 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConformal Policy Learning for Sensorimotor Control Under Distribution Shifts
Nov 02, 2023This paper focuses on the problem of detecting and reacting to changes in the distribution of a sensorimotor controller's observables. The key idea is the design of switching policies that can take conformal quantiles as input, which we define as conformal policy learning, that allows robots to detect distribution shifts with formal statistical guarantees. We show how to design such policies by using conformal quantiles to switch between base policies with different characteristics, e.g. safety or speed, or directly augmenting a policy observation with a quantile and training it with reinforcement learning. Theoretically, we show that such policies achieve the formal convergence guarantees in finite time. In addition, we thoroughly evaluate their advantages and limitations on two compelling use cases: simulated autonomous driving and active perception with a physical quadruped. Empirical results demonstrate that our approach outperforms five baselines. It is also the simplest of the baseline strategies besides one ablation. Being easy to use, flexible, and with formal guarantees, our work demonstrates how conformal prediction can be an effective tool for sensorimotor learning under uncertainty.
Language Embedded Radiance Fields for Zero-Shot Task-Oriented Grasping
Sep 18, 2023



Grasping objects by a specific part is often crucial for safety and for executing downstream tasks. Yet, learning-based grasp planners lack this behavior unless they are trained on specific object part data, making it a significant challenge to scale object diversity. Instead, we propose LERF-TOGO, Language Embedded Radiance Fields for Task-Oriented Grasping of Objects, which uses vision-language models zero-shot to output a grasp distribution over an object given a natural language query. To accomplish this, we first reconstruct a LERF of the scene, which distills CLIP embeddings into a multi-scale 3D language field queryable with text. However, LERF has no sense of objectness, meaning its relevancy outputs often return incomplete activations over an object which are insufficient for subsequent part queries. LERF-TOGO mitigates this lack of spatial grouping by extracting a 3D object mask via DINO features and then conditionally querying LERF on this mask to obtain a semantic distribution over the object with which to rank grasps from an off-the-shelf grasp planner. We evaluate LERF-TOGO's ability to grasp task-oriented object parts on 31 different physical objects, and find it selects grasps on the correct part in 81% of all trials and grasps successfully in 69%. See the project website at: lerftogo.github.io
Can Machines Garden? Systematically Comparing the AlphaGarden vs. Professional Horticulturalists
Jun 29, 2023



The AlphaGarden is an automated testbed for indoor polyculture farming which combines a first-order plant simulator, a gantry robot, a seed planting algorithm, plant phenotyping and tracking algorithms, irrigation sensors and algorithms, and custom pruning tools and algorithms. In this paper, we systematically compare the performance of the AlphaGarden to professional horticulturalists on the staff of the UC Berkeley Oxford Tract Greenhouse. The humans and the machine tend side-by-side polyculture gardens with the same seed arrangement. We compare performance in terms of canopy coverage, plant diversity, and water consumption. Results from two 60-day cycles suggest that the automated AlphaGarden performs comparably to professional horticulturalists in terms of coverage and diversity, and reduces water consumption by as much as 44%. Code, videos, and datasets are available at https://sites.google.com/berkeley.edu/systematiccomparison.
From Occlusion to Insight: Object Search in Semantic Shelves using Large Language Models
Feb 24, 2023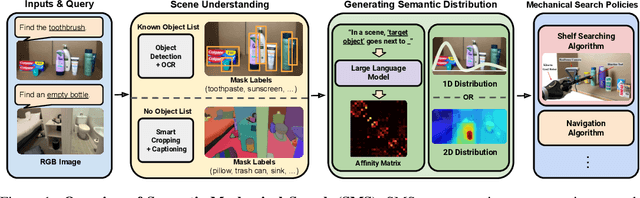
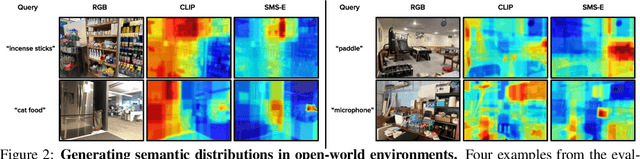

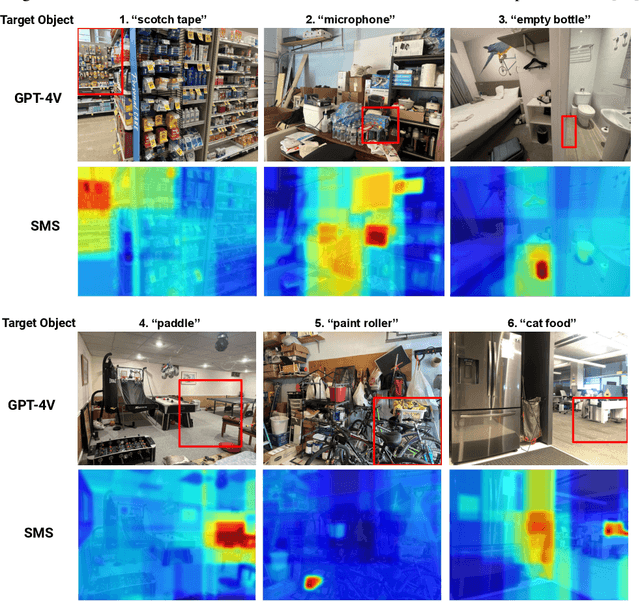
How can a robot efficiently extract a desired object from a shelf when it is fully occluded by other objects? Prior works propose geometric approaches for this problem but do not consider object semantics. Shelves in pharmacies, restaurant kitchens, and grocery stores are often organized such that semantically similar objects are placed close to one another. Can large language models (LLMs) serve as semantic knowledge sources to accelerate robotic mechanical search in semantically arranged environments? With Semantic Spatial Search on Shelves (S^4), we use LLMs to generate affinity matrices, where entries correspond to semantic likelihood of physical proximity between objects. We derive semantic spatial distributions by synthesizing semantics with learned geometric constraints. S^4 incorporates Optical Character Recognition (OCR) and semantic refinement with predictions from ViLD, an open-vocabulary object detection model. Simulation experiments suggest that semantic spatial search reduces the search time relative to pure spatial search by an average of 24% across three domains: pharmacy, kitchen, and office shelves. A manually collected dataset of 100 semantic scenes suggests that OCR and semantic refinement improve object detection accuracy by 35%. Lastly, physical experiments in a pharmacy shelf suggest 47.1% improvement over pure spatial search. Supplementary material can be found at https://sites.google.com/view/s4-rss/home.
Learning to Efficiently Plan Robust Frictional Multi-Object Grasps
Oct 13, 2022

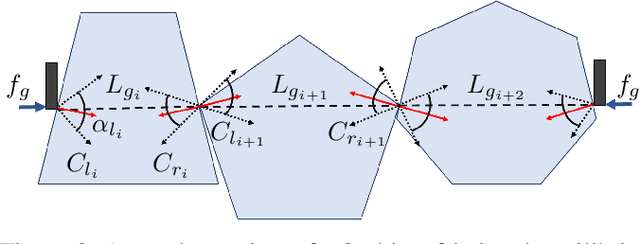

We consider a decluttering problem where multiple rigid convex polygonal objects rest in randomly placed positions and orientations on a planar surface and must be efficiently transported to a packing box using both single and multi-object grasps. Prior work considered frictionless multi-object grasping. In this paper, we introduce friction to increase picks per hour. We train a neural network using real examples to plan robust multi-object grasps. In physical experiments, we find an 11.7% increase in success rates, a 1.7x increase in picks per hour, and an 8.2x decrease in grasp planning time compared to prior work on multi-object grasping. Videos are available at https://youtu.be/pEZpHX5FZIs.
DEFT: Diverse Ensembles for Fast Transfer in Reinforcement Learning
Sep 26, 2022
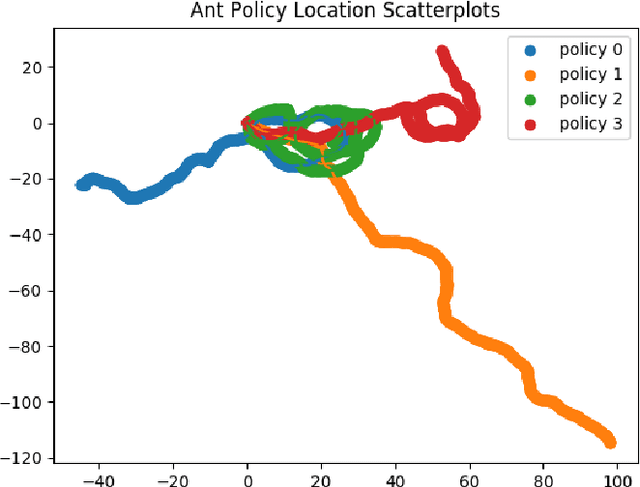

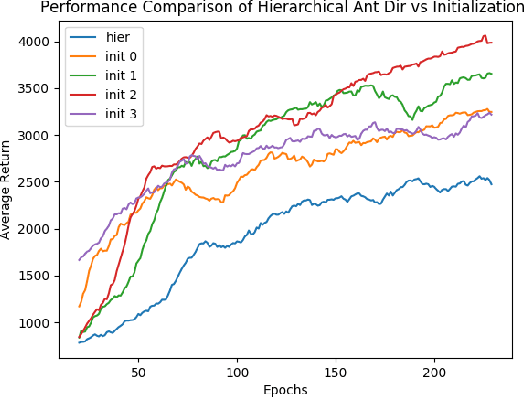
Deep ensembles have been shown to extend the positive effect seen in typical ensemble learning to neural networks and to reinforcement learning (RL). However, there is still much to be done to improve the efficiency of such ensemble models. In this work, we present Diverse Ensembles for Fast Transfer in RL (DEFT), a new ensemble-based method for reinforcement learning in highly multimodal environments and improved transfer to unseen environments. The algorithm is broken down into two main phases: training of ensemble members, and synthesis (or fine-tuning) of the ensemble members into a policy that works in a new environment. The first phase of the algorithm involves training regular policy gradient or actor-critic agents in parallel but adding a term to the loss that encourages these policies to differ from each other. This causes the individual unimodal agents to explore the space of optimal policies and capture more of the multimodality of the environment than a single actor could. The second phase of DEFT involves synthesizing the component policies into a new policy that works well in a modified environment in one of two ways. To evaluate the performance of DEFT, we start with a base version of the Proximal Policy Optimization (PPO) algorithm and extend it with the modifications for DEFT. Our results show that the pretraining phase is effective in producing diverse policies in multimodal environments. DEFT often converges to a high reward significantly faster than alternatives, such as random initialization without DEFT and fine-tuning of ensemble members. While there is certainly more work to be done to analyze DEFT theoretically and extend it to be even more robust, we believe it provides a strong framework for capturing multimodality in environments while still using RL methods with simple policy representations.
Automated Pruning of Polyculture Plants
Aug 22, 2022
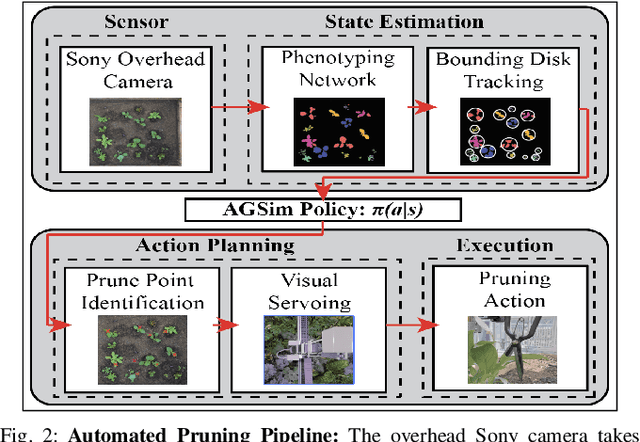
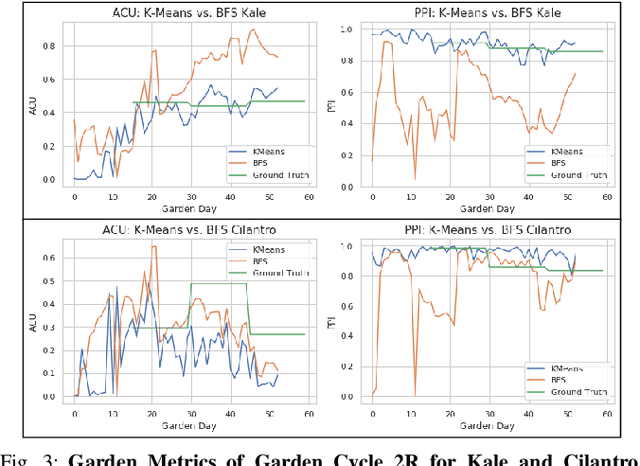

Polyculture farming has environmental advantages but requires substantially more pruning than monoculture farming. We present novel hardware and algorithms for automated pruning. Using an overhead camera to collect data from a physical scale garden testbed, the autonomous system utilizes a learned Plant Phenotyping convolutional neural network and a Bounding Disk Tracking algorithm to evaluate the individual plant distribution and estimate the state of the garden each day. From this garden state, AlphaGardenSim selects plants to autonomously prune. A trained neural network detects and targets specific prune points on the plant. Two custom-designed pruning tools, compatible with a FarmBot gantry system, are experimentally evaluated and execute autonomous cuts through controlled algorithms. We present results for four 60-day garden cycles. Results suggest the system can autonomously achieve 0.94 normalized plant diversity with pruning shears while maintaining an average canopy coverage of 0.84 by the end of the cycles. For code, videos, and datasets, see https://sites.google.com/berkeley.edu/pruningpolyculture.
Learning Switching Criteria for Sim2Real Transfer of Robotic Fabric Manipulation Policies
Jul 02, 2022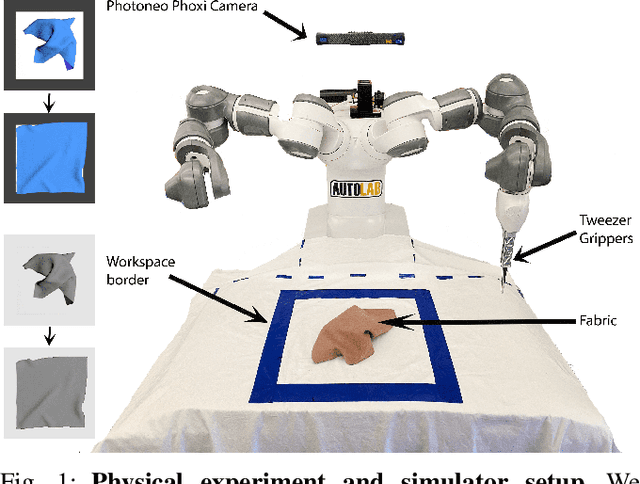
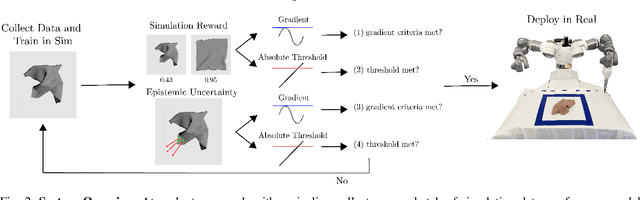

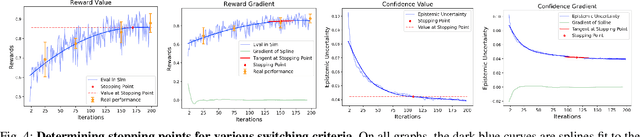
Simulation-to-reality transfer has emerged as a popular and highly successful method to train robotic control policies for a wide variety of tasks. However, it is often challenging to determine when policies trained in simulation are ready to be transferred to the physical world. Deploying policies that have been trained with very little simulation data can result in unreliable and dangerous behaviors on physical hardware. On the other hand, excessive training in simulation can cause policies to overfit to the visual appearance and dynamics of the simulator. In this work, we study strategies to automatically determine when policies trained in simulation can be reliably transferred to a physical robot. We specifically study these ideas in the context of robotic fabric manipulation, in which successful sim2real transfer is especially challenging due to the difficulties of precisely modeling the dynamics and visual appearance of fabric. Results in a fabric smoothing task suggest that our switching criteria correlate well with performance in real. In particular, our confidence-based switching criteria achieve average final fabric coverage of 87.2-93.7% within 55-60% of the total training budget. See https://tinyurl.com/lsc-case for code and supplemental materials.
Fleet-DAgger: Interactive Robot Fleet Learning with Scalable Human Supervision
Jun 29, 2022
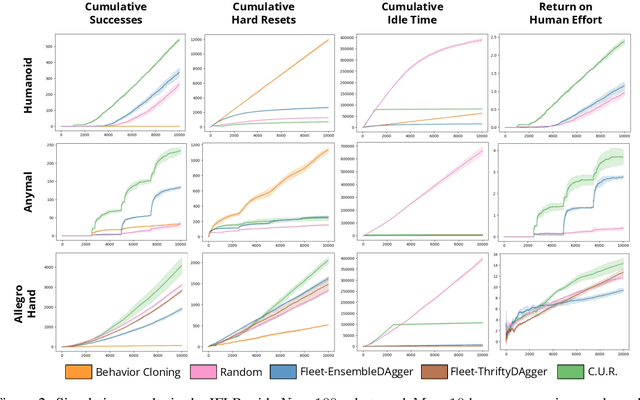
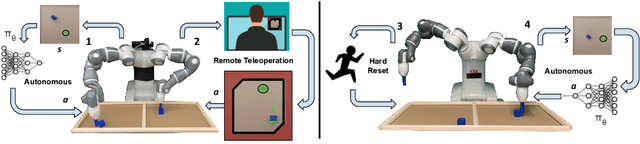
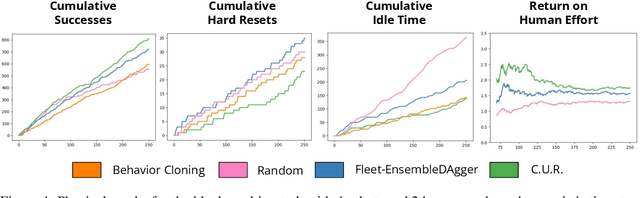
Commercial and industrial deployments of robot fleets often fall back on remote human teleoperators during execution when robots are at risk or unable to make task progress. With continual learning, interventions from the remote pool of humans can also be used to improve the robot fleet control policy over time. A central question is how to effectively allocate limited human attention to individual robots. Prior work addresses this in the single-robot, single-human setting. We formalize the Interactive Fleet Learning (IFL) setting, in which multiple robots interactively query and learn from multiple human supervisors. We present a fully implemented open-source IFL benchmark suite of GPU-accelerated Isaac Gym environments for the evaluation of IFL algorithms. We propose Fleet-DAgger, a family of IFL algorithms, and compare a novel Fleet-DAgger algorithm to 4 baselines in simulation. We also perform 1000 trials of a physical block-pushing experiment with 4 ABB YuMi robot arms. Experiments suggest that the allocation of humans to robots significantly affects robot fleet performance, and that our algorithm achieves up to 8.8x higher return on human effort than baselines. See https://tinyurl.com/fleet-dagger for code, videos, and supplemental material.
AlphaGarden: Learning to Autonomously Tend a Polyculture Garden
Nov 11, 2021
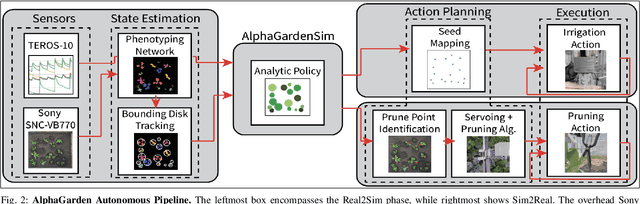

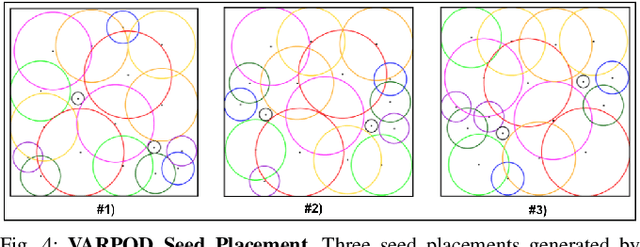
This paper presents AlphaGarden: an autonomous polyculture garden that prunes and irrigates living plants in a 1.5m x 3.0m physical testbed. AlphaGarden uses an overhead camera and sensors to track the plant distribution and soil moisture. We model individual plant growth and interplant dynamics to train a policy that chooses actions to maximize leaf coverage and diversity. For autonomous pruning, AlphaGarden uses two custom-designed pruning tools and a trained neural network to detect prune points. We present results for four 60-day garden cycles. Results suggest AlphaGarden can autonomously achieve 0.96 normalized diversity with pruning shears while maintaining an average canopy coverage of 0.86 during the peak of the cycle. Code, datasets, and supplemental material can be found at https://github.com/BerkeleyAutomation/AlphaGarden.