 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Self-Supervised Learning for Interactive Perception of Surgical Thread for Autonomous Suture Tail-Shortening
Jul 13, 2023



Accurate 3D sensing of suturing thread is a challenging problem in automated surgical suturing because of the high state-space complexity, thinness and deformability of the thread, and possibility of occlusion by the grippers and tissue. In this work we present a method for tracking surgical thread in 3D which is robust to occlusions and complex thread configurations, and apply it to autonomously perform the surgical suture "tail-shortening" task: pulling thread through tissue until a desired "tail" length remains exposed. The method utilizes a learned 2D surgical thread detection network to segment suturing thread in RGB images. It then identifies the thread path in 2D and reconstructs the thread in 3D as a NURBS spline by triangulating the detections from two stereo cameras. Once a 3D thread model is initialized, the method tracks the thread across subsequent frames. Experiments suggest the method achieves a 1.33 pixel average reprojection error on challenging single-frame 3D thread reconstructions, and an 0.84 pixel average reprojection error on two tracking sequences. On the tail-shortening task, it accomplishes a 90% success rate across 20 trials. Supplemental materials are available at https://sites.google.com/berkeley.edu/autolab-surgical-thread/ .
Learning to Trace and Untangle Semi-planar Knots
Mar 15, 2023



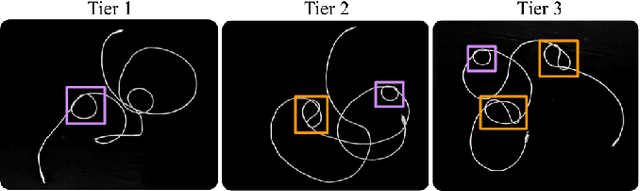
This paper extends prior work on untangling long cables and presents TUSK (Tracing to Untangle Semi-planar Knots), a learned cable-tracing algorithm that resolves over-crossings and undercrossings to recognize the structure of knots and grasp points for untangling from a single RGB image. This work focuses on semi-planar knots, which are knots composed of crossings that each include at most 2 cable segments. We conduct experiments on long cables (3 m in length) with up to 15 semi-planar crossings across 6 different knot types. Crops of crossings from 3 knots (overhand, figure 8, and bowline) of the 6 are seen during training, but none of the full knots are seen during training. This is an improvement from prior work on long cables that can only untangle 2 knot types. Experiments find that in settings with multiple identical cables, TUSK can trace a single cable with 81% accuracy on 7 new knot types. In single-cable images, TUSK can trace and identify the correct knot with 77% success on 3 new knot types. We incorporate TUSK into a bimanual robot system and find that it successfully untangles 64% of cable configurations, including those with new knots unseen during training, across 3 levels of difficulty. Supplementary material, including an annotated dataset of 500 RGB-D images of a knotted cable along with ground-truth traces, can be found at https://sites.google.com/view/tusk-rss.
From Occlusion to Insight: Object Search in Semantic Shelves using Large Language Models
Feb 24, 2023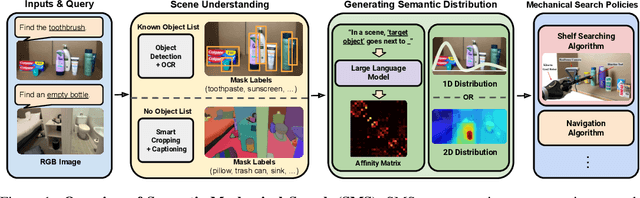
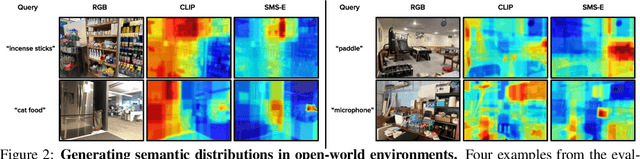

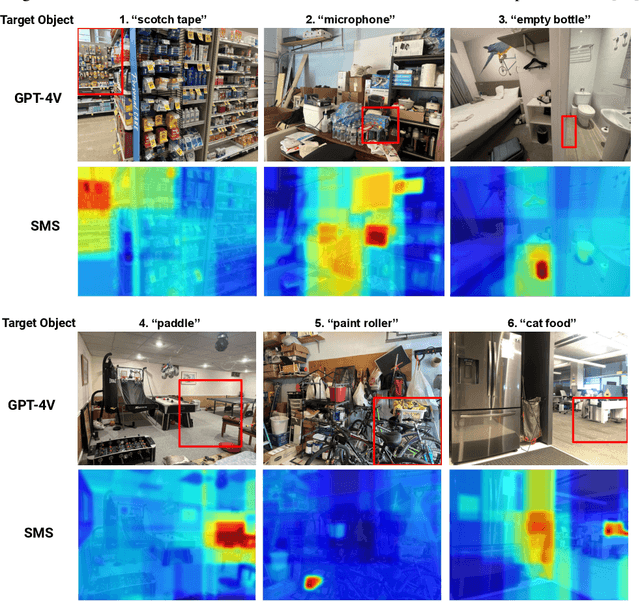
How can a robot efficiently extract a desired object from a shelf when it is fully occluded by other objects? Prior works propose geometric approaches for this problem but do not consider object semantics. Shelves in pharmacies, restaurant kitchens, and grocery stores are often organized such that semantically similar objects are placed close to one another. Can large language models (LLMs) serve as semantic knowledge sources to accelerate robotic mechanical search in semantically arranged environments? With Semantic Spatial Search on Shelves (S^4), we use LLMs to generate affinity matrices, where entries correspond to semantic likelihood of physical proximity between objects. We derive semantic spatial distributions by synthesizing semantics with learned geometric constraints. S^4 incorporates Optical Character Recognition (OCR) and semantic refinement with predictions from ViLD, an open-vocabulary object detection model. Simulation experiments suggest that semantic spatial search reduces the search time relative to pure spatial search by an average of 24% across three domains: pharmacy, kitchen, and office shelves. A manually collected dataset of 100 semantic scenes suggests that OCR and semantic refinement improve object detection accuracy by 35%. Lastly, physical experiments in a pharmacy shelf suggest 47.1% improvement over pure spatial search. Supplementary material can be found at https://sites.google.com/view/s4-rss/home.
SGTM 2.0: Autonomously Untangling Long Cables using Interactive Perception
Sep 27, 2022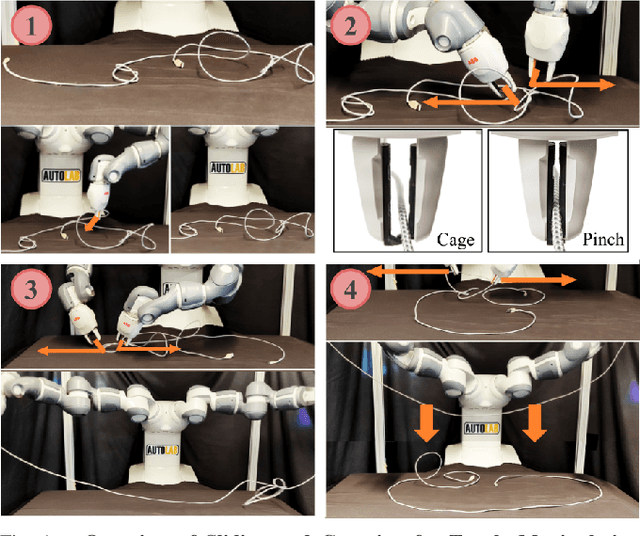

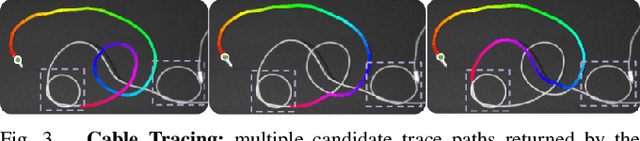
Cables are commonplace in homes, hospitals, and industrial warehouses and are prone to tangling. This paper extends prior work on autonomously untangling long cables by introducing novel uncertainty quantification metrics and actions that interact with the cable to reduce perception uncertainty. We present Sliding and Grasping for Tangle Manipulation 2.0 (SGTM 2.0), a system that autonomously untangles cables approximately 3 meters in length with a bilateral robot using estimates of uncertainty at each step to inform actions. By interactively reducing uncertainty, Sliding and Grasping for Tangle Manipulation 2.0 (SGTM 2.0) reduces the number of state-resetting moves it must take, significantly speeding up run-time. Experiments suggest that SGTM 2.0 can achieve 83% untangling success on cables with 1 or 2 overhand and figure-8 knots, and 70% termination detection success across these configurations, outperforming SGTM 1.0 by 43% in untangling accuracy and 200% in full rollout speed. Supplementary material, visualizations, and videos can be found at sites.google.com/view/sgtm2.
DEFT: Diverse Ensembles for Fast Transfer in Reinforcement Learning
Sep 26, 2022
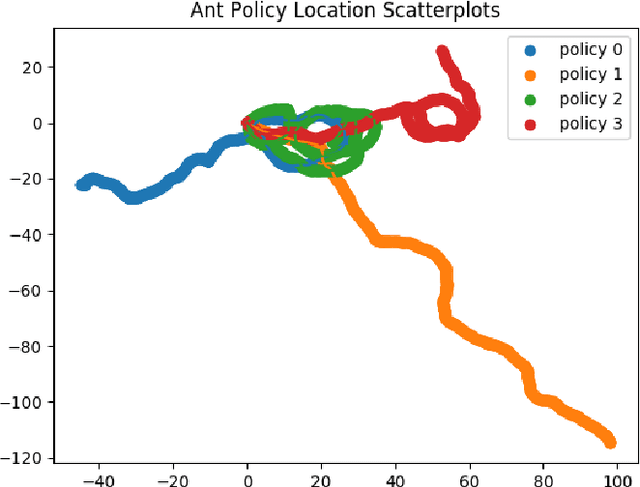

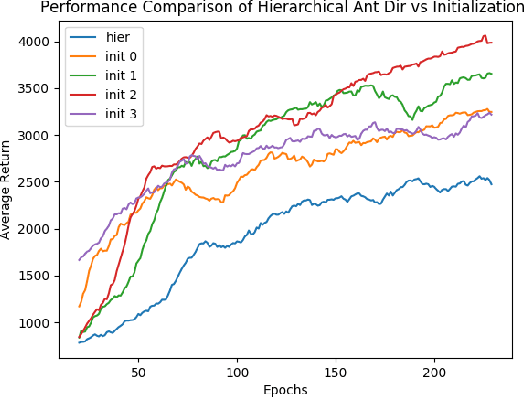
Deep ensembles have been shown to extend the positive effect seen in typical ensemble learning to neural networks and to reinforcement learning (RL). However, there is still much to be done to improve the efficiency of such ensemble models. In this work, we present Diverse Ensembles for Fast Transfer in RL (DEFT), a new ensemble-based method for reinforcement learning in highly multimodal environments and improved transfer to unseen environments. The algorithm is broken down into two main phases: training of ensemble members, and synthesis (or fine-tuning) of the ensemble members into a policy that works in a new environment. The first phase of the algorithm involves training regular policy gradient or actor-critic agents in parallel but adding a term to the loss that encourages these policies to differ from each other. This causes the individual unimodal agents to explore the space of optimal policies and capture more of the multimodality of the environment than a single actor could. The second phase of DEFT involves synthesizing the component policies into a new policy that works well in a modified environment in one of two ways. To evaluate the performance of DEFT, we start with a base version of the Proximal Policy Optimization (PPO) algorithm and extend it with the modifications for DEFT. Our results show that the pretraining phase is effective in producing diverse policies in multimodal environments. DEFT often converges to a high reward significantly faster than alternatives, such as random initialization without DEFT and fine-tuning of ensemble members. While there is certainly more work to be done to analyze DEFT theoretically and extend it to be even more robust, we believe it provides a strong framework for capturing multimodality in environments while still using RL methods with simple policy representations.
Autonomously Untangling Long Cables
Jul 16, 2022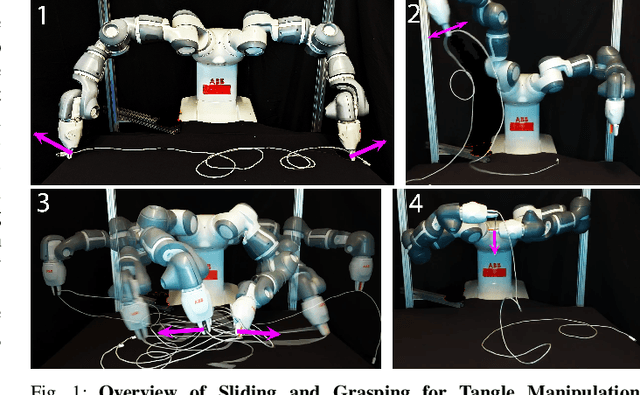


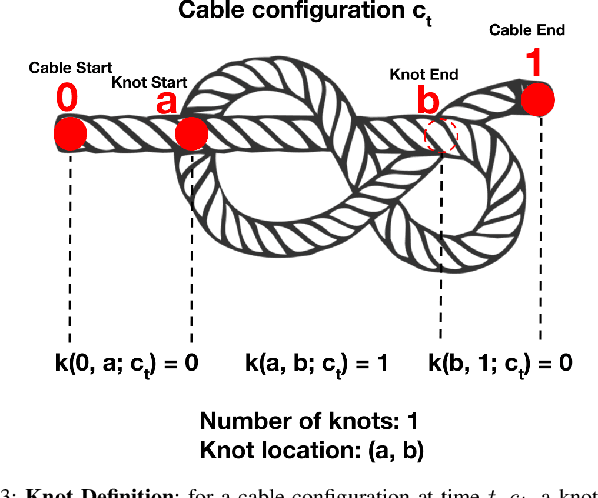
Cables are ubiquitous in many settings, but are prone to self-occlusions and knots, making them difficult to perceive and manipulate. The challenge often increases with cable length: long cables require more complex slack management and strategies to facilitate observability and reachability. In this paper, we focus on autonomously untangling cables up to 3 meters in length using a bilateral robot. We develop new motion primitives to efficiently untangle long cables and novel gripper jaws specialized for this task. We present Sliding and Grasping for Tangle Manipulation (SGTM), an algorithm that composes these primitives with RGBD vision to iteratively untangle. SGTM untangles cables with success rates of 67% on isolated overhand and figure eight knots and 50% on more complex configurations. Supplementary material, visualizations, and videos can be found at https://sites.google.com/view/rss-2022-untangling/home.
Learning to Fold Real Garments with One Arm: A Case Study in Cloud-Based Robotics Research
Apr 21, 2022


Autonomous fabric manipulation is a longstanding challenge in robotics, but evaluating progress is difficult due to the cost and diversity of robot hardware. Using Reach, a cloud robotics platform that enables low-latency remote execution of control policies on physical robots, we present the first systematic benchmarking of fabric manipulation algorithms on physical hardware. We develop 4 novel learning-based algorithms that model expert actions, keypoints, reward functions, and dynamic motions, and we compare these against 4 learning-free and inverse dynamics algorithms on the task of folding a crumpled T-shirt with a single robot arm. The entire lifecycle of data collection, model training, and policy evaluation is performed remotely without physical access to the robot workcell. Results suggest a new algorithm combining imitation learning with analytic methods achieves 84% of human-level performance on the folding task. See https://sites.google.com/berkeley.edu/cloudfolding for all data, code, models, and supplemental material.