 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-Trained Foundation Model representations to uncover Breathing patterns in Speech
Jul 17, 2024
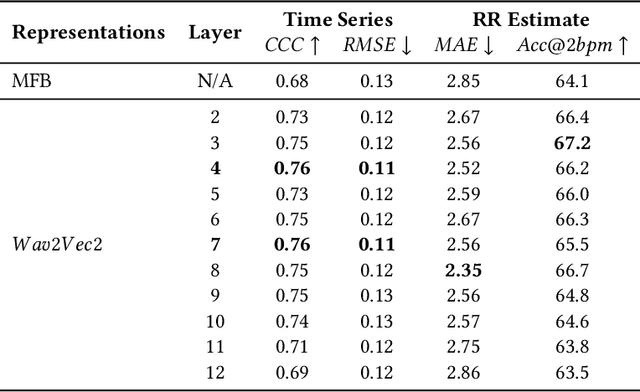

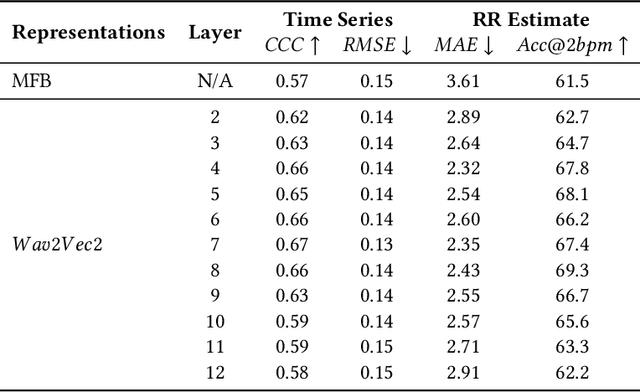
The process of human speech production involves coordinated respiratory action to elicit acoustic speech signals. Typically, speech is produced when air is forced from the lungs and is modulated by the vocal tract, where such actions are interspersed by moments of breathing in air (inhalation) to refill the lungs again. Respiratory rate (RR) is a vital metric that is used to assess the overall health, fitness, and general well-being of an individual. Existing approaches to measure RR (number of breaths one takes in a minute) are performed using specialized equipment or training. Studies have demonstrated that machine learning algorithms can be used to estimate RR using bio-sensor signals as input. Speech-based estimation of RR can offer an effective approach to measure the vital metric without requiring any specialized equipment or sensors. This work investigates a machine learning based approach to estimate RR from speech segments obtained from subjects speaking to a close-talking microphone device. Data were collected from N=26 individuals, where the groundtruth RR was obtained through commercial grade chest-belts and then manually corrected for any errors. A convolutional long-short term memory network (Conv-LSTM) is proposed to estimate respiration time-series data from the speech signal. We demonstrate that the use of pre-trained representations obtained from a foundation model, such as Wav2Vec2, can be used to estimate respiration-time-series with low root-mean-squared error and high correlation coefficient, when compared with the baseline. The model-driven time series can be used to estimate $RR$ with a low mean absolute error (MAE) ~ 1.6 breaths/min.
Modeling Images using Transformed Indian Buffet Processes
Jun 27, 2012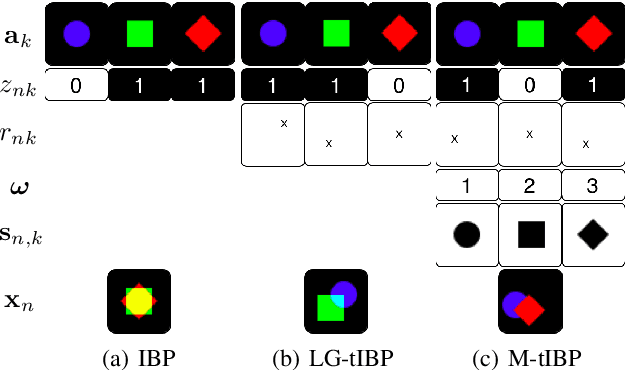
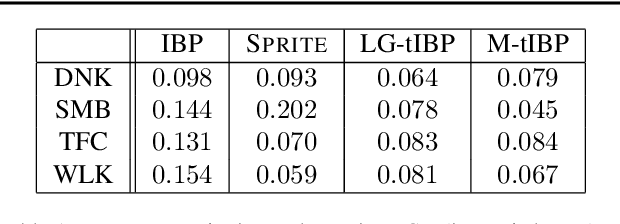
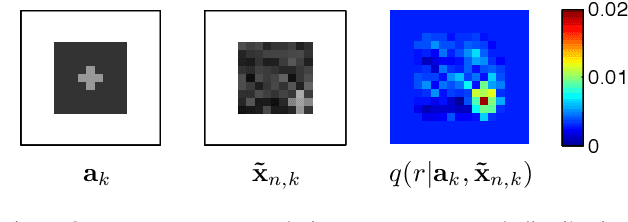

Latent feature models are attractive for image modeling, since images generally contain multiple objects. However, many latent feature models ignore that objects can appear at different locations or require pre-segmentation of images. While the transformed Indian buffet process (tIBP) provides a method for modeling transformation-invariant features in unsegmented binary images, its current form is inappropriate for real images because of its computational cost and modeling assumptions. We combine the tIBP with likelihoods appropriate for real images and develop an efficient inference, using the cross-correlation between images and features, that is theoretically and empirically faster than existing inference techniques. Our method discovers reasonable components and achieve effective image reconstruction in natural images.
Using Variational Inference and MapReduce to Scale Topic Modeling
Jul 19, 2011
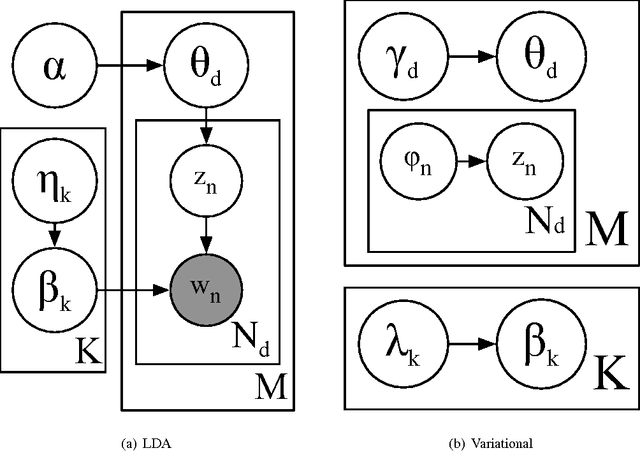
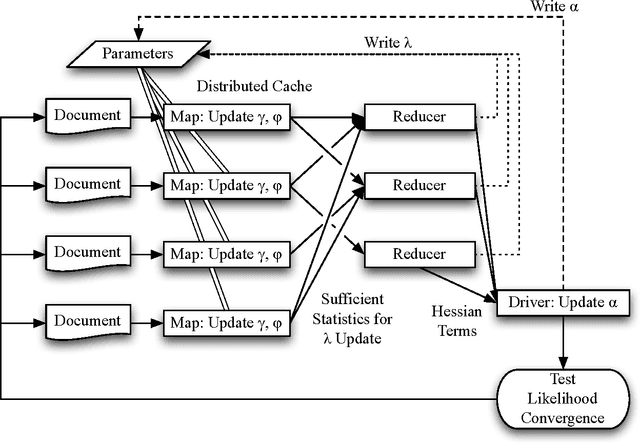
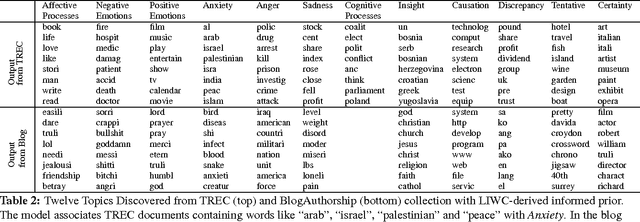
Latent Dirichlet Allocation (LDA) is a popular topic modeling technique for exploring document collections. Because of the increasing prevalence of large datasets, there is a need to improve the scalability of inference of LDA. In this paper, we propose a technique called ~\emph{MapReduce LDA} (Mr. LDA) to accommodate very large corpus collections in the MapReduce framework. In contrast to other techniques to scale inference for LDA, which use Gibbs sampling, we use variational inference. Our solution efficiently distributes computation and is relatively simple to implement. More importantly, this variational implementation, unlike highly tuned and specialized implementations, is easily extensible. We demonstrate two extensions of the model possible with this scalable framework: informed priors to guide topic discovery and modeling topics from a multilingual corpus.