 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Fullband-Subband Modeling for High-Resolution SingFake Detection
Apr 06, 2026Rapid advances in singing voice synthesis have increased unauthorized imitation risks, creating an urgent need for better Singing Voice Deepfake (SingFake) Detection, also known as SVDD. Unlike speech, singing contains complex pitch, wide dynamic range, and timbral variations. Conventional 16 kHz-sampled detectors prove inadequate, as they discard vital high-frequency information. This study presents the first systematic analysis of high-resolution (44.1 kHz sampling rate) audio for SVDD. We propose a joint fullband-subband modeling framework: the fullband captures global context, while subband-specific experts isolate fine-grained synthesis artifacts unevenly distributed across the spectrum. Experiments on the WildSVDD dataset demonstrate that high-frequency subbands provide essential complementary cues. Our framework significantly outperforms 16 kHz-sampled models, proving that high-resolution audio and strategic subband integration are critical for robust in-the-wild detection.
Training-Efficient Text-to-Music Generation with State-Space Modeling
Jan 21, 2026Recent advances in text-to-music generation (TTM) have yielded high-quality results, but often at the cost of extensive compute and the use of large proprietary internal data. To improve the affordability and openness of TTM training, an open-source generative model backbone that is more training- and data-efficient is needed. In this paper, we constrain the number of trainable parameters in the generative model to match that of the MusicGen-small benchmark (with about 300M parameters), and replace its Transformer backbone with the emerging class of state-space models (SSMs). Specifically, we explore different SSM variants for sequence modeling, and compare a single-stage SSM-based design with a decomposable two-stage SSM/diffusion hybrid design. All proposed models are trained from scratch on a purely public dataset comprising 457 hours of CC-licensed music, ensuring full openness. Our experimental findings are three-fold. First, we show that SSMs exhibit superior training efficiency compared to the Transformer counterpart. Second, despite using only 9% of the FLOPs and 2% of the training data size compared to the MusicGen-small benchmark, our model achieves competitive performance in both objective metrics and subjective listening tests based on MusicCaps captions. Finally, our scaling-down experiment demonstrates that SSMs can maintain competitive performance relative to the Transformer baseline even at the same training budget (measured in iterations), when the model size is reduced to four times smaller. To facilitate the democratization of TTM research, the processed captions, model checkpoints, and source code are available on GitHub via the project page: https://lonian6.github.io/ssmttm/.
How Does Instrumental Music Help SingFake Detection?
Sep 18, 2025Although many models exist to detect singing voice deepfakes (SingFake), how these models operate, particularly with instrumental accompaniment, is unclear. We investigate how instrumental music affects SingFake detection from two perspectives. To investigate the behavioral effect, we test different backbones, unpaired instrumental tracks, and frequency subbands. To analyze the representational effect, we probe how fine-tuning alters encoders' speech and music capabilities. Our results show that instrumental accompaniment acts mainly as data augmentation rather than providing intrinsic cues (e.g., rhythm or harmony). Furthermore, fine-tuning increases reliance on shallow speaker features while reducing sensitivity to content, paralinguistic, and semantic information. These insights clarify how models exploit vocal versus instrumental cues and can inform the design of more interpretable and robust SingFake detection systems.
Exploring State-Space-Model based Language Model in Music Generation
Jul 09, 2025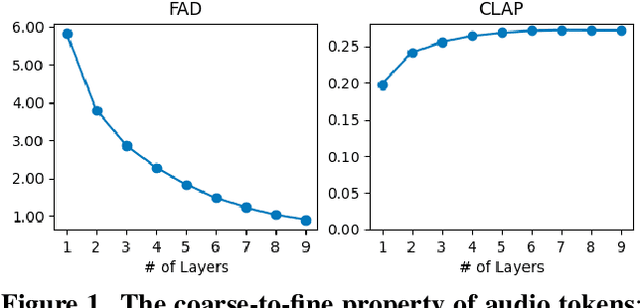
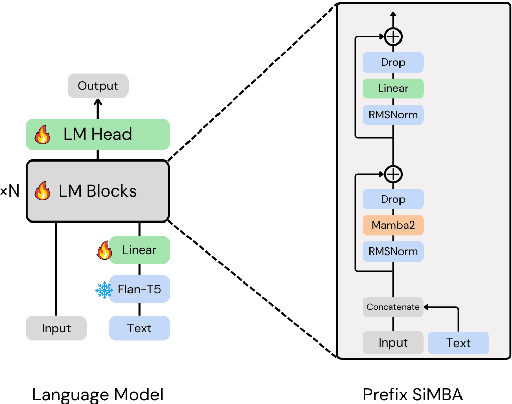
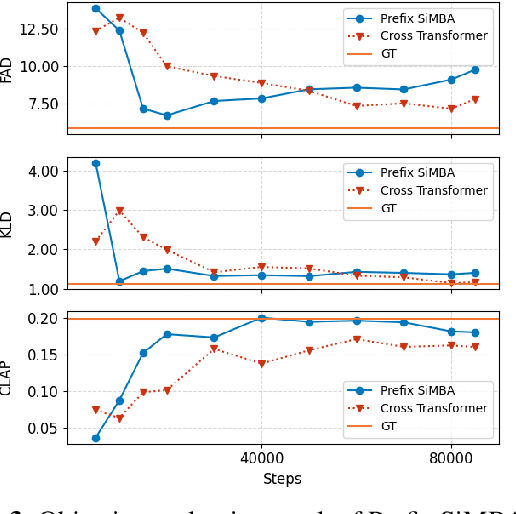
The recent surge in State Space Models (SSMs), particularly the emergence of Mamba, has established them as strong alternatives or complementary modules to Transformers across diverse domains. In this work, we aim to explore the potential of Mamba-based architectures for text-to-music generation. We adopt discrete tokens of Residual Vector Quantization (RVQ) as the modeling representation and empirically find that a single-layer codebook can capture semantic information in music. Motivated by this observation, we focus on modeling a single-codebook representation and adapt SiMBA, originally designed as a Mamba-based encoder, to function as a decoder for sequence modeling. We compare its performance against a standard Transformer-based decoder. Our results suggest that, under limited-resource settings, SiMBA achieves much faster convergence and generates outputs closer to the ground truth. This demonstrates the promise of SSMs for efficient and expressive text-to-music generation. We put audio examples on Github.
DeSTA2.5-Audio: Toward General-Purpose Large Audio Language Model with Self-Generated Cross-Modal Alignment
Jul 03, 2025
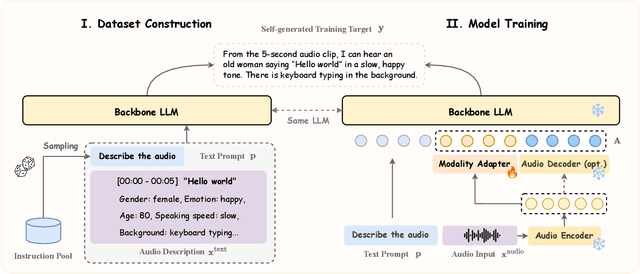


We introduce DeSTA2.5-Audio, a general-purpose Large Audio Language Model (LALM) designed for robust auditory perception and instruction-following, without requiring task-specific audio instruction-tuning. Recent LALMs typically augment Large Language Models (LLMs) with auditory capabilities by training on large-scale, manually curated or LLM-synthesized audio-instruction datasets. However, these approaches have often suffered from the catastrophic forgetting of the LLM's original language abilities. To address this, we revisit the data construction pipeline and propose DeSTA, a self-generated cross-modal alignment strategy in which the backbone LLM generates its own training targets. This approach preserves the LLM's native language proficiency while establishing effective audio-text alignment, thereby enabling zero-shot generalization without task-specific tuning. Using DeSTA, we construct DeSTA-AQA5M, a large-scale, task-agnostic dataset containing 5 million training samples derived from 7,000 hours of audio spanning 50 diverse datasets, including speech, environmental sounds, and music. DeSTA2.5-Audio achieves state-of-the-art or competitive performance across a wide range of audio-language benchmarks, including Dynamic-SUPERB, MMAU, SAKURA, Speech-IFEval, and VoiceBench. Comprehensive comparative studies demonstrate that our self-generated strategy outperforms widely adopted data construction and training strategies in both auditory perception and instruction-following capabilities. Our findings underscore the importance of carefully designed data construction in LALM development and offer practical insights for building robust, general-purpose LALMs.
Towards Generalized Source Tracing for Codec-Based Deepfake Speech
Jun 08, 2025Recent attempts at source tracing for codec-based deepfake speech (CodecFake), generated by neural audio codec-based speech generation (CoSG) models, have exhibited suboptimal performance. However, how to train source tracing models using simulated CoSG data while maintaining strong performance on real CoSG-generated audio remains an open challenge. In this paper, we show that models trained solely on codec-resynthesized data tend to overfit to non-speech regions and struggle to generalize to unseen content. To mitigate these challenges, we introduce the Semantic-Acoustic Source Tracing Network (SASTNet), which jointly leverages Whisper for semantic feature encoding and Wav2vec2 with AudioMAE for acoustic feature encoding. Our proposed SASTNet achieves state-of-the-art performance on the CoSG test set of the CodecFake+ dataset, demonstrating its effectiveness for reliable source tracing.
Codec-Based Deepfake Source Tracing via Neural Audio Codec Taxonomy
May 19, 2025



Recent advances in neural audio codec-based speech generation (CoSG) models have produced remarkably realistic audio deepfakes. We refer to deepfake speech generated by CoSG systems as codec-based deepfake, or CodecFake. Although existing anti-spoofing research on CodecFake predominantly focuses on verifying the authenticity of audio samples, almost no attention was given to tracing the CoSG used in generating these deepfakes. In CodecFake generation, processes such as speech-to-unit encoding, discrete unit modeling, and unit-to-speech decoding are fundamentally based on neural audio codecs. Motivated by this, we introduce source tracing for CodecFake via neural audio codec taxonomy, which dissects neural audio codecs to trace CoSG. Our experimental results on the CodecFake+ dataset provide promising initial evidence for the feasibility of CodecFake source tracing while also highlighting several challenges that warrant further investigation.
CodecFake-Omni: A Large-Scale Codec-based Deepfake Speech Dataset
Jan 14, 2025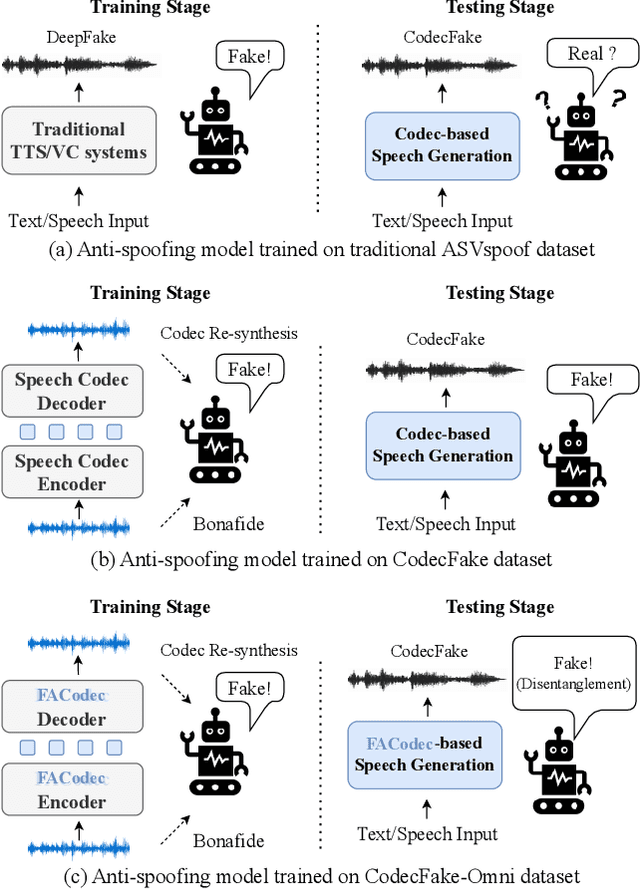
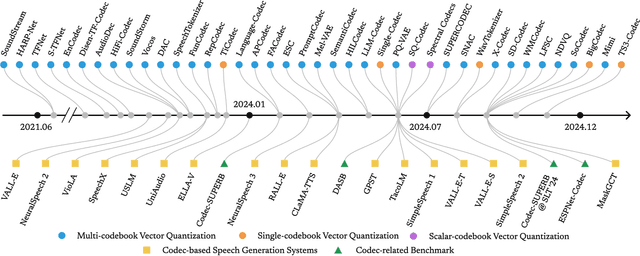

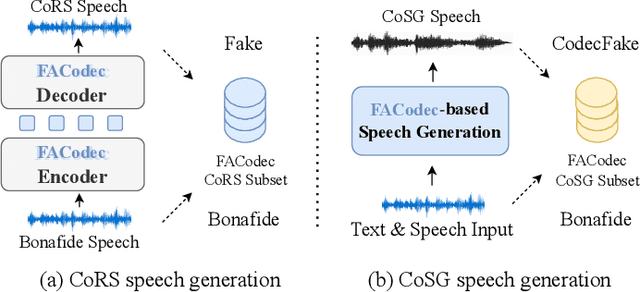
With the rapid advancement of codec-based speech generation (CoSG) systems, creating fake speech that mimics an individual's identity and spreads misinformation has become remarkably easy. Addressing the risks posed by such deepfake speech has attracted significant attention. However, most existing studies focus on detecting fake data generated by traditional speech generation models. Research on detecting fake speech generated by CoSG systems remains limited and largely unexplored. In this paper, we introduce CodecFake-Omni, a large-scale dataset specifically designed to advance the study of neural codec-based deepfake speech (CodecFake) detection and promote progress within the anti-spoofing community. To the best of our knowledge, CodecFake-Omni is the largest dataset of its kind till writing this paper, encompassing the most diverse range of codec architectures. The training set is generated through re-synthesis using nearly all publicly available open-source 31 neural audio codec models across 21 different codec families (one codec family with different configurations will result in multiple different codec models). The evaluation set includes web-sourced data collected from websites generated by 17 advanced CoSG models with eight codec families. Using this large-scale dataset, we reaffirm our previous findings that anti-spoofing models trained on traditional spoofing datasets generated by vocoders struggle to detect synthesized speech from current CoSG systems. Additionally, we propose a comprehensive neural audio codec taxonomy, categorizing neural audio codecs by their root components: vector quantizer, auxiliary objectives, and decoder types, with detailed explanations and representative examples for each. Using this comprehensive taxonomy, we conduct stratified analysis to provide valuable insights for future CodecFake detection research.
Building a Taiwanese Mandarin Spoken Language Model: A First Attempt
Nov 11, 2024



This technical report presents our initial attempt to build a spoken large language model (LLM) for Taiwanese Mandarin, specifically tailored to enable real-time, speech-to-speech interaction in multi-turn conversations. Our end-to-end model incorporates a decoder-only transformer architecture and aims to achieve seamless interaction while preserving the conversational flow, including full-duplex capabilities allowing simultaneous speaking and listening. The paper also details the training process, including data preparation with synthesized dialogues and adjustments for real-time interaction. We also developed a platform to evaluate conversational fluency and response coherence in multi-turn dialogues. We hope the release of the report can contribute to the future development of spoken LLMs in Taiwanese Mandarin.
Dynamic-SUPERB Phase-2: A Collaboratively Expanding Benchmark for Measuring the Capabilities of Spoken Language Models with 180 Tasks
Nov 08, 2024



Multimodal foundation models, such as Gemini and ChatGPT, have revolutionized human-machine interactions by seamlessly integrating various forms of data. Developing a universal spoken language model that comprehends a wide range of natural language instructions is critical for bridging communication gaps and facilitating more intuitive interactions. However, the absence of a comprehensive evaluation benchmark poses a significant challenge. We present Dynamic-SUPERB Phase-2, an open and evolving benchmark for the comprehensive evaluation of instruction-based universal speech models. Building upon the first generation, this second version incorporates 125 new tasks contributed collaboratively by the global research community, expanding the benchmark to a total of 180 tasks, making it the largest benchmark for speech and audio evaluation. While the first generation of Dynamic-SUPERB was limited to classification tasks, Dynamic-SUPERB Phase-2 broadens its evaluation capabilities by introducing a wide array of novel and diverse tasks, including regression and sequence generation, across speech, music, and environmental audio. Evaluation results indicate that none of the models performed well universally. SALMONN-13B excelled in English ASR, while WavLLM demonstrated high accuracy in emotion recognition, but current models still require further innovations to handle a broader range of tasks. We will soon open-source all task data and the evaluation pipeline.