 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum Super-resolution by Adaptive Non-local Observables
Jan 20, 2026Super-resolution (SR) seeks to reconstruct high-resolution (HR) data from low-resolution (LR) observations. Classical deep learning methods have advanced SR substantially, but require increasingly deeper networks, large datasets, and heavy computation to capture fine-grained correlations. In this work, we present the \emph{first study} to investigate quantum circuits for SR. We propose a framework based on Variational Quantum Circuits (VQCs) with \emph{Adaptive Non-Local Observable} (ANO) measurements. Unlike conventional VQCs with fixed Pauli readouts, ANO introduces trainable multi-qubit Hermitian observables, allowing the measurement process to adapt during training. This design leverages the high-dimensional Hilbert space of quantum systems and the representational structure provided by entanglement and superposition. Experiments demonstrate that ANO-VQCs achieve up to five-fold higher resolution with a relatively small model size, suggesting a promising new direction at the intersection of quantum machine learning and super-resolution.
Adaptive Non-local Observable on Quantum Neural Networks
Apr 18, 2025Conventional Variational Quantum Circuits (VQCs) for Quantum Machine Learning typically rely on a fixed Hermitian observable, often built from Pauli operators. Inspired by the Heisenberg picture, we propose an adaptive non-local measurement framework that substantially increases the model complexity of the quantum circuits. Our introduction of dynamical Hermitian observables with evolving parameters shows that optimizing VQC rotations corresponds to tracing a trajectory in the observable space. This viewpoint reveals that standard VQCs are merely a special case of the Heisenberg representation. Furthermore, we show that properly incorporating variational rotations with non-local observables enhances qubit interaction and information mixture, admitting flexible circuit designs. Two non-local measurement schemes are introduced, and numerical simulations on classification tasks confirm that our approach outperforms conventional VQCs, yielding a more powerful and resource-efficient approach as a Quantum Neural Network.
Linguistic Knowledge Transfer Learning for Speech Enhancement
Mar 10, 2025Linguistic knowledge plays a crucial role in spoken language comprehension. It provides essential semantic and syntactic context for speech perception in noisy environments. However, most speech enhancement (SE) methods predominantly rely on acoustic features to learn the mapping relationship between noisy and clean speech, with limited exploration of linguistic integration. While text-informed SE approaches have been investigated, they often require explicit speech-text alignment or externally provided textual data, constraining their practicality in real-world scenarios. Additionally, using text as input poses challenges in aligning linguistic and acoustic representations due to their inherent differences. In this study, we propose the Cross-Modality Knowledge Transfer (CMKT) learning framework, which leverages pre-trained large language models (LLMs) to infuse linguistic knowledge into SE models without requiring text input or LLMs during inference. Furthermore, we introduce a misalignment strategy to improve knowledge transfer. This strategy applies controlled temporal shifts, encouraging the model to learn more robust representations. Experimental evaluations demonstrate that CMKT consistently outperforms baseline models across various SE architectures and LLM embeddings, highlighting its adaptability to different configurations. Additionally, results on Mandarin and English datasets confirm its effectiveness across diverse linguistic conditions, further validating its robustness. Moreover, CMKT remains effective even in scenarios without textual data, underscoring its practicality for real-world applications. By bridging the gap between linguistic and acoustic modalities, CMKT offers a scalable and innovative solution for integrating linguistic knowledge into SE models, leading to substantial improvements in both intelligibility and enhancement performance.
Learning to Measure Quantum Neural Networks
Jan 10, 2025



The rapid progress in quantum computing (QC) and machine learning (ML) has attracted growing attention, prompting extensive research into quantum machine learning (QML) algorithms to solve diverse and complex problems. Designing high-performance QML models demands expert-level proficiency, which remains a significant obstacle to the broader adoption of QML. A few major hurdles include crafting effective data encoding techniques and parameterized quantum circuits, both of which are crucial to the performance of QML models. Additionally, the measurement phase is frequently overlooked-most current QML models rely on pre-defined measurement protocols that often fail to account for the specific problem being addressed. We introduce a novel approach that makes the observable of the quantum system-specifically, the Hermitian matrix-learnable. Our method features an end-to-end differentiable learning framework, where the parameterized observable is trained alongside the ordinary quantum circuit parameters simultaneously. Using numerical simulations, we show that the proposed method can identify observables for variational quantum circuits that lead to improved outcomes, such as higher classification accuracy, thereby boosting the overall performance of QML models.
Transfer Learning Analysis of Variational Quantum Circuits
Jan 02, 2025


This work analyzes transfer learning of the Variational Quantum Circuit (VQC). Our framework begins with a pretrained VQC configured in one domain and calculates the transition of 1-parameter unitary subgroups required for a new domain. A formalism is established to investigate the adaptability and capability of a VQC under the analysis of loss bounds. Our theory observes knowledge transfer in VQCs and provides a heuristic interpretation for the mechanism. An analytical fine-tuning method is derived to attain the optimal transition for adaptations of similar domains.
MC-SEMamba: A Simple Multi-channel Extension of SEMamba
Sep 26, 2024



Transformer-based models have become increasingly popular and have impacted speech-processing research owing to their exceptional performance in sequence modeling. Recently, a promising model architecture, Mamba, has emerged as a potential alternative to transformer-based models because of its efficient modeling of long sequences. In particular, models like SEMamba have demonstrated the effectiveness of the Mamba architecture in single-channel speech enhancement. This paper aims to adapt SEMamba for multi-channel applications with only a small increase in parameters. The resulting system, MC-SEMamba, achieved results on the CHiME3 dataset that were comparable or even superior to several previous baseline models. Additionally, we found that increasing the number of microphones from 1 to 6 improved the speech enhancement performance of MC-SEMamba.
Quantum Gradient Class Activation Map for Model Interpretability
Aug 12, 2024



Quantum machine learning (QML) has recently made significant advancements in various topics. Despite the successes, the safety and interpretability of QML applications have not been thoroughly investigated. This work proposes using Variational Quantum Circuits (VQCs) for activation mapping to enhance model transparency, introducing the Quantum Gradient Class Activation Map (QGrad-CAM). This hybrid quantum-classical computing framework leverages both quantum and classical strengths and gives access to the derivation of an explicit formula of feature map importance. Experimental results demonstrate significant, fine-grained, class-discriminative visual explanations generated across both image and speech datasets.
Interpretations of Domain Adaptations via Layer Variational Analysis
Feb 03, 2023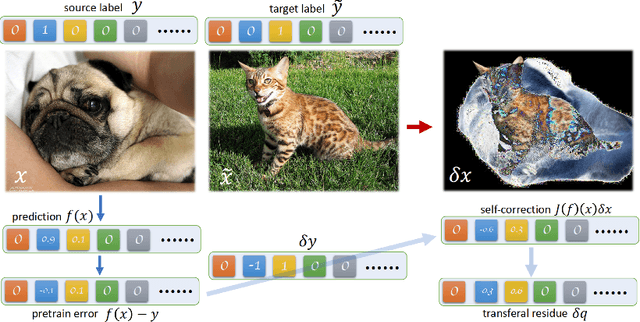
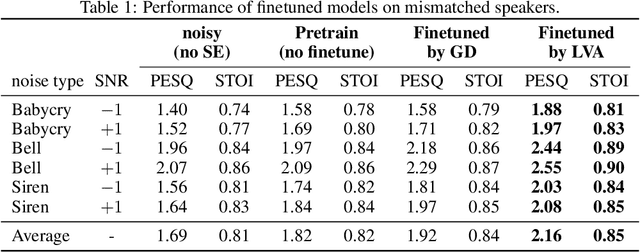

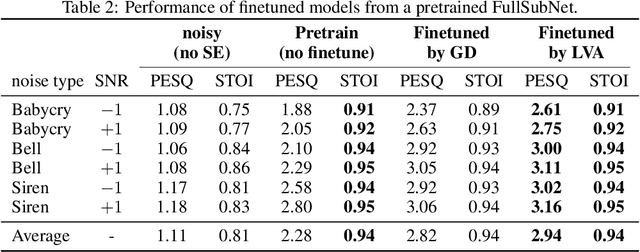
Transfer learning is known to perform efficiently in many applications empirically, yet limited literature reports the mechanism behind the scene. This study establishes both formal derivations and heuristic analysis to formulate the theory of transfer learning in deep learning. Our framework utilizing layer variational analysis proves that the success of transfer learning can be guaranteed with corresponding data conditions. Moreover, our theoretical calculation yields intuitive interpretations towards the knowledge transfer process. Subsequently, an alternative method for network-based transfer learning is derived. The method shows an increase in efficiency and accuracy for domain adaptation. It is particularly advantageous when new domain data is sufficiently sparse during adaptation. Numerical experiments over diverse tasks validated our theory and verified that our analytic expression achieved better performance in domain adaptation than the gradient descent method.
On the robustness of non-intrusive speech quality model by adversarial examples
Nov 11, 2022It has been shown recently that deep learning based models are effective on speech quality prediction and could outperform traditional metrics in various perspectives. Although network models have potential to be a surrogate for complex human hearing perception, they may contain instabilities in predictions. This work shows that deep speech quality predictors can be vulnerable to adversarial perturbations, where the prediction can be changed drastically by unnoticeable perturbations as small as $-30$ dB compared with speech inputs. In addition to exposing the vulnerability of deep speech quality predictors, we further explore and confirm the viability of adversarial training for strengthening robustness of models.
Unsupervised Noise Adaptive Speech Enhancement by Discriminator-Constrained Optimal Transport
Nov 11, 2021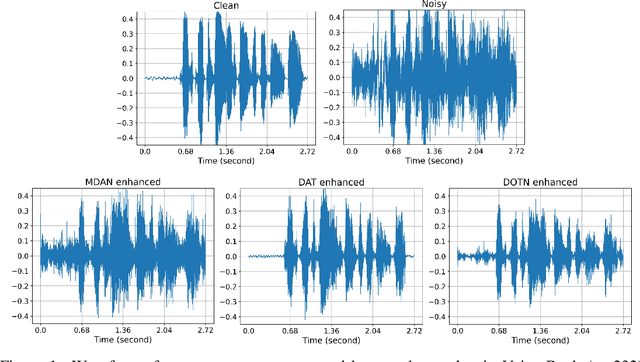
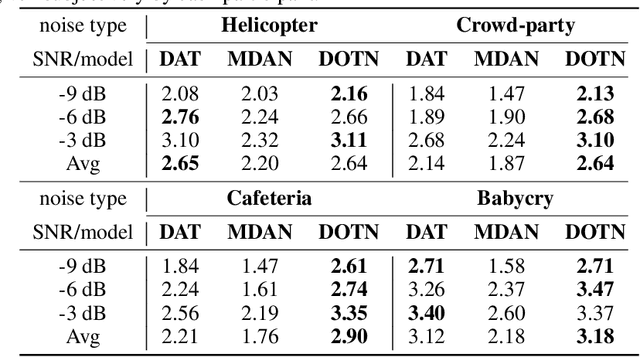
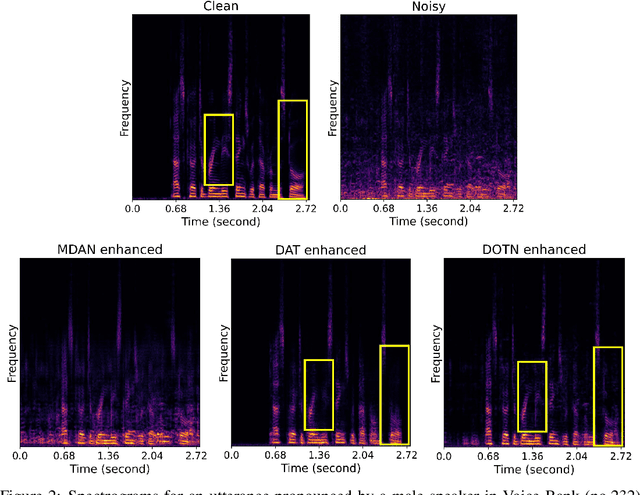
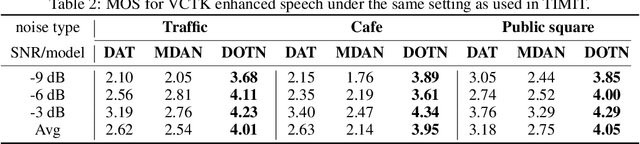
This paper presents a novel discriminator-constrained optimal transport network (DOTN) that performs unsupervised domain adaptation for speech enhancement (SE), which is an essential regression task in speech processing. The DOTN aims to estimate clean references of noisy speech in a target domain, by exploiting the knowledge available from the source domain. The domain shift between training and testing data has been reported to be an obstacle to learning problems in diverse fields. Although rich literature exists on unsupervised domain adaptation for classification, the methods proposed, especially in regressions, remain scarce and often depend on additional information regarding the input data. The proposed DOTN approach tactically fuses the optimal transport (OT) theory from mathematical analysis with generative adversarial frameworks, to help evaluate continuous labels in the target domain. The experimental results on two SE tasks demonstrate that by extending the classical OT formulation, our proposed DOTN outperforms previous adversarial domain adaptation frameworks in a purely unsupervised manner.