in LALM development and offer practical insights for building robust, general-purpose LALMs.
CO-VADA: A Confidence-Oriented Voice Augmentation Debiasing Approach for Fair Speech Emotion Recognition
Jun 06, 2025Bias in speech emotion recognition (SER) systems often stems from spurious correlations between speaker characteristics and emotional labels, leading to unfair predictions across demographic groups. Many existing debiasing methods require model-specific changes or demographic annotations, limiting their practical use. We present CO-VADA, a Confidence-Oriented Voice Augmentation Debiasing Approach that mitigates bias without modifying model architecture or relying on demographic information. CO-VADA identifies training samples that reflect bias patterns present in the training data and then applies voice conversion to alter irrelevant attributes and generate samples. These augmented samples introduce speaker variations that differ from dominant patterns in the data, guiding the model to focus more on emotion-relevant features. Our framework is compatible with various SER models and voice conversion tools, making it a scalable and practical solution for improving fairness in SER systems.
EMO-Debias: Benchmarking Gender Debiasing Techniques in Multi-Label Speech Emotion Recognition
Jun 05, 2025Speech emotion recognition (SER) systems often exhibit gender bias. However, the effectiveness and robustness of existing debiasing methods in such multi-label scenarios remain underexplored. To address this gap, we present EMO-Debias, a large-scale comparison of 13 debiasing methods applied to multi-label SER. Our study encompasses techniques from pre-processing, regularization, adversarial learning, biased learners, and distributionally robust optimization. Experiments conducted on acted and naturalistic emotion datasets, using WavLM and XLSR representations, evaluate each method under conditions of gender imbalance. Our analysis quantifies the trade-offs between fairness and accuracy, identifying which approaches consistently reduce gender performance gaps without compromising overall model performance. The findings provide actionable insights for selecting effective debiasing strategies and highlight the impact of dataset distributions.
Meta-PerSER: Few-Shot Listener Personalized Speech Emotion Recognition via Meta-learning
May 22, 2025This paper introduces Meta-PerSER, a novel meta-learning framework that personalizes Speech Emotion Recognition (SER) by adapting to each listener's unique way of interpreting emotion. Conventional SER systems rely on aggregated annotations, which often overlook individual subtleties and lead to inconsistent predictions. In contrast, Meta-PerSER leverages a Model-Agnostic Meta-Learning (MAML) approach enhanced with Combined-Set Meta-Training, Derivative Annealing, and per-layer per-step learning rates, enabling rapid adaptation with only a few labeled examples. By integrating robust representations from pre-trained self-supervised models, our framework first captures general emotional cues and then fine-tunes itself to personal annotation styles. Experiments on the IEMOCAP corpus demonstrate that Meta-PerSER significantly outperforms baseline methods in both seen and unseen data scenarios, highlighting its promise for personalized emotion recognition.