 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstraining Chaos: Enforcing dynamical invariants in the training of recurrent neural networks
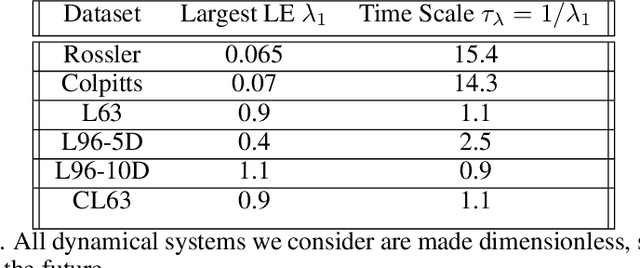
Apr 24, 2023Drawing on ergodic theory, we introduce a novel training method for machine learning based forecasting methods for chaotic dynamical systems. The training enforces dynamical invariants--such as the Lyapunov exponent spectrum and fractal dimension--in the systems of interest, enabling longer and more stable forecasts when operating with limited data. The technique is demonstrated in detail using the recurrent neural network architecture of reservoir computing. Results are given for the Lorenz 1996 chaotic dynamical system and a spectral quasi-geostrophic model, both typical test cases for numerical weather prediction.
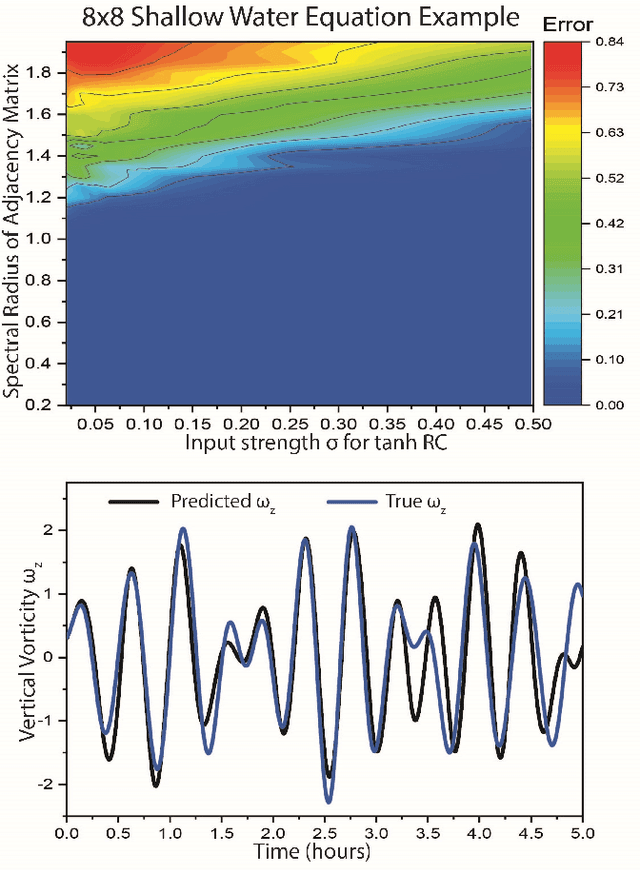
A Systematic Exploration of Reservoir Computing for Forecasting Complex Spatiotemporal Dynamics
Jan 21, 2022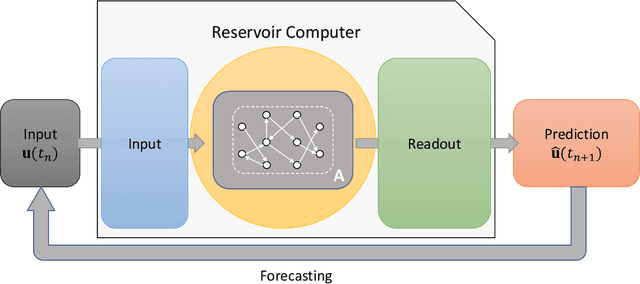

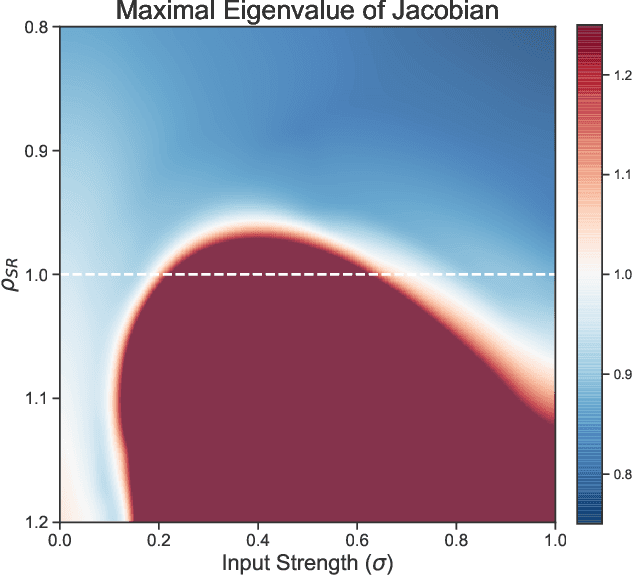
A reservoir computer (RC) is a type of simplified recurrent neural network architecture that has demonstrated success in the prediction of spatiotemporally chaotic dynamical systems. A further advantage of RC is that it reproduces intrinsic dynamical quantities essential for its incorporation into numerical forecasting routines such as the ensemble Kalman filter -- used in numerical weather prediction to compensate for sparse and noisy data. We explore here the architecture and design choices for a "best in class" RC for a number of characteristic dynamical systems, and then show the application of these choices in scaling up to larger models using localization. Our analysis points to the importance of large scale parameter optimization. We also note in particular the importance of including input bias in the RC design, which has a significant impact on the forecast skill of the trained RC model. In our tests, the the use of a nonlinear readout operator does not affect the forecast time or the stability of the forecast. The effects of the reservoir dimension, spinup time, amount of training data, normalization, noise, and the RC time step are also investigated. While we are not aware of a generally accepted best reported mean forecast time for different models in the literature, we report over a factor of 2 increase in the mean forecast time compared to the best performing RC model of Vlachas et.al (2020) for the 40 dimensional spatiotemporally chaotic Lorenz 1996 dynamics, and we are able to accomplish this using a smaller reservoir size.
Integrating Recurrent Neural Networks with Data Assimilation for Scalable Data-Driven State Estimation
Sep 25, 2021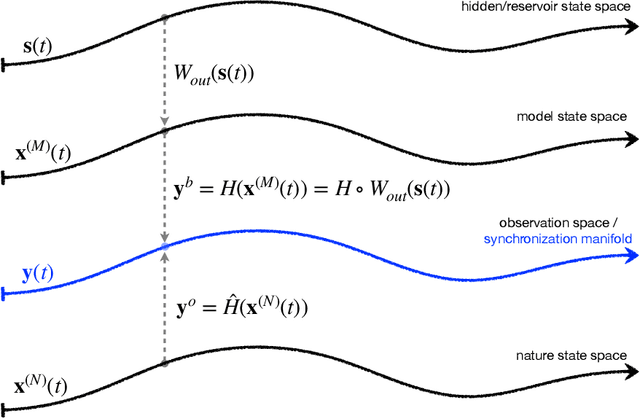

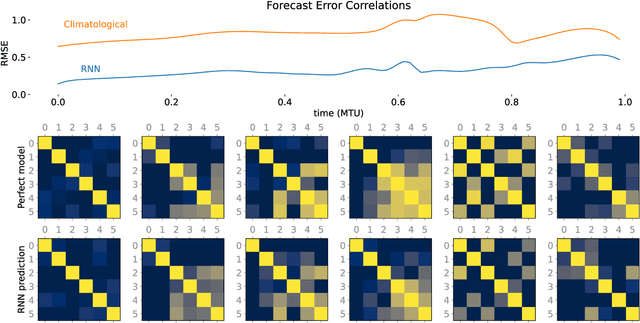
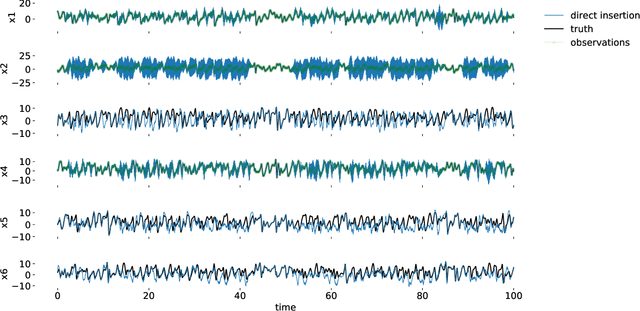
Data assimilation (DA) is integrated with machine learning in order to perform entirely data-driven online state estimation. To achieve this, recurrent neural networks (RNNs) are implemented as surrogate models to replace key components of the DA cycle in numerical weather prediction (NWP), including the conventional numerical forecast model, the forecast error covariance matrix, and the tangent linear and adjoint models. It is shown how these RNNs can be initialized using DA methods to directly update the hidden/reservoir state with observations of the target system. The results indicate that these techniques can be applied to estimate the state of a system for the repeated initialization of short-term forecasts, even in the absence of a traditional numerical forecast model. Further, it is demonstrated how these integrated RNN-DA methods can scale to higher dimensions by applying domain localization and parallelization, providing a path for practical applications in NWP.
Forecasting Using Reservoir Computing: The Role of Generalized Synchronization
Feb 28, 2021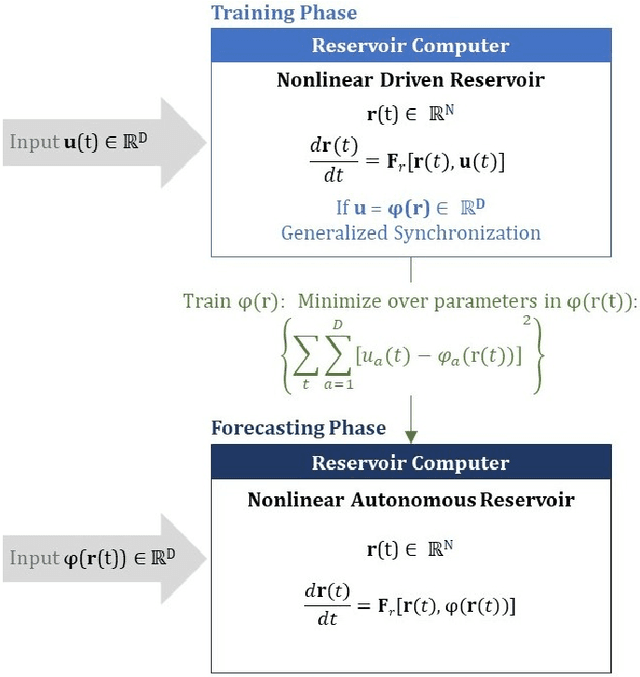
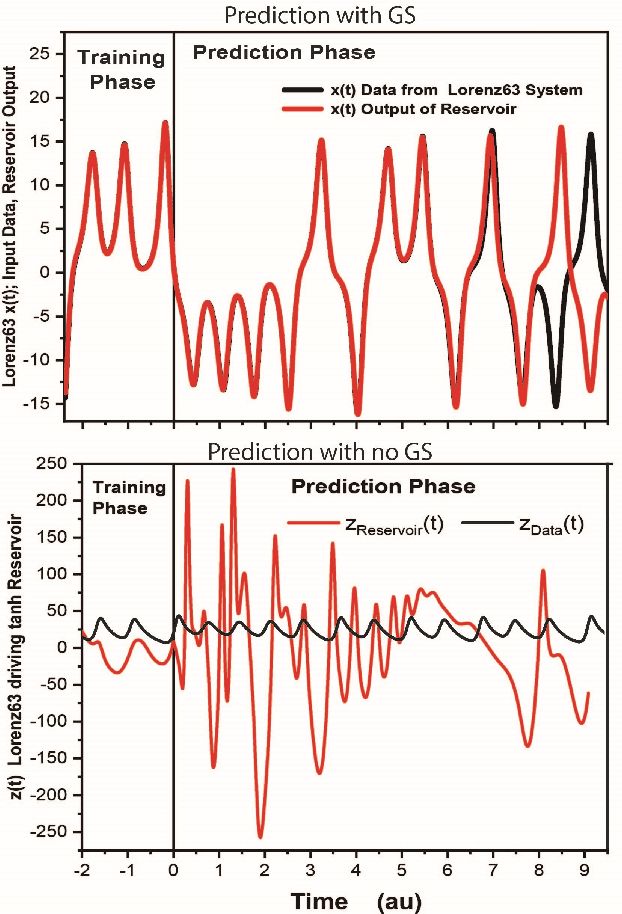
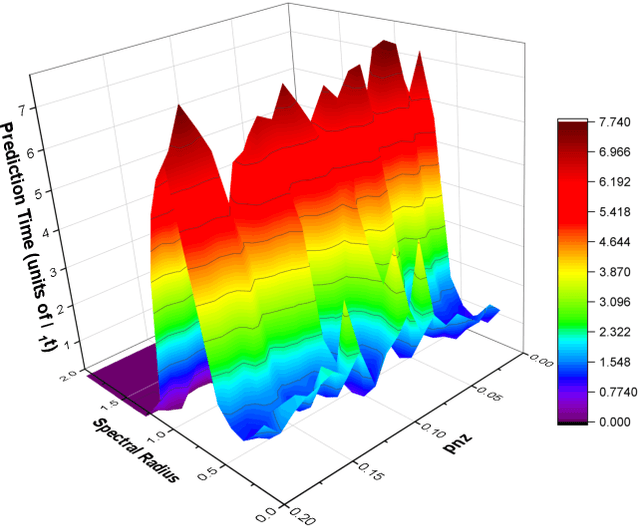
Reservoir computers (RC) are a form of recurrent neural network (RNN) used for forecasting time series data. As with all RNNs, selecting the hyperparameters presents a challenge when training on new inputs. We present a method based on generalized synchronization (GS) that gives direction in designing and evaluating the architecture and hyperparameters of a RC. The 'auxiliary method' for detecting GS provides a pre-training test that guides hyperparameter selection. Furthermore, we provide a metric for a "well trained" RC using the reproduction of the input system's Lyapunov exponents.
Machine Learning Classification Informed by a Functional Biophysical System
Nov 19, 2019
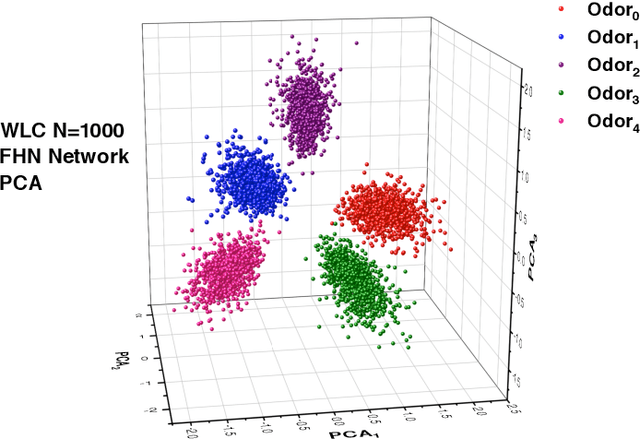


We present a novel machine learning architecture for classification suggested by experiments on the insect olfactory system. The network separates odors via a winnerless competition network, then classifies objects by projection into a high dimensional space where a support vector machine provides more precision in classification. We build this network using biophysical models of neurons with our results showing high discrimination among inputs and exceptional robustness to noise. The same circuitry accurately identifies the amplitudes of mixtures of the odors on which it has been trained.
Precision annealing Monte Carlo methods for statistical data assimilation and machine learning
Jul 06, 2019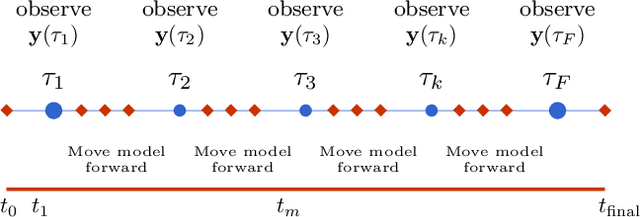
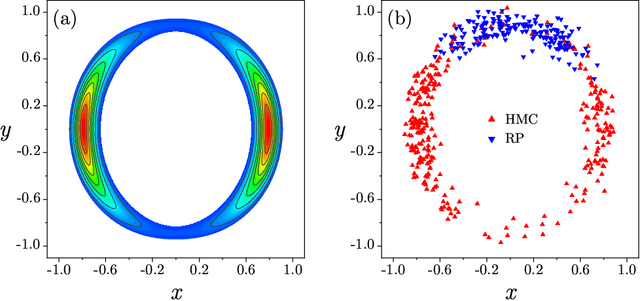

In statistical data assimilation (SDA) and supervised machine learning (ML), we wish to transfer information from observations to a model of the processes underlying those observations. For SDA, the model consists of a set of differential equations that describe the dynamics of a physical system. For ML, the model is usually constructed using other strategies. In this paper, we develop a systematic formulation based on Monte Carlo sampling to achieve such information transfer. Following the derivation of an appropriate target distribution, we present the formulation based on the standard Metropolis-Hasting (MH) procedure and the Hamiltonian Monte Carlo (HMC) method for performing the high dimensional integrals that appear. To the extensive literature on MH and HMC, we add (1) an annealing method using a hyperparameter that governs the precision of the model to identify and explore the highest probability regions of phase space dominating those integrals, and (2) a strategy for initializing the state space search. The efficacy of the proposed formulation is demonstrated using a nonlinear dynamical model with chaotic solutions widely used in geophysics.
Machine Learning of Time Series Using Time-delay Embedding and Precision Annealing
Feb 12, 2019Tasking machine learning to predict segments of a time series requires estimating the parameters of a ML model with input/output pairs from the time series. Using the equivalence between statistical data assimilation and supervised machine learning, we revisit this task. The training method for the machine utilizes a precision annealing approach to identifying the global minimum of the action (-log[P]). In this way we are able to identify the number of training pairs required to produce good generalizations (predictions) for the time series. We proceed from a scalar time series $s(t_n); t_n = t_0 + n \Delta t$ and using methods of nonlinear time series analysis show how to produce a $D_E > 1$ dimensional time delay embedding space in which the time series has no false neighbors as does the observed $s(t_n)$ time series. In that $D_E$-dimensional space we explore the use of feed forward multi-layer perceptrons as network models operating on $D_E$-dimensional input and producing $D_E$-dimensional outputs.