 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoDex: Learning Dexterous Manipulation from Large-Scale Egocentric Video
May 16, 2025Imitation learning for manipulation has a well-known data scarcity problem. Unlike natural language and 2D computer vision, there is no Internet-scale corpus of data for dexterous manipulation. One appealing option is egocentric human video, a passively scalable data source. However, existing large-scale datasets such as Ego4D do not have native hand pose annotations and do not focus on object manipulation. To this end, we use Apple Vision Pro to collect EgoDex: the largest and most diverse dataset of dexterous human manipulation to date. EgoDex has 829 hours of egocentric video with paired 3D hand and finger tracking data collected at the time of recording, where multiple calibrated cameras and on-device SLAM can be used to precisely track the pose of every joint of each hand. The dataset covers a wide range of diverse manipulation behaviors with everyday household objects in 194 different tabletop tasks ranging from tying shoelaces to folding laundry. Furthermore, we train and systematically evaluate imitation learning policies for hand trajectory prediction on the dataset, introducing metrics and benchmarks for measuring progress in this increasingly important area. By releasing this large-scale dataset, we hope to push the frontier of robotics, computer vision, and foundation models.
ARMADA: Augmented Reality for Robot Manipulation and Robot-Free Data Acquisition
Dec 14, 2024Teleoperation for robot imitation learning is bottlenecked by hardware availability. Can high-quality robot data be collected without a physical robot? We present a system for augmenting Apple Vision Pro with real-time virtual robot feedback. By providing users with an intuitive understanding of how their actions translate to robot motions, we enable the collection of natural barehanded human data that is compatible with the limitations of physical robot hardware. We conducted a user study with 15 participants demonstrating 3 different tasks each under 3 different feedback conditions and directly replayed the collected trajectories on physical robot hardware. Results suggest live robot feedback dramatically improves the quality of the collected data, suggesting a new avenue for scalable human data collection without access to robot hardware. Videos and more are available at https://nataliya.dev/armada.
IntervenGen: Interventional Data Generation for Robust and Data-Efficient Robot Imitation Learning
May 02, 2024Imitation learning is a promising paradigm for training robot control policies, but these policies can suffer from distribution shift, where the conditions at evaluation time differ from those in the training data. A popular approach for increasing policy robustness to distribution shift is interactive imitation learning (i.e., DAgger and variants), where a human operator provides corrective interventions during policy rollouts. However, collecting a sufficient amount of interventions to cover the distribution of policy mistakes can be burdensome for human operators. We propose IntervenGen (I-Gen), a novel data generation system that can autonomously produce a large set of corrective interventions with rich coverage of the state space from a small number of human interventions. We apply I-Gen to 4 simulated environments and 1 physical environment with object pose estimation error and show that it can increase policy robustness by up to 39x with only 10 human interventions. Videos and more results are available at https://sites.google.com/view/intervengen2024.
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Oct 17, 2023



Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. More details can be found on the project website $\href{https://robotics-transformer-x.github.io}{\text{robotics-transformer-x.github.io}}$.
FogROS2-SGC: A ROS2 Cloud Robotics Platform for Secure Global Connectivity
Jun 29, 2023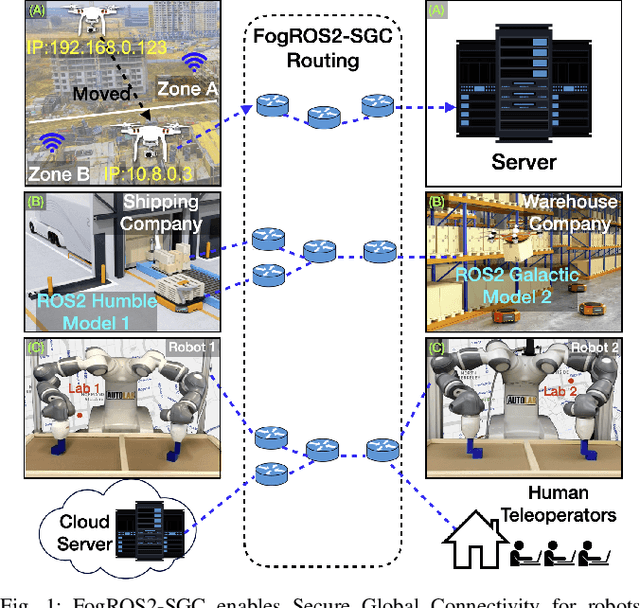

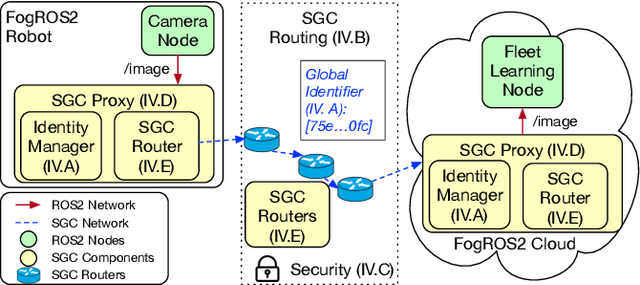
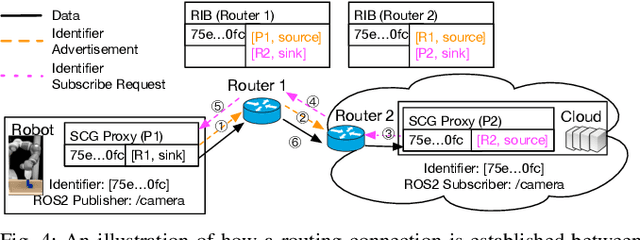
The Robot Operating System (ROS2) is the most widely used software platform for building robotics applications. FogROS2 extends ROS2 to allow robots to access cloud computing on demand. However, ROS2 and FogROS2 assume that all robots are locally connected and that each robot has full access and control of the other robots. With applications like distributed multi-robot systems, remote robot control, and mobile robots, robotics increasingly involves the global Internet and complex trust management. Existing approaches for connecting disjoint ROS2 networks lack key features such as security, compatibility, efficiency, and ease of use. We introduce FogROS2-SGC, an extension of FogROS2 that can effectively connect robot systems across different physical locations, networks, and Data Distribution Services (DDS). With globally unique and location-independent identifiers, FogROS2-SGC securely and efficiently routes data between robotics components around the globe. FogROS2-SGC is agnostic to the ROS2 distribution and configuration, is compatible with non-ROS2 software, and seamlessly extends existing ROS2 applications without any code modification. Experiments suggest FogROS2-SGC is 19x faster than rosbridge (a ROS2 package with comparable features, but lacking security). We also apply FogROS2-SGC to 4 robots and compute nodes that are 3600km apart. Videos and code are available on the project website https://sites.google.com/view/fogros2-sgc.
IIFL: Implicit Interactive Fleet Learning from Heterogeneous Human Supervisors
Jun 27, 2023



Imitation learning has been applied to a range of robotic tasks, but can struggle when (1) robots encounter edge cases that are not represented in the training data (distribution shift) or (2) the human demonstrations are heterogeneous: taking different paths around an obstacle, for instance (multimodality). Interactive fleet learning (IFL) mitigates distribution shift by allowing robots to access remote human teleoperators during task execution and learn from them over time, but is not equipped to handle multimodality. Recent work proposes Implicit Behavior Cloning (IBC), which is able to represent multimodal demonstrations using energy-based models (EBMs). In this work, we propose addressing both multimodality and distribution shift with Implicit Interactive Fleet Learning (IIFL), the first extension of implicit policies to interactive imitation learning (including the single-robot, single-human setting). IIFL quantifies uncertainty using a novel application of Jeffreys divergence to EBMs. While IIFL is more computationally expensive than explicit methods, results suggest that IIFL achieves 4.5x higher return on human effort in simulation experiments and an 80% higher success rate in a physical block pushing task over (Explicit) IFL, IBC, and other baselines when human supervision is heterogeneous.
From Occlusion to Insight: Object Search in Semantic Shelves using Large Language Models
Feb 24, 2023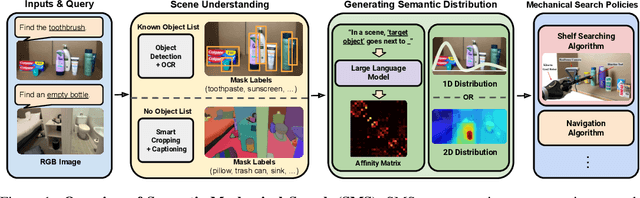
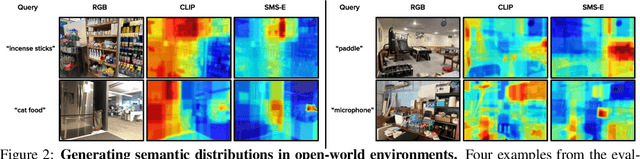

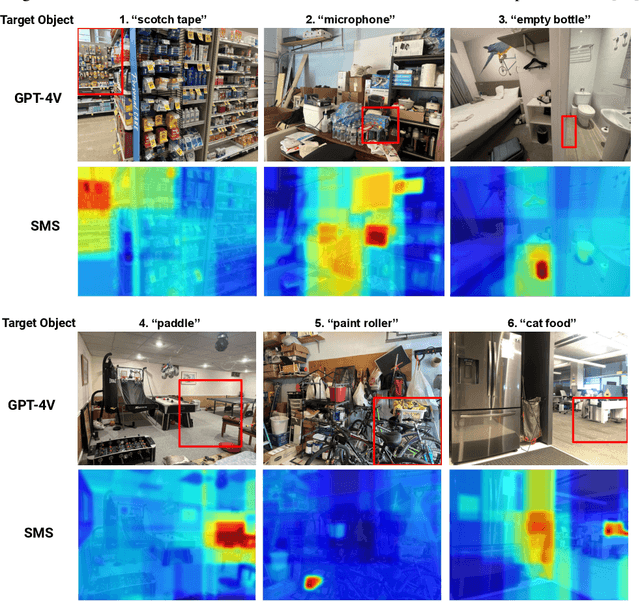
How can a robot efficiently extract a desired object from a shelf when it is fully occluded by other objects? Prior works propose geometric approaches for this problem but do not consider object semantics. Shelves in pharmacies, restaurant kitchens, and grocery stores are often organized such that semantically similar objects are placed close to one another. Can large language models (LLMs) serve as semantic knowledge sources to accelerate robotic mechanical search in semantically arranged environments? With Semantic Spatial Search on Shelves (S^4), we use LLMs to generate affinity matrices, where entries correspond to semantic likelihood of physical proximity between objects. We derive semantic spatial distributions by synthesizing semantics with learned geometric constraints. S^4 incorporates Optical Character Recognition (OCR) and semantic refinement with predictions from ViLD, an open-vocabulary object detection model. Simulation experiments suggest that semantic spatial search reduces the search time relative to pure spatial search by an average of 24% across three domains: pharmacy, kitchen, and office shelves. A manually collected dataset of 100 semantic scenes suggests that OCR and semantic refinement improve object detection accuracy by 35%. Lastly, physical experiments in a pharmacy shelf suggest 47.1% improvement over pure spatial search. Supplementary material can be found at https://sites.google.com/view/s4-rss/home.
Learning Self-Supervised Representations from Vision and Touch for Active Sliding Perception of Deformable Surfaces
Sep 26, 2022
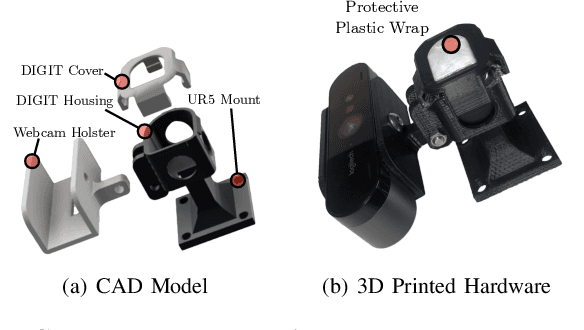


Humans make extensive use of vision and touch as complementary senses, with vision providing global information about the scene and touch measuring local information during manipulation without suffering from occlusions. In this work, we propose a novel framework for learning multi-task visuo-tactile representations in a self-supervised manner. We design a mechanism which enables a robot to autonomously collect spatially aligned visual and tactile data, a key property for downstream tasks. We then train visual and tactile encoders to embed these paired sensory inputs into a shared latent space using cross-modal contrastive loss. The learned representations are evaluated without fine-tuning on 5 perception and control tasks involving deformable surfaces: tactile classification, contact localization, anomaly detection (e.g., surgical phantom tumor palpation), tactile search from a visual query (e.g., garment feature localization under occlusion), and tactile servoing along cloth edges and cables. The learned representations achieve an 80% success rate on towel feature classification, a 73% average success rate on anomaly detection in surgical materials, a 100% average success rate on vision-guided tactile search, and 87.8% average servo distance along cables and garment seams. These results suggest the flexibility of the learned representations and pose a step toward task-agnostic visuo-tactile representation learning for robot control.
Learning Switching Criteria for Sim2Real Transfer of Robotic Fabric Manipulation Policies
Jul 02, 2022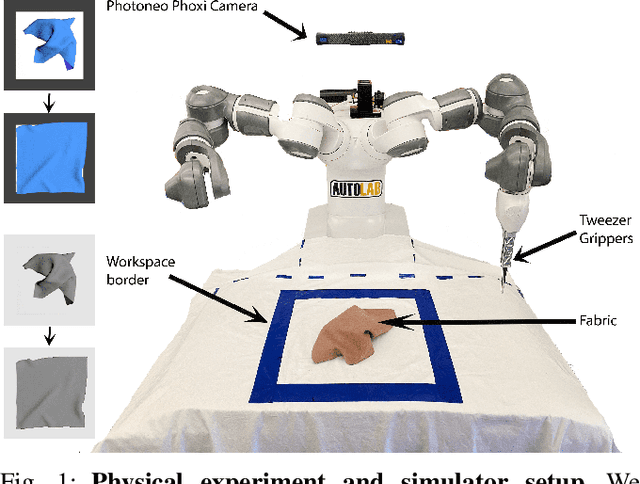
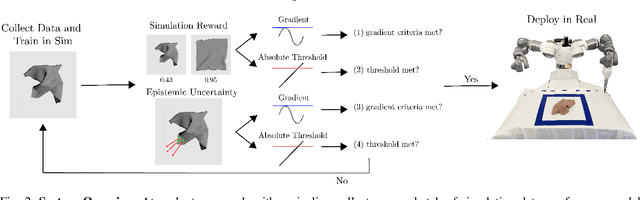

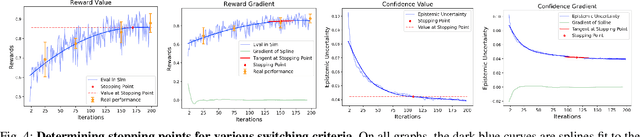
Simulation-to-reality transfer has emerged as a popular and highly successful method to train robotic control policies for a wide variety of tasks. However, it is often challenging to determine when policies trained in simulation are ready to be transferred to the physical world. Deploying policies that have been trained with very little simulation data can result in unreliable and dangerous behaviors on physical hardware. On the other hand, excessive training in simulation can cause policies to overfit to the visual appearance and dynamics of the simulator. In this work, we study strategies to automatically determine when policies trained in simulation can be reliably transferred to a physical robot. We specifically study these ideas in the context of robotic fabric manipulation, in which successful sim2real transfer is especially challenging due to the difficulties of precisely modeling the dynamics and visual appearance of fabric. Results in a fabric smoothing task suggest that our switching criteria correlate well with performance in real. In particular, our confidence-based switching criteria achieve average final fabric coverage of 87.2-93.7% within 55-60% of the total training budget. See https://tinyurl.com/lsc-case for code and supplemental materials.
Fleet-DAgger: Interactive Robot Fleet Learning with Scalable Human Supervision
Jun 29, 2022
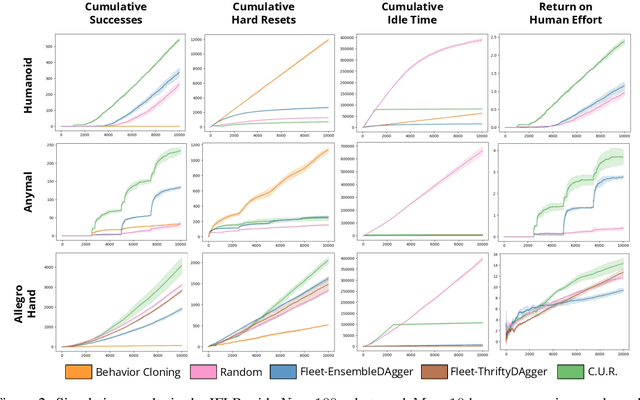
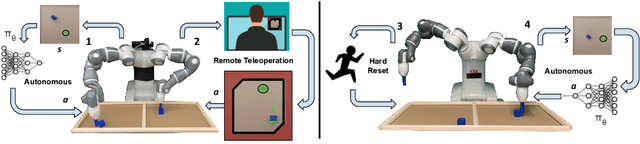
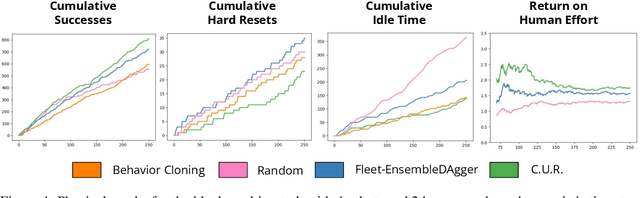
Commercial and industrial deployments of robot fleets often fall back on remote human teleoperators during execution when robots are at risk or unable to make task progress. With continual learning, interventions from the remote pool of humans can also be used to improve the robot fleet control policy over time. A central question is how to effectively allocate limited human attention to individual robots. Prior work addresses this in the single-robot, single-human setting. We formalize the Interactive Fleet Learning (IFL) setting, in which multiple robots interactively query and learn from multiple human supervisors. We present a fully implemented open-source IFL benchmark suite of GPU-accelerated Isaac Gym environments for the evaluation of IFL algorithms. We propose Fleet-DAgger, a family of IFL algorithms, and compare a novel Fleet-DAgger algorithm to 4 baselines in simulation. We also perform 1000 trials of a physical block-pushing experiment with 4 ABB YuMi robot arms. Experiments suggest that the allocation of humans to robots significantly affects robot fleet performance, and that our algorithm achieves up to 8.8x higher return on human effort than baselines. See https://tinyurl.com/fleet-dagger for code, videos, and supplemental material.