 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMC-SEMamba: A Simple Multi-channel Extension of SEMamba
Sep 26, 2024



Transformer-based models have become increasingly popular and have impacted speech-processing research owing to their exceptional performance in sequence modeling. Recently, a promising model architecture, Mamba, has emerged as a potential alternative to transformer-based models because of its efficient modeling of long sequences. In particular, models like SEMamba have demonstrated the effectiveness of the Mamba architecture in single-channel speech enhancement. This paper aims to adapt SEMamba for multi-channel applications with only a small increase in parameters. The resulting system, MC-SEMamba, achieved results on the CHiME3 dataset that were comparable or even superior to several previous baseline models. Additionally, we found that increasing the number of microphones from 1 to 6 improved the speech enhancement performance of MC-SEMamba.
Leveraging Joint Spectral and Spatial Learning with MAMBA for Multichannel Speech Enhancement
Sep 16, 2024
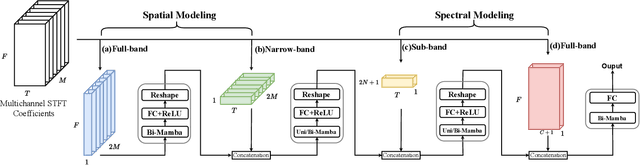
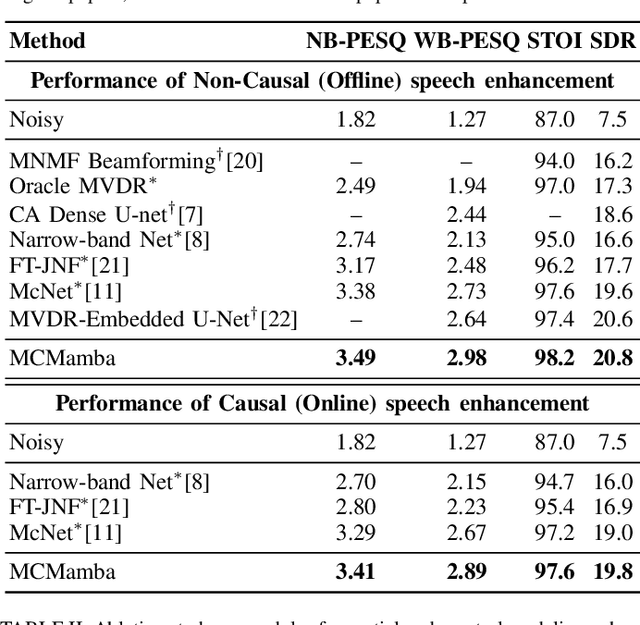
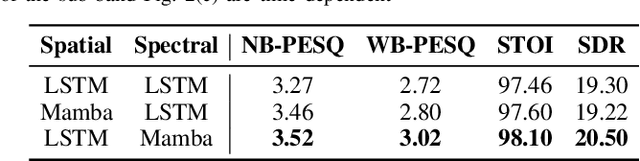
In multichannel speech enhancement, effectively capturing spatial and spectral information across different microphones is crucial for noise reduction. Traditional methods, such as CNN or LSTM, attempt to model the temporal dynamics of full-band and sub-band spectral and spatial features. However, these approaches face limitations in fully modeling complex temporal dependencies, especially in dynamic acoustic environments. To overcome these challenges, we modify the current advanced model McNet by introducing an improved version of Mamba, a state-space model, and further propose MCMamba. MCMamba has been completely reengineered to integrate full-band and narrow-band spatial information with sub-band and full-band spectral features, providing a more comprehensive approach to modeling spatial and spectral information. Our experimental results demonstrate that MCMamba significantly improves the modeling of spatial and spectral features in multichannel speech enhancement, outperforming McNet and achieving state-of-the-art performance on the CHiME-3 dataset. Additionally, we find that Mamba performs exceptionally well in modeling spectral information.
IANS: Intelligibility-aware Null-steering Beamforming for Dual-Microphone Arrays
Jul 09, 2023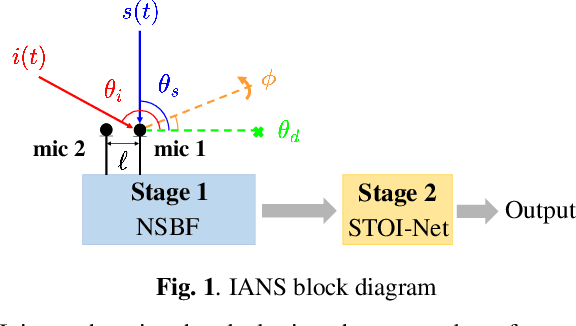
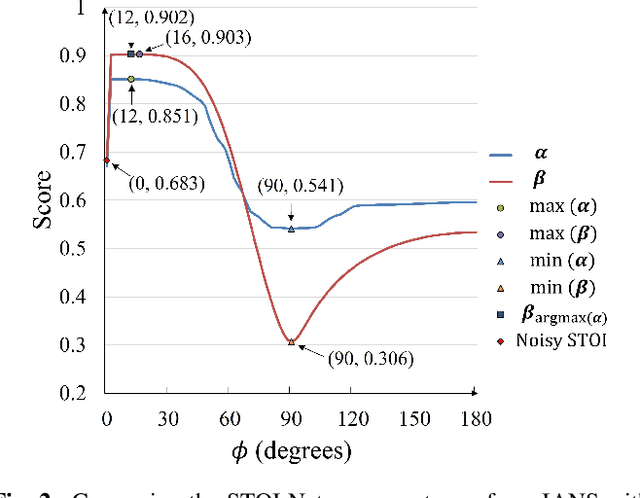
Beamforming techniques are popular in speech-related applications due to their effective spatial filtering capabilities. Nonetheless, conventional beamforming techniques generally depend heavily on either the target's direction-of-arrival (DOA), relative transfer function (RTF) or covariance matrix. This paper presents a new approach, the intelligibility-aware null-steering (IANS) beamforming framework, which uses the STOI-Net intelligibility prediction model to improve speech intelligibility without prior knowledge of the speech signal parameters mentioned earlier. The IANS framework combines a null-steering beamformer (NSBF) to generate a set of beamformed outputs, and STOI-Net, to determine the optimal result. Experimental results indicate that IANS can produce intelligibility-enhanced signals using a small dual-microphone array. The results are comparable to those obtained by null-steering beamformers with given knowledge of DOAs.
Speech Enhancement Based on Cyclegan with Noise-informed Training
Oct 19, 2021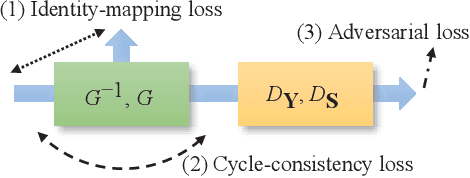
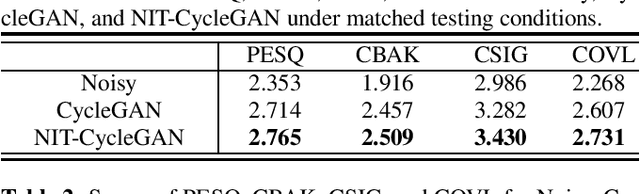
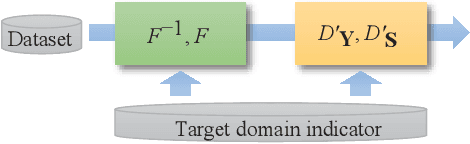
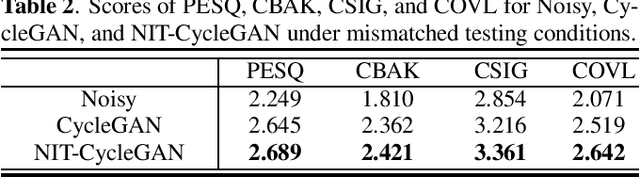
Speech enhancement (SE) approaches can be classified into supervised and unsupervised categories. For unsupervised SE, a well-known cycle-consistent generative adversarial network (CycleGAN) model, which comprises two generators and two discriminators, has been shown to provide a powerful nonlinear mapping ability and thus achieve a promising noise-suppression capability. However, a low-efficiency training process along with insufficient knowledge between noisy and clean speech may limit the enhancement performance of the CycleGAN SE at runtime. In this study, we propose a novel noise-informed-training CycleGAN approach that incorporates additional inputs into the generators and discriminators to assist the CycleGAN in learning a more accurate transformation of speech signals between the noise and clean domains. The additional input feature serves as an indicator that provides more information during the CycleGAN training stage. Experiment results confirm that the proposed approach can improve the CycleGAN SE model while achieving a better sound quality and fewer signal distortions.