 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARMADA: Augmented Reality for Robot Manipulation and Robot-Free Data Acquisition
Dec 14, 2024Teleoperation for robot imitation learning is bottlenecked by hardware availability. Can high-quality robot data be collected without a physical robot? We present a system for augmenting Apple Vision Pro with real-time virtual robot feedback. By providing users with an intuitive understanding of how their actions translate to robot motions, we enable the collection of natural barehanded human data that is compatible with the limitations of physical robot hardware. We conducted a user study with 15 participants demonstrating 3 different tasks each under 3 different feedback conditions and directly replayed the collected trajectories on physical robot hardware. Results suggest live robot feedback dramatically improves the quality of the collected data, suggesting a new avenue for scalable human data collection without access to robot hardware. Videos and more are available at https://nataliya.dev/armada.
Pre-Trained Foundation Model representations to uncover Breathing patterns in Speech
Jul 17, 2024
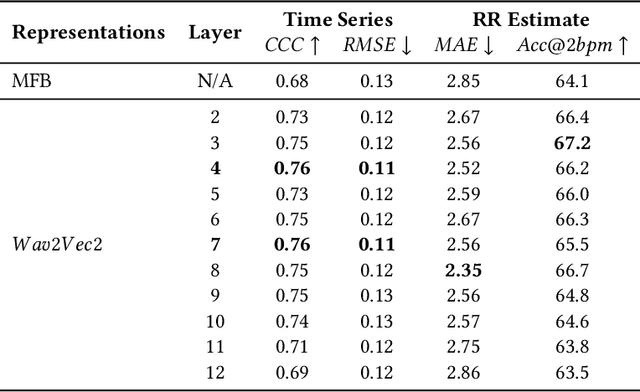

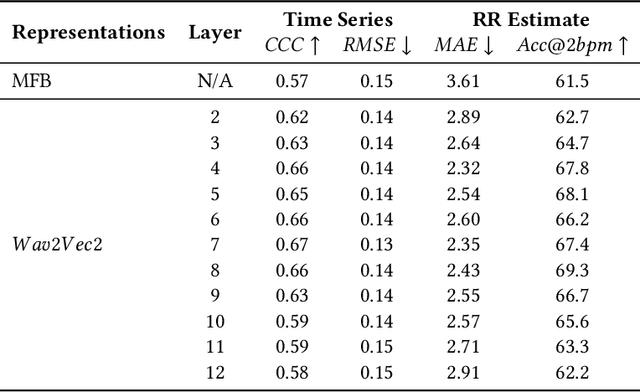
The process of human speech production involves coordinated respiratory action to elicit acoustic speech signals. Typically, speech is produced when air is forced from the lungs and is modulated by the vocal tract, where such actions are interspersed by moments of breathing in air (inhalation) to refill the lungs again. Respiratory rate (RR) is a vital metric that is used to assess the overall health, fitness, and general well-being of an individual. Existing approaches to measure RR (number of breaths one takes in a minute) are performed using specialized equipment or training. Studies have demonstrated that machine learning algorithms can be used to estimate RR using bio-sensor signals as input. Speech-based estimation of RR can offer an effective approach to measure the vital metric without requiring any specialized equipment or sensors. This work investigates a machine learning based approach to estimate RR from speech segments obtained from subjects speaking to a close-talking microphone device. Data were collected from N=26 individuals, where the groundtruth RR was obtained through commercial grade chest-belts and then manually corrected for any errors. A convolutional long-short term memory network (Conv-LSTM) is proposed to estimate respiration time-series data from the speech signal. We demonstrate that the use of pre-trained representations obtained from a foundation model, such as Wav2Vec2, can be used to estimate respiration-time-series with low root-mean-squared error and high correlation coefficient, when compared with the baseline. The model-driven time series can be used to estimate $RR$ with a low mean absolute error (MAE) ~ 1.6 breaths/min.