 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Fold Real Garments with One Arm: A Case Study in Cloud-Based Robotics Research
Apr 21, 2022

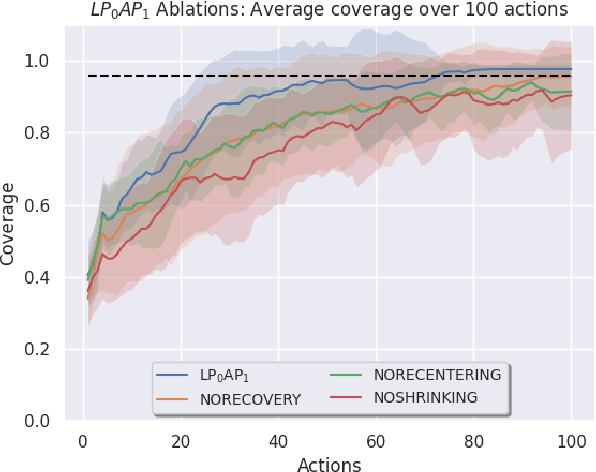

Autonomous fabric manipulation is a longstanding challenge in robotics, but evaluating progress is difficult due to the cost and diversity of robot hardware. Using Reach, a cloud robotics platform that enables low-latency remote execution of control policies on physical robots, we present the first systematic benchmarking of fabric manipulation algorithms on physical hardware. We develop 4 novel learning-based algorithms that model expert actions, keypoints, reward functions, and dynamic motions, and we compare these against 4 learning-free and inverse dynamics algorithms on the task of folding a crumpled T-shirt with a single robot arm. The entire lifecycle of data collection, model training, and policy evaluation is performed remotely without physical access to the robot workcell. Results suggest a new algorithm combining imitation learning with analytic methods achieves 84% of human-level performance on the folding task. See https://sites.google.com/berkeley.edu/cloudfolding for all data, code, models, and supplemental material.
Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language
Apr 01, 2022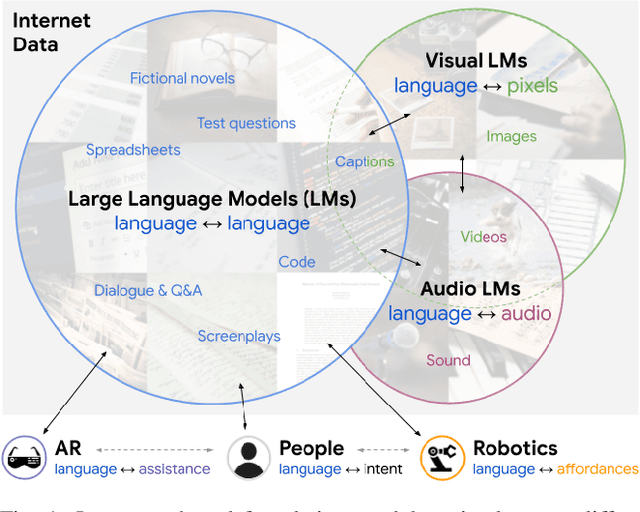
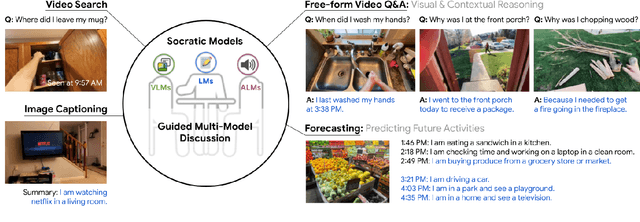
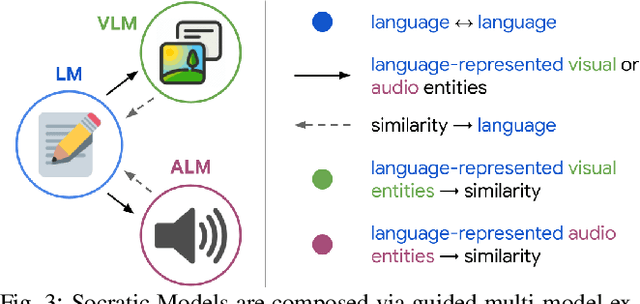

Large foundation models can exhibit unique capabilities depending on the domain of data they are trained on. While these domains are generic, they may only barely overlap. For example, visual-language models (VLMs) are trained on Internet-scale image captions, but large language models (LMs) are further trained on Internet-scale text with no images (e.g. from spreadsheets, to SAT questions). As a result, these models store different forms of commonsense knowledge across different domains. In this work, we show that this model diversity is symbiotic, and can be leveraged to build AI systems with structured Socratic dialogue -- in which new multimodal tasks are formulated as a guided language-based exchange between different pre-existing foundation models, without additional finetuning. In the context of egocentric perception, we present a case study of Socratic Models (SMs) that can provide meaningful results for complex tasks such as generating free-form answers to contextual questions about egocentric video, by formulating video Q&A as short story Q&A, i.e. summarizing the video into a short story, then answering questions about it. Additionally, SMs can generate captions for Internet images, and are competitive with state-of-the-art on zero-shot video-to-text retrieval with 42.8 R@1 on MSR-VTT 1k-A. SMs demonstrate how to compose foundation models zero-shot to capture new multimodal functionalities, without domain-specific data collection. Prototypes are available at socraticmodels.github.io.
Implicit Behavioral Cloning
Sep 01, 2021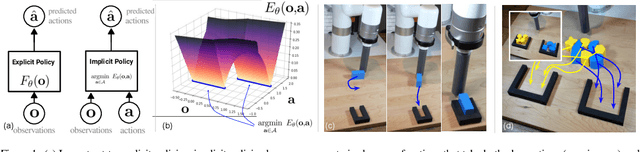

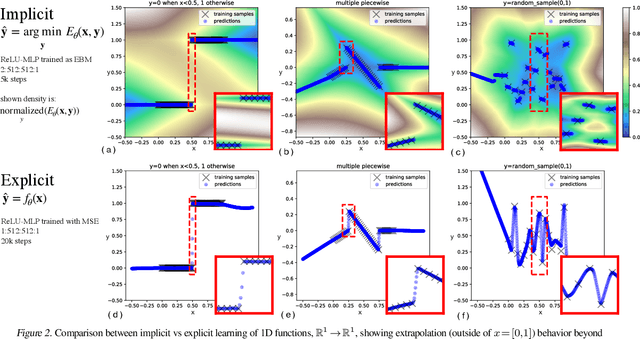
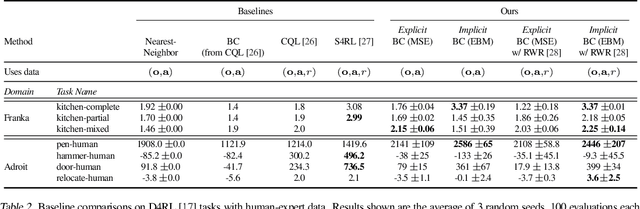
We find that across a wide range of robot policy learning scenarios, treating supervised policy learning with an implicit model generally performs better, on average, than commonly used explicit models. We present extensive experiments on this finding, and we provide both intuitive insight and theoretical arguments distinguishing the properties of implicit models compared to their explicit counterparts, particularly with respect to approximating complex, potentially discontinuous and multi-valued (set-valued) functions. On robotic policy learning tasks we show that implicit behavioral cloning policies with energy-based models (EBM) often outperform common explicit (Mean Square Error, or Mixture Density) behavioral cloning policies, including on tasks with high-dimensional action spaces and visual image inputs. We find these policies provide competitive results or outperform state-of-the-art offline reinforcement learning methods on the challenging human-expert tasks from the D4RL benchmark suite, despite using no reward information. In the real world, robots with implicit policies can learn complex and remarkably subtle behaviors on contact-rich tasks from human demonstrations, including tasks with high combinatorial complexity and tasks requiring 1mm precision.
Forecasting Using Reservoir Computing: The Role of Generalized Synchronization
Feb 28, 2021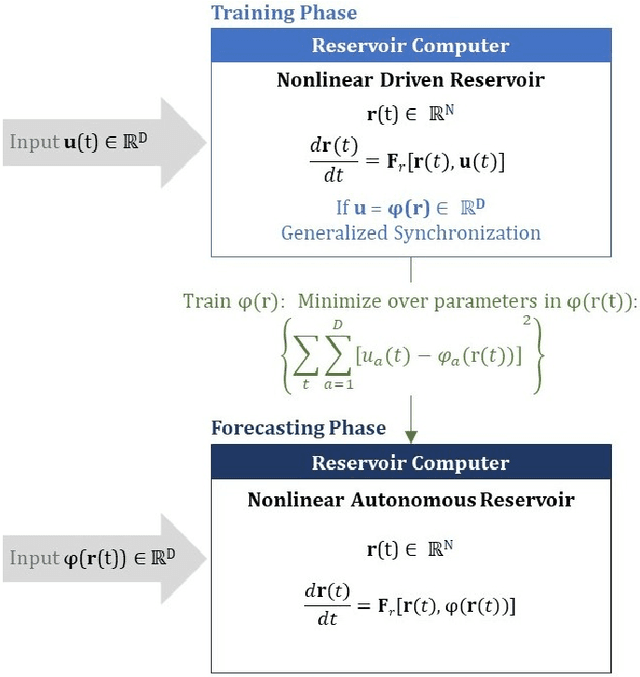
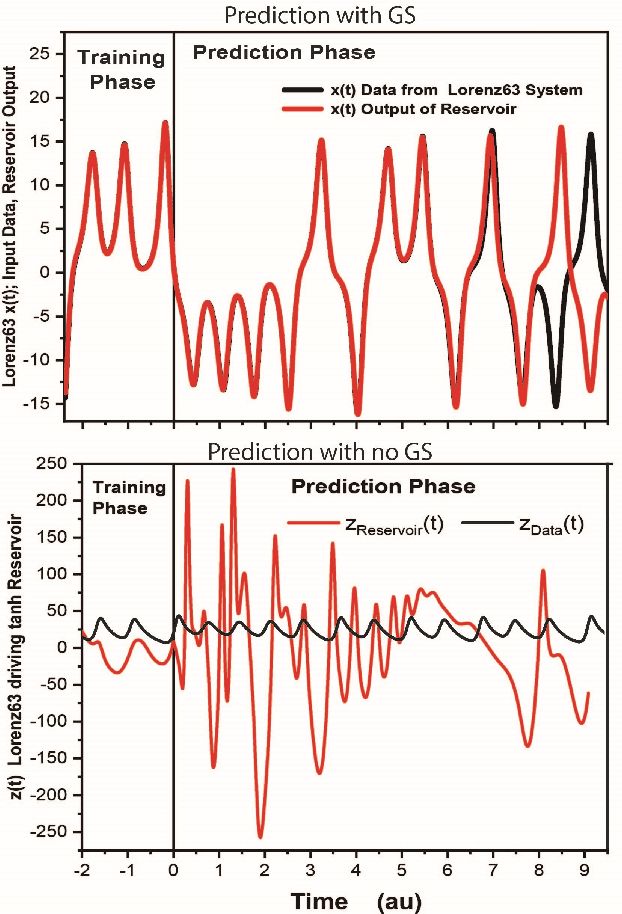
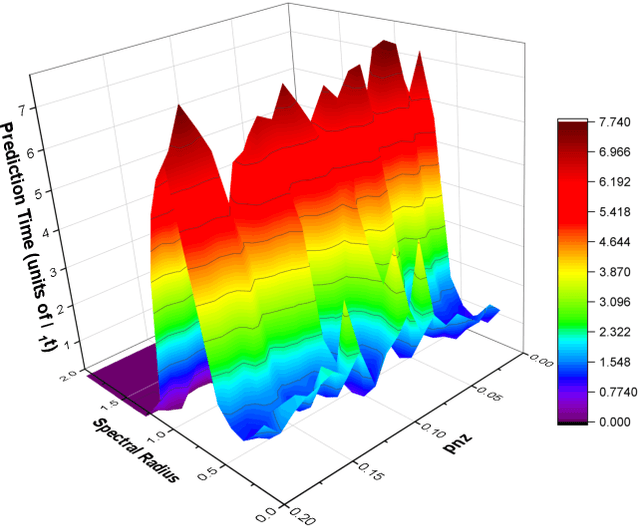
Reservoir computers (RC) are a form of recurrent neural network (RNN) used for forecasting time series data. As with all RNNs, selecting the hyperparameters presents a challenge when training on new inputs. We present a method based on generalized synchronization (GS) that gives direction in designing and evaluating the architecture and hyperparameters of a RC. The 'auxiliary method' for detecting GS provides a pre-training test that guides hyperparameter selection. Furthermore, we provide a metric for a "well trained" RC using the reproduction of the input system's Lyapunov exponents.