 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDEFT: Diverse Ensembles for Fast Transfer in Reinforcement Learning
Paper and Code
Sep 26, 2022
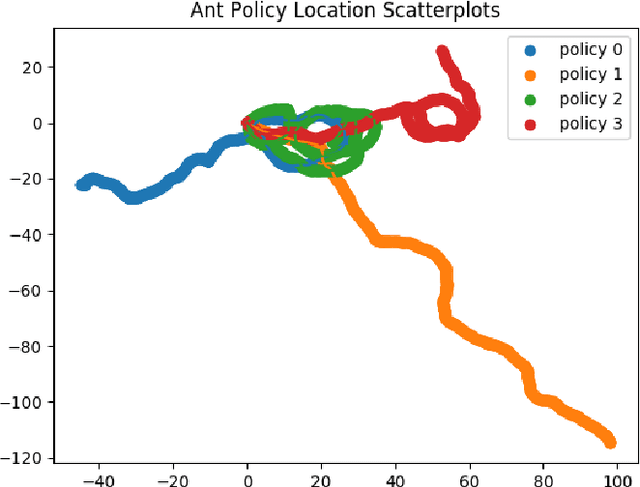

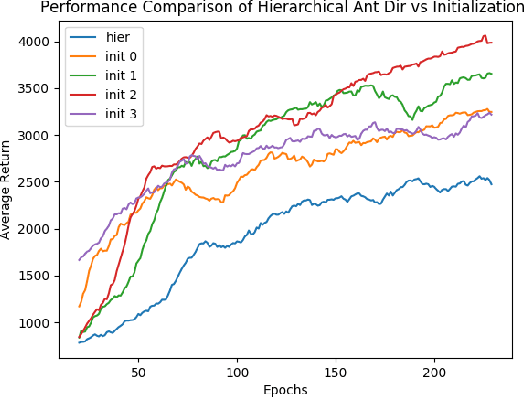
Deep ensembles have been shown to extend the positive effect seen in typical ensemble learning to neural networks and to reinforcement learning (RL). However, there is still much to be done to improve the efficiency of such ensemble models. In this work, we present Diverse Ensembles for Fast Transfer in RL (DEFT), a new ensemble-based method for reinforcement learning in highly multimodal environments and improved transfer to unseen environments. The algorithm is broken down into two main phases: training of ensemble members, and synthesis (or fine-tuning) of the ensemble members into a policy that works in a new environment. The first phase of the algorithm involves training regular policy gradient or actor-critic agents in parallel but adding a term to the loss that encourages these policies to differ from each other. This causes the individual unimodal agents to explore the space of optimal policies and capture more of the multimodality of the environment than a single actor could. The second phase of DEFT involves synthesizing the component policies into a new policy that works well in a modified environment in one of two ways. To evaluate the performance of DEFT, we start with a base version of the Proximal Policy Optimization (PPO) algorithm and extend it with the modifications for DEFT. Our results show that the pretraining phase is effective in producing diverse policies in multimodal environments. DEFT often converges to a high reward significantly faster than alternatives, such as random initialization without DEFT and fine-tuning of ensemble members. While there is certainly more work to be done to analyze DEFT theoretically and extend it to be even more robust, we believe it provides a strong framework for capturing multimodality in environments while still using RL methods with simple policy representations.