 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTracking Listener Attention: Gaze-Guided Audio-Visual Speech Enhancement Framework
Apr 09, 2026This paper presents a Gaze-Guided Audio-Visual Speech Enhancement (GG-AVSE) framework to address the cocktail party problem. A major challenge in conventional AVSE is identifying the listener's intended speaker in multi-talker environments. GG-AVSE addresses this issue by exploiting gaze direction as a supervisory cue for target-speaker selection. Specifically, we propose the GG-VM module, which combines gaze signals with a YOLO5Face detector to extract the target speaker's facial features and integrates them with the pretrained AVSEMamba model through two strategies: zero-shot merging and partial visual fine-tuning. For evaluation, we introduce the AVSEC2-Gaze dataset. Experimental results show that GG-AVSE achieves substantial performance gains over gaze-free baselines: a 10.08% improvement in PESQ (2.370 to 2.609), a 5.18% improvement in STOI (0.8802 to 0.9258), and a 23.69% improvement in SI-SDR (9.16 to 11.33). These results confirm that gaze provides an effective cue for resolving target-speaker ambiguity and highlight the scalability of GG-AVSE for real-world applications.
Universal Speech Enhancement with Regression and Generative Mamba
May 27, 2025



The Interspeech 2025 URGENT Challenge aimed to advance universal, robust, and generalizable speech enhancement by unifying speech enhancement tasks across a wide variety of conditions, including seven different distortion types and five languages. We present Universal Speech Enhancement Mamba (USEMamba), a state-space speech enhancement model designed to handle long-range sequence modeling, time-frequency structured processing, and sampling frequency-independent feature extraction. Our approach primarily relies on regression-based modeling, which performs well across most distortions. However, for packet loss and bandwidth extension, where missing content must be inferred, a generative variant of the proposed USEMamba proves more effective. Despite being trained on only a subset of the full training data, USEMamba achieved 2nd place in Track 1 during the blind test phase, demonstrating strong generalization across diverse conditions.
MSEMG: Surface Electromyography Denoising with a Mamba-based Efficient Network
Nov 28, 2024



Surface electromyography (sEMG) recordings can be contaminated by electrocardiogram (ECG) signals when the monitored muscle is closed to the heart. Traditional signal-processing-based approaches, such as high-pass filtering and template subtraction, have been used to remove ECG interference but are often limited in their effectiveness. Recently, neural-network-based methods have shown greater promise for sEMG denoising, but they still struggle to balance both efficiency and effectiveness. In this study, we introduce MSEMG, a novel system that integrates the Mamba State Space Model with a convolutional neural network to serve as a lightweight sEMG denoising model. We evaluated MSEMG using sEMG data from the Non-Invasive Adaptive Prosthetics database and ECG signals from the MIT-BIH Normal Sinus Rhythm Database. The results show that MSEMG outperforms existing methods, generating higher-quality sEMG signals with fewer parameters. The source code for MSEMG is available at https://github.com/tonyliu0910/MSEMG.
MC-SEMamba: A Simple Multi-channel Extension of SEMamba
Sep 26, 2024



Transformer-based models have become increasingly popular and have impacted speech-processing research owing to their exceptional performance in sequence modeling. Recently, a promising model architecture, Mamba, has emerged as a potential alternative to transformer-based models because of its efficient modeling of long sequences. In particular, models like SEMamba have demonstrated the effectiveness of the Mamba architecture in single-channel speech enhancement. This paper aims to adapt SEMamba for multi-channel applications with only a small increase in parameters. The resulting system, MC-SEMamba, achieved results on the CHiME3 dataset that were comparable or even superior to several previous baseline models. Additionally, we found that increasing the number of microphones from 1 to 6 improved the speech enhancement performance of MC-SEMamba.
Leveraging Joint Spectral and Spatial Learning with MAMBA for Multichannel Speech Enhancement
Sep 16, 2024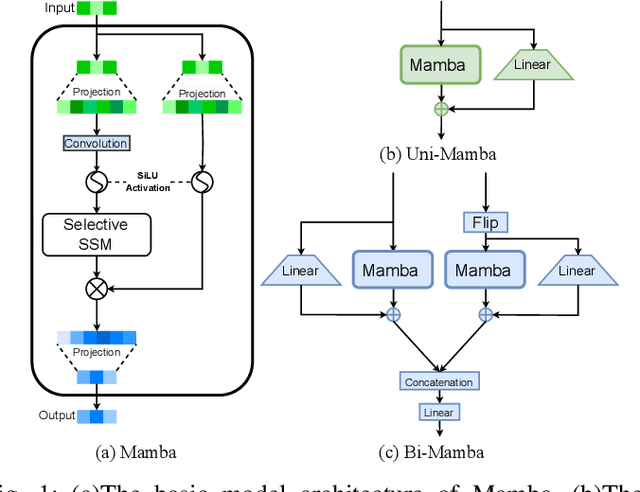
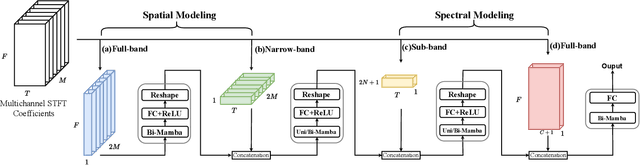
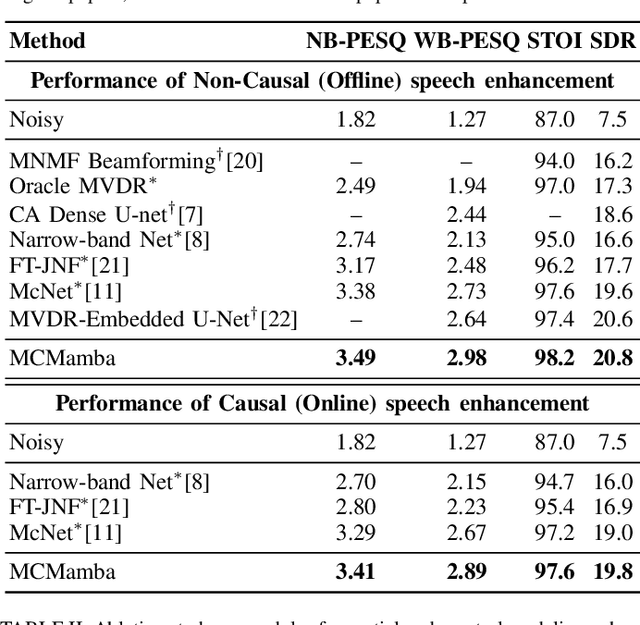
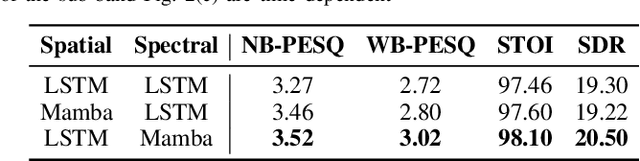
In multichannel speech enhancement, effectively capturing spatial and spectral information across different microphones is crucial for noise reduction. Traditional methods, such as CNN or LSTM, attempt to model the temporal dynamics of full-band and sub-band spectral and spatial features. However, these approaches face limitations in fully modeling complex temporal dependencies, especially in dynamic acoustic environments. To overcome these challenges, we modify the current advanced model McNet by introducing an improved version of Mamba, a state-space model, and further propose MCMamba. MCMamba has been completely reengineered to integrate full-band and narrow-band spatial information with sub-band and full-band spectral features, providing a more comprehensive approach to modeling spatial and spectral information. Our experimental results demonstrate that MCMamba significantly improves the modeling of spatial and spectral features in multichannel speech enhancement, outperforming McNet and achieving state-of-the-art performance on the CHiME-3 dataset. Additionally, we find that Mamba performs exceptionally well in modeling spectral information.
An Investigation of Incorporating Mamba for Speech Enhancement
May 10, 2024



This work aims to study a scalable state-space model (SSM), Mamba, for the speech enhancement (SE) task. We exploit a Mamba-based regression model to characterize speech signals and build an SE system upon Mamba, termed SEMamba. We explore the properties of Mamba by integrating it as the core model in both basic and advanced SE systems, along with utilizing signal-level distances as well as metric-oriented loss functions. SEMamba demonstrates promising results and attains a PESQ score of 3.55 on the VoiceBank-DEMAND dataset. When combined with the perceptual contrast stretching technique, the proposed SEMamba yields a new state-of-the-art PESQ score of 3.69.
ElectrodeNet -- A Deep Learning Based Sound Coding Strategy for Cochlear Implants
May 26, 2023



ElectrodeNet, a deep learning based sound coding strategy for the cochlear implant (CI), is proposed to emulate the advanced combination encoder (ACE) strategy by replacing the conventional envelope detection using various artificial neural networks. The extended ElectrodeNet-CS strategy further incorporates the channel selection (CS). Network models of deep neural network (DNN), convolutional neural network (CNN), and long short-term memory (LSTM) were trained using the Fast Fourier Transformed bins and channel envelopes obtained from the processing of clean speech by the ACE strategy. Objective speech understanding using short-time objective intelligibility (STOI) and normalized covariance metric (NCM) was estimated for ElectrodeNet using CI simulations. Sentence recognition tests for vocoded Mandarin speech were conducted with normal-hearing listeners. DNN, CNN, and LSTM based ElectrodeNets exhibited strong correlations to ACE in objective and subjective scores using mean squared error (MSE), linear correlation coefficient (LCC) and Spearman's rank correlation coefficient (SRCC). The ElectrodeNet-CS strategy was capable of producing N-of-M compatible electrode patterns using a modified DNN network to embed maxima selection, and to perform in similar or even slightly higher average in STOI and sentence recognition compared to ACE. The methods and findings demonstrated the feasibility and potential of using deep learning in CI coding strategy.
Perceptual Contrast Stretching on Target Feature for Speech Enhancement
Apr 01, 2022
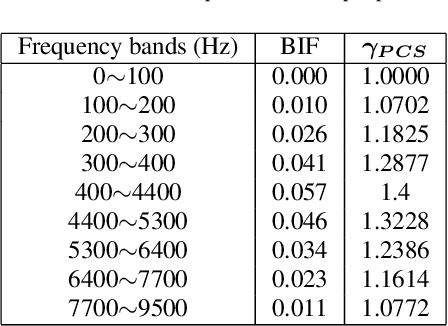
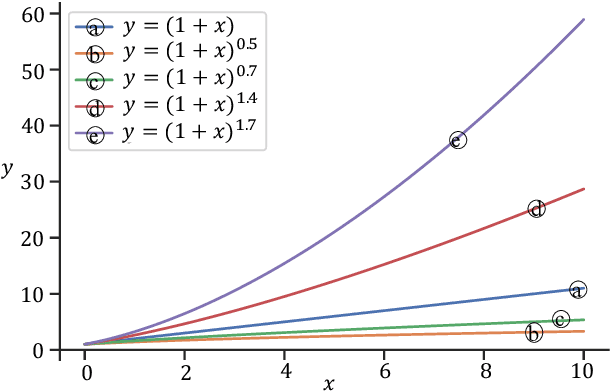
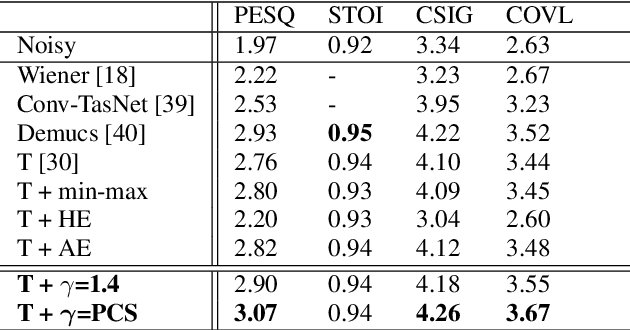
Speech enhancement (SE) performance has improved considerably since the use of deep learning (DL) models as a base function. In this study, we propose a perceptual contrast stretching (PCS) approach to further improve SE performance. PCS is derived based on the critical band importance function and applied to modify the targets of the SE model. Specifically, PCS stretches the contract of target features according to perceptual importance, thereby improving the overall SE performance. Compared to post-processing based implementations, incorporating PCS into the training phase preserves performance and reduces online computation. It is also worth noting that PCS can be suitably combined with different SE model architectures and training criteria. Meanwhile, PCS does not affect the causality or convergence of the SE model training. Experimental results on the VoiceBank-DEMAND dataset showed that the proposed method can achieve state-of-the-art performance on both causal (PESQ=3.07) and non-causal (PESQ=3.35) SE tasks.