 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRRP-Voice: A Longitudinal Dataset and Benchmark for Recurrent Respiratory Papillomatosis Detection
Jun 01, 2026Deep learning has advanced pathological voice detection rapidly, yet rare laryngeal diseases remain underexplored due to data scarcity. Recurrent Respiratory Papillomatosis (RRP) exemplifies this gap: an HPV-induced disease of the larynx in which patients oscillate between recurrence and post-surgical remission over the years. RRP demands continuous voice monitoring that existing cross-sectional corpora cannot support. We introduce the first longitudinal voice dataset for RRP, comprising recordings from 26 patients with up to ten years of follow-up. Each session pairs sustained vowels with sentence-level utterances, which are annotated by otolaryngologists and confirmed synchronously with laryngoscopy. Building on this resource, we establish a systematic benchmark spanning handcrafted features, end-to-end deep networks, self-supervised pretrained models, and recent audio large language models, all evaluated under session-level cross-validation with patient-level audit. Per-subject longitudinal analyses further confirm that the cross-sectional discriminative signal reflects laryngoscopic disease state rather than stable speaker attributes. This work lays a foundation for rare longitudinal pathological voice tasks in low-resource clinical settings.
TaigiSpeech: A Low-Resource Real-World Speech Intent Dataset and Preliminary Results with Scalable Data Mining In-the-Wild
Mar 23, 2026Speech technologies have advanced rapidly and serve diverse populations worldwide. However, many languages remain underrepresented due to limited resources. In this paper, we introduce \textbf{TaigiSpeech}, a real-world speech intent dataset in Taiwanese Taigi (aka Taiwanese Hokkien/Southern Min), which is a low-resource and primarily spoken language. The dataset is collected from older adults, comprising 21 speakers with a total of 3k utterances. It is designed for practical intent detection scenarios, including healthcare and home assistant applications. To address the scarcity of labeled data, we explore two data mining strategies with two levels of supervision: keyword match data mining with LLM pseudo labeling via an intermediate language and an audio-visual framework that leverages multimodal cues with minimal textual supervision. This design enables scalable dataset construction for low-resource and unwritten spoken languages. TaigiSpeech will be released under the CC BY 4.0 license to facilitate broad adoption and research on low-resource and unwritten languages. The project website and the dataset can be found on https://kwchang.org/taigispeech.
How Auditory Knowledge in LLM Backbones Shapes Audio Language Models: A Holistic Evaluation
Mar 19, 2026Large language models (LLMs) have been widely used as knowledge backbones of Large Audio Language Models (LALMs), yet how much auditory knowledge they encode through text-only pre-training and how this affects downstream performance remains unclear. We study this gap by comparing different LLMs under two text-only and one audio-grounded setting: (1) direct probing on AKB-2000, a curated benchmark testing the breadth and depth of auditory knowledge; (2) cascade evaluation, where LLMs reason over text descriptions from an audio captioner; and (3) audio-grounded evaluation, where each LLM is fine-tuned into a Large Audio Language Model (LALM) with an audio encoder. Our findings reveal that auditory knowledge varies substantially across families, and text-only results are strongly correlated with audio performance. Our work provides empirical grounding for a comprehensive understanding of LLMs in audio research.
MOS-Bias: From Hidden Gender Bias to Gender-Aware Speech Quality Assessment
Mar 11, 2026The Mean Opinion Score (MOS) serves as the standard metric for speech quality assessment, yet biases in human annotations remain underexplored. We conduct the first systematic analysis of gender bias in MOS, revealing that male listeners consistently assign higher scores than female listeners--a gap that is most pronounced in low-quality speech and gradually diminishes as quality improves. This quality-dependent structure proves difficult to eliminate through simple calibration. We further demonstrate that automated MOS models trained on aggregated labels exhibit predictions skewed toward male standards of perception. To address this, we propose a gender-aware model that learns gender-specific scoring patterns through abstracting binary group embeddings, thereby improving overall and gender-specific prediction accuracy. This study establishes that gender bias in MOS constitutes a systematic, learnable pattern demanding attention in equitable speech evaluation.
DeSTA2.5-Audio: Toward General-Purpose Large Audio Language Model with Self-Generated Cross-Modal Alignment
Jul 03, 2025
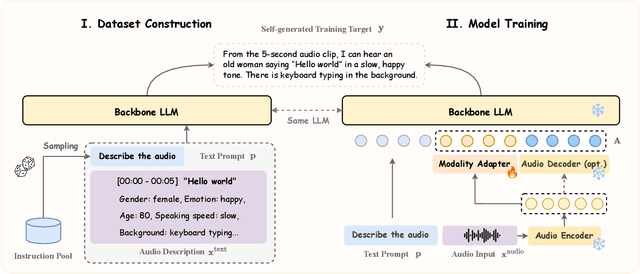


We introduce DeSTA2.5-Audio, a general-purpose Large Audio Language Model (LALM) designed for robust auditory perception and instruction-following, without requiring task-specific audio instruction-tuning. Recent LALMs typically augment Large Language Models (LLMs) with auditory capabilities by training on large-scale, manually curated or LLM-synthesized audio-instruction datasets. However, these approaches have often suffered from the catastrophic forgetting of the LLM's original language abilities. To address this, we revisit the data construction pipeline and propose DeSTA, a self-generated cross-modal alignment strategy in which the backbone LLM generates its own training targets. This approach preserves the LLM's native language proficiency while establishing effective audio-text alignment, thereby enabling zero-shot generalization without task-specific tuning. Using DeSTA, we construct DeSTA-AQA5M, a large-scale, task-agnostic dataset containing 5 million training samples derived from 7,000 hours of audio spanning 50 diverse datasets, including speech, environmental sounds, and music. DeSTA2.5-Audio achieves state-of-the-art or competitive performance across a wide range of audio-language benchmarks, including Dynamic-SUPERB, MMAU, SAKURA, Speech-IFEval, and VoiceBench. Comprehensive comparative studies demonstrate that our self-generated strategy outperforms widely adopted data construction and training strategies in both auditory perception and instruction-following capabilities. Our findings underscore the importance of carefully designed data construction in LALM development and offer practical insights for building robust, general-purpose LALMs.
ToxicTone: A Mandarin Audio Dataset Annotated for Toxicity and Toxic Utterance Tonality
May 21, 2025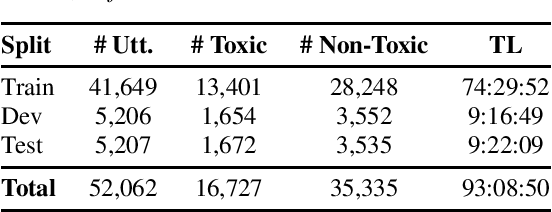
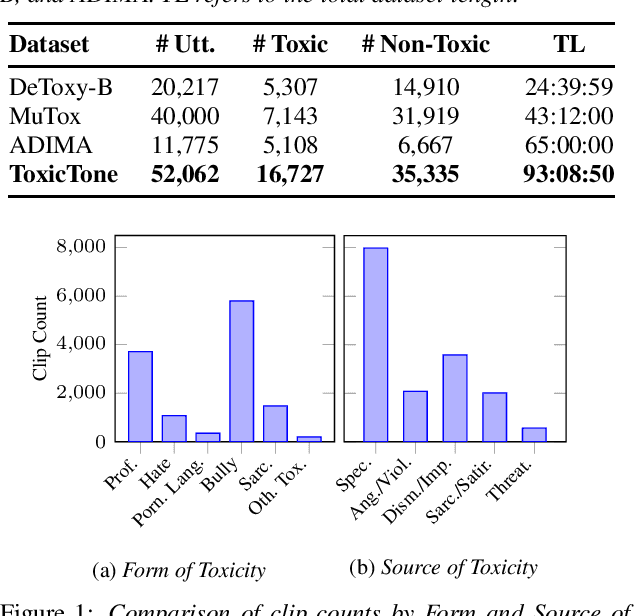
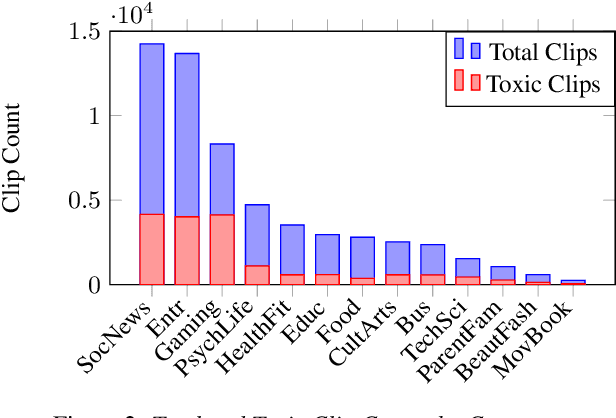
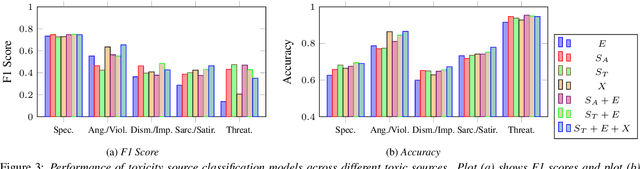
Despite extensive research on toxic speech detection in text, a critical gap remains in handling spoken Mandarin audio. The lack of annotated datasets that capture the unique prosodic cues and culturally specific expressions in Mandarin leaves spoken toxicity underexplored. To address this, we introduce ToxicTone -- the largest public dataset of its kind -- featuring detailed annotations that distinguish both forms of toxicity (e.g., profanity, bullying) and sources of toxicity (e.g., anger, sarcasm, dismissiveness). Our data, sourced from diverse real-world audio and organized into 13 topical categories, mirrors authentic communication scenarios. We also propose a multimodal detection framework that integrates acoustic, linguistic, and emotional features using state-of-the-art speech and emotion encoders. Extensive experiments show our approach outperforms text-only and baseline models, underscoring the essential role of speech-specific cues in revealing hidden toxic expressions.
CodecFake-Omni: A Large-Scale Codec-based Deepfake Speech Dataset
Jan 14, 2025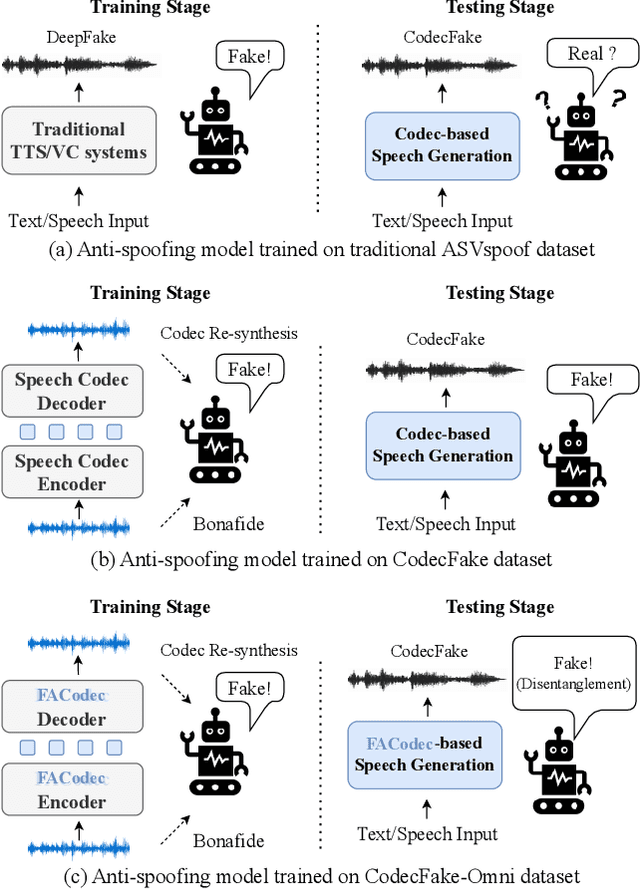
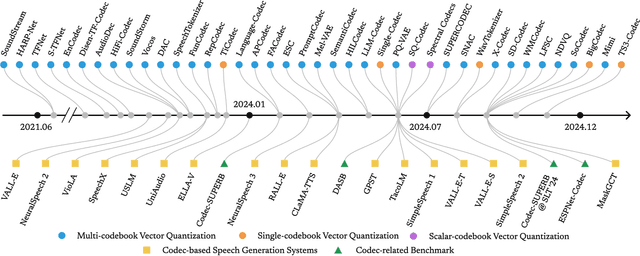

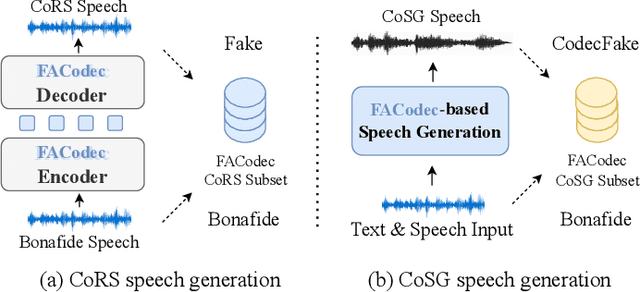
With the rapid advancement of codec-based speech generation (CoSG) systems, creating fake speech that mimics an individual's identity and spreads misinformation has become remarkably easy. Addressing the risks posed by such deepfake speech has attracted significant attention. However, most existing studies focus on detecting fake data generated by traditional speech generation models. Research on detecting fake speech generated by CoSG systems remains limited and largely unexplored. In this paper, we introduce CodecFake-Omni, a large-scale dataset specifically designed to advance the study of neural codec-based deepfake speech (CodecFake) detection and promote progress within the anti-spoofing community. To the best of our knowledge, CodecFake-Omni is the largest dataset of its kind till writing this paper, encompassing the most diverse range of codec architectures. The training set is generated through re-synthesis using nearly all publicly available open-source 31 neural audio codec models across 21 different codec families (one codec family with different configurations will result in multiple different codec models). The evaluation set includes web-sourced data collected from websites generated by 17 advanced CoSG models with eight codec families. Using this large-scale dataset, we reaffirm our previous findings that anti-spoofing models trained on traditional spoofing datasets generated by vocoders struggle to detect synthesized speech from current CoSG systems. Additionally, we propose a comprehensive neural audio codec taxonomy, categorizing neural audio codecs by their root components: vector quantizer, auxiliary objectives, and decoder types, with detailed explanations and representative examples for each. Using this comprehensive taxonomy, we conduct stratified analysis to provide valuable insights for future CodecFake detection research.
MC-SEMamba: A Simple Multi-channel Extension of SEMamba
Sep 26, 2024



Transformer-based models have become increasingly popular and have impacted speech-processing research owing to their exceptional performance in sequence modeling. Recently, a promising model architecture, Mamba, has emerged as a potential alternative to transformer-based models because of its efficient modeling of long sequences. In particular, models like SEMamba have demonstrated the effectiveness of the Mamba architecture in single-channel speech enhancement. This paper aims to adapt SEMamba for multi-channel applications with only a small increase in parameters. The resulting system, MC-SEMamba, achieved results on the CHiME3 dataset that were comparable or even superior to several previous baseline models. Additionally, we found that increasing the number of microphones from 1 to 6 improved the speech enhancement performance of MC-SEMamba.
Robust Audio-Visual Speech Enhancement: Correcting Misassignments in Complex Environments with Advanced Post-Processing
Sep 22, 2024



This paper addresses the prevalent issue of incorrect speech output in audio-visual speech enhancement (AVSE) systems, which is often caused by poor video quality and mismatched training and test data. We introduce a post-processing classifier (PPC) to rectify these erroneous outputs, ensuring that the enhanced speech corresponds accurately to the intended speaker. We also adopt a mixup strategy in PPC training to improve its robustness. Experimental results on the AVSE-challenge dataset show that integrating PPC into the AVSE model can significantly improve AVSE performance, and combining PPC with the AVSE model trained with permutation invariant training (PIT) yields the best performance. The proposed method substantially outperforms the baseline model by a large margin. This work highlights the potential for broader applications across various modalities and architectures, providing a promising direction for future research in this field.
Leveraging Joint Spectral and Spatial Learning with MAMBA for Multichannel Speech Enhancement
Sep 16, 2024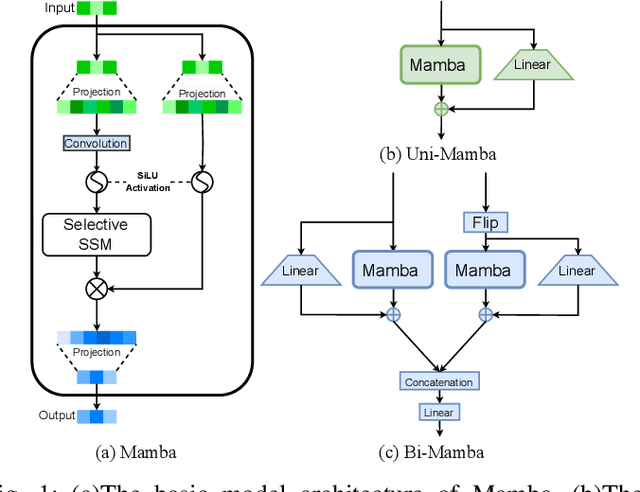
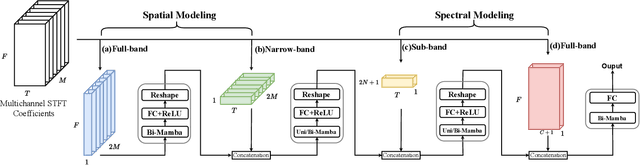
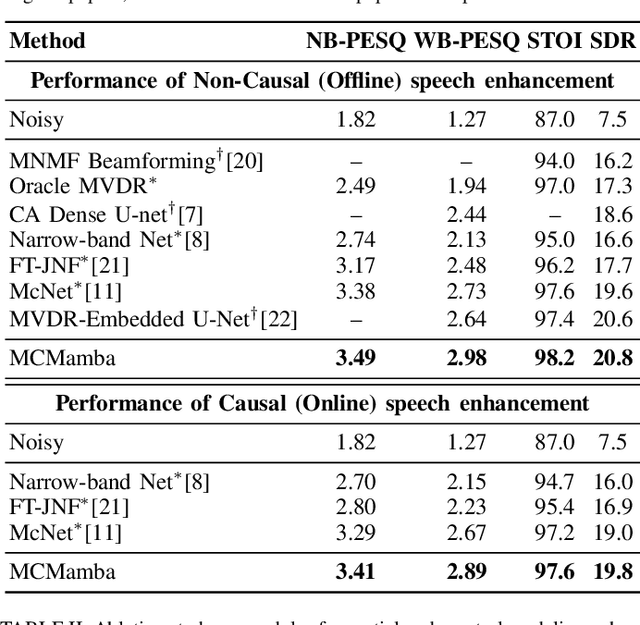
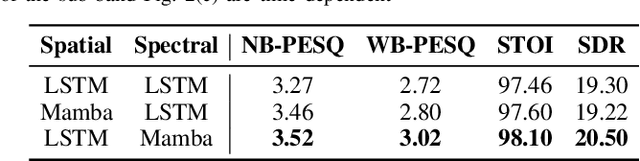
In multichannel speech enhancement, effectively capturing spatial and spectral information across different microphones is crucial for noise reduction. Traditional methods, such as CNN or LSTM, attempt to model the temporal dynamics of full-band and sub-band spectral and spatial features. However, these approaches face limitations in fully modeling complex temporal dependencies, especially in dynamic acoustic environments. To overcome these challenges, we modify the current advanced model McNet by introducing an improved version of Mamba, a state-space model, and further propose MCMamba. MCMamba has been completely reengineered to integrate full-band and narrow-band spatial information with sub-band and full-band spectral features, providing a more comprehensive approach to modeling spatial and spectral information. Our experimental results demonstrate that MCMamba significantly improves the modeling of spatial and spectral features in multichannel speech enhancement, outperforming McNet and achieving state-of-the-art performance on the CHiME-3 dataset. Additionally, we find that Mamba performs exceptionally well in modeling spectral information.